Technical Guide: A Complete Guide to Supra’s Blockchain Technology Stack

ملخص
Supra integrates many of the innovations of the past few years into a powerful and high-performance architecture that fully vertically integrates MultiVM smart contract support and native services including price oracles, on-chain randomness, cross-chain communication, and automation capabilities.
On this basis, the paper details the end-to-end transaction process of the Supra blockchain and shows how to effectively mitigate the threat of censorship risks and maximum extractable value (MEV) attacks.
The Supra network provides a wide range of services and features based on a shared security platform. These include innovative technologies: Distributed Oracle Protocol (DORA), Distributed Verifiable Random Function (DVRF), automated networking with zero block latency, AppChain-inspired container architecture, multi-VM support, and optimized block execution through parallel transaction processing. In addition, Supras cross-chain design – HyperLoop and HyperNova – makes Supra the worlds first IntraLayer to achieve multi-chain interconnection through smart contract platform logic.
1. Native and fully vertically integrated blockchain services
Supra is committed to driving blockchain technology change through groundbreaking research and outstanding engineering capabilities. Its goal is to build an efficient Layer 1 blockchain that fully integrates various blockchain-related services to provide integrated solutions and a smooth user experience for individual users, institutional clients, and developers.
In this article, we will show how Supra technology interprets the famous saying of the ancient Greek philosopher Aristotle: The whole is greater than the sum of its parts. Adhering to the concept of full vertical integration, Supra provides a comprehensive set of blockchain functions and services to support rich ecosystem development and diverse application scenarios.
Core Features Overview
The native services provided by the Supra blockchain for dApps (as shown in Figure 1) include the following core functions:
-
Layer 1 Blockchain
-
Supports multiple asset types, including native tokens, programmable fungible and non-fungible tokens, and standardized cross-chain tokens.
-
Smart contract execution environment
-
Provides a variety of on-chain Turing-complete smart contract platforms suitable for various public blockchain applications such as DeFi protocols, blockchain games, lotteries, supply chain tracking, etc.
-
Off-chain data services
-
Provides demand-based (pull) and streaming (push) data services, including تشفيرcurrency price oracles, foreign exchange rates, stock indices, weather data, etc. These data are transmitted through Supras Distributed Oracle Protocol (DORA), serving not only the Supra blockchain, but also other blockchain networks.
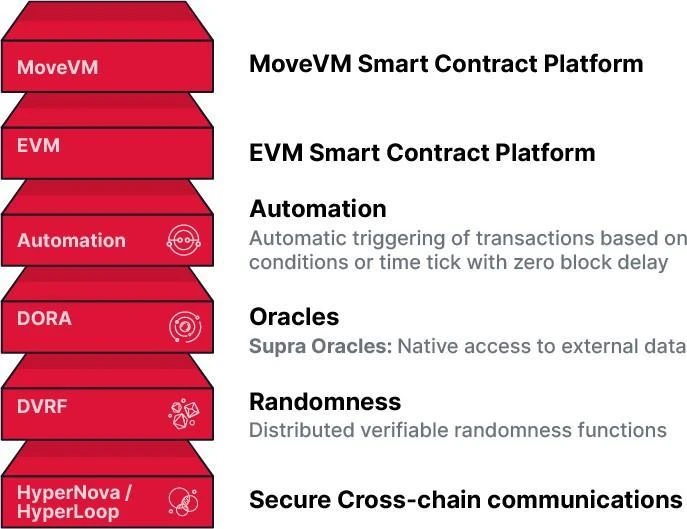
Figure 1 Fully vertically integrated
-
Push and pull on-chain random number service
Provides distributed verifiable random function (dVRF) in streaming and on-demand formats, suitable for Web 2.0 and Web 3.0 users for generating and distributing random number services. -
The Automation Network is used to schedule trade executions based on specific time points, on-chain events, or off-chain events provided by DORA. For example, a client might make a request: On June 1, 2025, at 12:00 EST, if the price of ETH is above $4,000, then sell my DOGE.
-
Application-specific chain (AppChain)
Containers on Supra offer the flexibility and autonomy of AppChain while significantly reducing deployment costs and benefiting from the high performance, shared security, and unified liquidity of the Supra network.
2. IntraLayer: Connecting Supra and other blockchains
Although Supra provides a range of native services, we are deeply aware of the reality and value of a multi-chain ecosystem. To improve interoperability, we designed a star topology (see Figure 2), in which Supras L1 blockchain and its integrated services serve as the core of the IntraLayer network, connecting other L1 and L2 blockchains through our interoperability solutions HyperLoop and HyperNova.
As an independent MultiVM smart contract platform, Supra not only provides its own services, but also aims to play a key role in the multi-chain ecosystem. This role is reflected in the exchange of value between networks or within the network, achieving secure and efficient communication through native smart contracts, automation functions and oracle services.
HyperLoop
Based on the traditional multi-signature cross-chain protocol, HyperLoop is a security solution that has been rigorously analyzed and verified by game theory. It is the first innovative design of its kind in the industry, ensuring the reliability of cross-chain transactions.
HyperNova
As a trustless interoperability solution, HyperNova provides high security for cross-chain communications, laying a solid foundation for information and value exchange in a multi-chain ecosystem.
Through HyperLoop and HyperNova, Supra has achieved extensive inter-chain interconnection, provided powerful tools for users and developers, and promoted the deep integration and development of the multi-chain ecosystem.
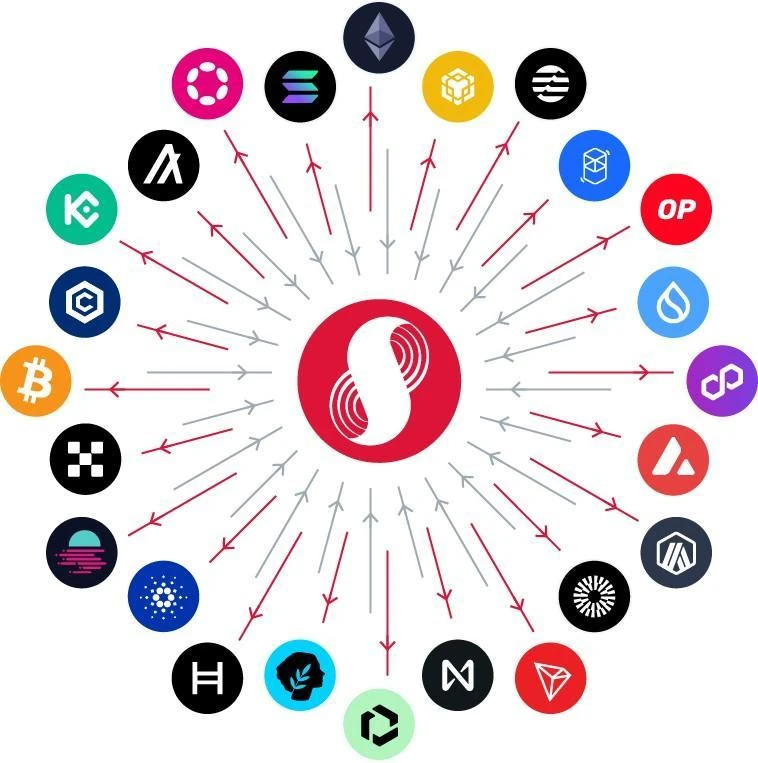
Figure 2 Supras IntraLayer
The security of the connected chains does not rely on the security assumptions of traditional cross-chain or relay nodes. Here we outline the specific scenarios where HyperLoop and HyperNova are most applicable.
-
HyperLoop
We found that the HyperLoop cross-chain solution is particularly suitable for connecting Optimistic Rollup to Supra because it eliminates the fraud proof challenge period required to achieve finality. -
HyperNova
Suitable for connecting any Proof-of-Stake (PoS) L1 blockchain to Supra as it maintains the security of the connected chain by recalculating the consensus of the Supra inter-chain, thereby maintaining L1-to-L1 security. Supras L1 blockchain is specifically designed to facilitate secure and efficient cross-chain communication.
Our plans include cross-chaining Bitcoin to Supra using HyperNova, while also enabling reverse connectivity via HyperLoop. Additionally, we are exploring how to implement atomic swaps in this environment to further enhance cross-chain interoperability.
The following are some of the core capabilities supported by the Supra IntraLayer technology stack:
-
DeFi IntraLayer
As a platform on top of a platform, Supra encapsulates a variety of mainstream DeFi protocols (such as AMM). dApp developers can easily access assets and information from multiple blockchains, simplifying the cross-chain development process. -
Cross-chain automation services
We allow users to set up automated tasks based on events and data from multiple blockchains, greatly improving user experience and operational efficiency.
We firmly believe that fully vertically integrating multiple native services into a high-performance L1 blockchain is highly consistent with our vision of building the worlds first cross-chain IntraLayer. As demand for our services grows on other blockchains, the utility of the Supra Network (including our tokens and on-chain assets) will bring natural fluctuations in value, further incentivizing users and customers to adopt our infrastructure.
At the same time, as the IntraLayer architecture is widely used in different ecosystems, more and more developers will be attracted by our native services and excellent performance, and then choose to develop and build applications directly on the Supra blockchain. This will not only enhance our DeFi layer, including our internally developed protocols and third-party protocols, but will also drive the overall adoption and attractiveness of the network.
We believe that with its excellent performance and one-stop, diversified services, Supra will bring the next wave of Web 3.0 technology popularization to the developer community and promote the rapid development of the entire ecosystem.
3. The core of Supra – Tribe and Clan node model
Supras basic philosophy is to be fully vertically integrated and provide almost all blockchain-related services on a single platform. This approach ensures that users and developers have a unified and smooth experience.
Fully vertically integrated vs modular Layer 2
Supra uses a vertically integrated architecture, which is different from the traditional modular L2 solution:
In L2, core functions (such as consensus, execution, and data availability) are scattered across independent networks. Although this design is called modularity advantage, it brings many problems:
-
Increased latency: Communication across networks causes time delays;
-
Decentralized economic security: Different networks have their own tokens and cannot share security;
-
High complexity: The overall architecture is more difficult to maintain and coordinate.
In contrast, Supra’s fully vertically integrated design unifies all components into a single blockchain:
-
Shared economic security and a unified token economy;
-
Significantly reduce communication delays and improve system performance;
-
Unified incentives enhance network security;
-
Reduced overall operating costs.
Byzantine Fault Tolerance Breakthrough
Distributed system research shows that in asynchronous or partially synchronous networks, traditional Byzantine Fault Tolerance (BFT) protocols can only tolerate up to one-third of nodes being malicious. However, Supras innovative breakthrough increases this tolerance to half, achieving unprecedented security and efficiency.
Sorting service and credit chain
The core of the Supra L1 blockchain is the sorting service, whose consensus protocol is responsible for transaction sorting, while the propagation of transaction data is separated from the sorting service. Therefore:
-
Blocks only contain metadata about transaction batches (such as summaries and data availability proofs), but not specific transaction data;
-
This makes the blocks of the Supra blockchain very small, greatly improving operational efficiency.
Since the ordering service is the core foundation for all other services, we call the Supra blockchain the “Chain of Integrity”.
Why is it important to tolerate more Byzantine nodes?
The immediate advantages of tolerating more Byzantine nodes are:
-
Smaller committees: For example, to tolerate 50 malicious nodes, the traditional method requires 151 members, while Supra only requires 101 members;
-
Lower costs: Reducing the number of consensus nodes means fewer nodes need to be compensated, thus reducing user fees;
-
Improved execution speed: With fewer consensus nodes, the process is faster while still maintaining strong security.
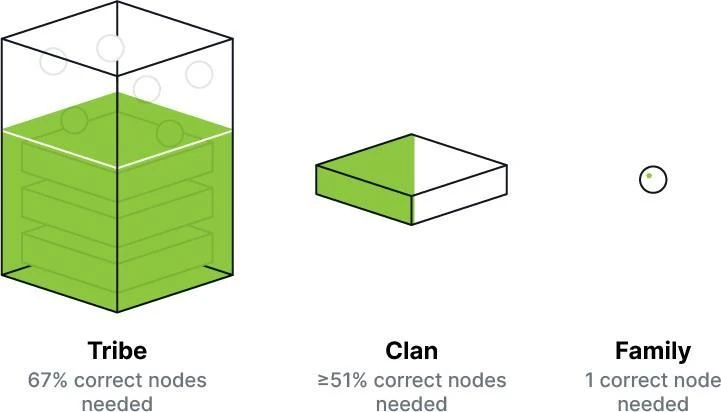
Figure 3 Tribe, clan and family
Tribe, clan and family
This core facilitates efficient full vertical integration of multiple services on the Supra blockchain. Supra proposes a new network framework that supports the execution of a variety of different algorithms at the tribe, clan or family level.
As shown in Figure 3:
-
A Tribe is a node committee that tolerates up to one-third of Byzantine nodes;
-
A Clan is a node committee that tolerates at most half of the Byzantine nodes.
-
A family is a committee of nodes that requires at least one correct node.
To achieve optimal performance and strong security, our network is architected as follows: Active nodes are organized into a tribe that runs a consensus protocol, provides support for ordering services, and tolerates up to one-third of Byzantine nodes.
A key point in our design is that the entire Supra tribe does not need to participate in transaction execution or maintain the full Supra state. Instead, a smaller subset – called a clan – manages the state, executes transactions, calculates the post-state of the block, and signs the state commitment. Therefore, the propagation of transaction data initially occurs only at the clan level, and then is broadcasted further.
This architecture is well suited for efficient state sharding, where different clans manage different state shards and may use independent virtual machines. This design improves scalability and allows us to adjust throughput by adding more clans (or shards). Therefore, all protocols except consensus (such as data propagation, shard execution, oracle service, and distributed random number service) run in small committees (clans) that only require a simple majority of correct nodes.
We organize the sorting tribe and multiple service clans together by randomly selecting nodes to assign them to clans, so that these clans actually constitute a partition of the tribe. Consensus or global sorting runs on the tribe, while various verifiable computation services are performed in the clan. This random selection of nodes allows us to perform at the clan level and introduce a probabilistic element to the system. For example, suppose the tribe consists of 625 nodes, of which at most 208 are Byzantine. If the tribe is divided into 5 clans of 125 nodes each, the probability that more than half (i.e. 62) of the nodes in any clan are Byzantine nodes is about 35 × 10 ⁻⁶. In other words, when the tribe has 33% Byzantine nodes, the probability of a bad clan is only 35 in a million. In practice, these probabilities are extremely low. We will further analyze these probabilities when discussing cycles and time periods, and show that they are almost negligible in practice.
4. Transaction Process
The Supra on-chain transaction process is roughly as follows, and the specific steps will be described in detail in subsequent chapters:
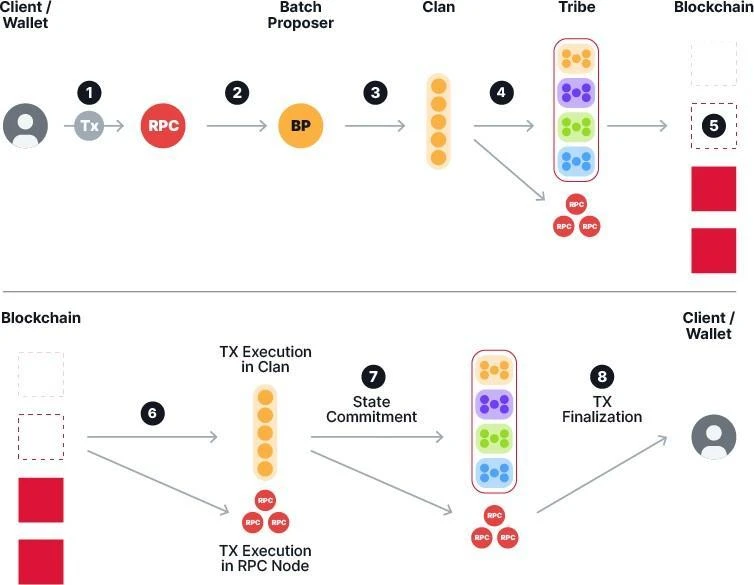
Figure 4 shows the end-to-end transaction flow in the Supra blockchain
-
The user submits a transaction ttt through Supra’s Starkey wallet [3] or dApp. The wallet connects to the gateway RPC node and the transaction ttt is sent to the node.
-
The Gateway RPC node sends the transaction to the primary bucket of a specific batch proposer based on basic verification and classification of the transaction ttt, and sends the transaction to the secondary bucket of some other batch proposers.
-
The batch proposer packages transactions from the primary bucket and adds timed-out transactions from the secondary bucket to the batch. See Section 5 for details.
-
Batches are propagated to the corresponding execution clan nodes via the xRBC protocol and must form a Data Availability Arbitration Certificate (DAQC) before they can be included in a block. These certificates are propagated throughout the clan and the batches are also propagated to the gateway RPC nodes.
-
Tribe nodes run Supras Moonshot consensus protocol. Block proposers build blocks by packaging these DAQCs and metadata of the associated batches.
-
The consensus protocol orders blocks, and thus indirectly orders transactions across batches. When blocks are finalized, they are visible to all tribe nodes running the consensus protocol, as well as nodes from all clans. Finalized blocks are also propagated to gateway RPC nodes.
-
Clan nodes execute the corresponding batch of transactions from the final block and update the blockchain state at the end of the current blockchain. They then compute the post-state, merkleize, and compute a new merkle root. Note that different clans execute different batches in parallel. Clan nodes sign the merkle root and propagate it to the entire tribe as well as the gateway RPC nodes.
-
The Gateway RPC node executes the block, computes the post-state and its Merkle root, verifies that it is consistent with the received signed Merkle root, and notifies the wallet when the transaction is complete.
Final confirmation stage
In our workflow, transaction ttt goes through the following three different finality stages, each providing stronger guarantees about the transaction’s status on the blockchain:
-
Pre-confirmation stage
When batch bbb containing transaction ttt obtains a Data Availability Arbitration Certificate (DAQC), it is guaranteed that transaction ttt will be included in the blockchain. At this stage, although the inclusion of the transaction is guaranteed, its specific location and execution results have not yet been determined. -
Sorting Finality
When the consensus protocol finalizes the block containing batch bbb, the position of transaction ttt in the blockchain becomes fixed and unchangeable, thus determining its execution order relative to other transactions. -
Execution Finality
This is the end of the finality phase. The clan node executes batch bbb, updates the blockchain state with the execution result of transaction ttt, creates a merkleized version of the new state, signs the resulting merkle root and broadcasts it to form a state commitment. Once this phase is complete, the execution result of the transaction is final and irreversible.
Supra L1 supports fast finality times. The observed times for these different finality stages in our experiments are reported in Section 7.
The following chapters will elaborate on the important steps in the above transaction process.
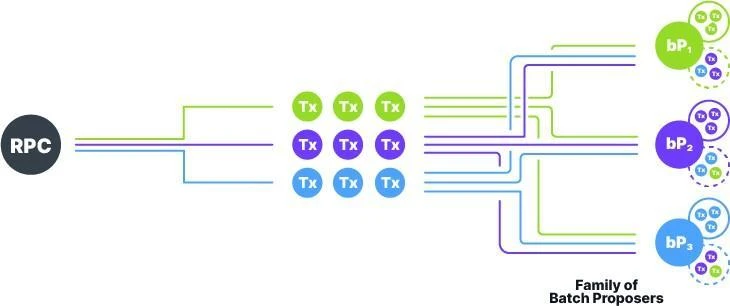
Figure 5 Bucketing without a memory pool
5. Bucketing without memory pool
We’ll start by discussing Ethereum and Solana’s existing memory pool protocols, and then show how Supra improves on them.
Ethereum memory pool solution
The traditional Ethereum memory pool protocol process is as follows:
-
The client (wallet) sends a transaction to the RPC node, which broadcasts the transaction through the Gossip protocol so that it reaches all consensus validators.
-
When a validator becomes a block proposer, it attempts to package the received transactions.
-
A block proposer may attempt to censor by not including transactions in the block, but since all consensus validators hold these transactions, the next validator who becomes a block proposer will include the omitted or censored transactions. Therefore, this protocol is censorship-resistant.
In a typical blockchain architecture, the client (Web3 wallet) sends transactions to a public RPC node. The RPC node then propagates the transaction to the entire RPC node network and consensus validator network through a peer-to-peer Gossip protocol. These nodes maintain a data structure called a mempool to temporarily store transactions sent by the client.
Next, the block builder extracts the transactions from the memory pool, packages them into blocks, and processes them through the consensus protocol. Once the block reaches finality, all transactions included in it are also considered finalized transactions.
Due to the large backlog of unprocessed transactions in the memory pool of Bitcoin and Ethereum, on average, transactions will stay in the memory pool for a long time before being selected by block builders. In addition, the peer-to-peer Gossip protocol will further increase the delay when propagating transactions.
Solana No Memory Pool Solution
To reduce memory pool latency, Solana uses a memory pool-less protocol that works as follows:
-
Block generation occurs on a fixed schedule, which is determined in advance by the block proposer.
-
The client (such as a wallet) sends the transaction to the RPC node, which attaches auxiliary data such as read and write access information to the transaction and sends it to some proposers who are about to propose the block. If a proposer misses the transaction, other proposers will include the transaction in the subsequent block.
It is important to note that the Solana network requires 32 block confirmations to achieve full finality. Although Solana is designed to optimize end-to-end latency, transaction duplication issues still occur occasionally and may cause network outages. Compared to Ethereums memory pool protocol, Solana uses directed communication to prospective block proposers, which effectively reduces the latency of transaction propagation.
Supra Memory Pool-Free Protocol Solution
Similar to Solana, Supra also uses a memory pool-less protocol, but we replace the traditional network-wide gossip protocol with targeted communication. However, Supra’s approach differs in two key ways:
1. Instant Finality
Unlike Solanas time slot-based system, Supra uses a classic Byzantine Fault Tolerance (BFT) PBFT-style consensus protocol called Moonshot (see below for details). In the Moonshot protocol, when a block receives a submission arbitration certificate (QC), it can achieve instant finality, without having to wait for 32 blocks to confirm like Solana. This greatly shortens the final confirmation time of transactions and improves system performance.
2. Batch metadata storage
In Supras consensus design, blocks do not contain transaction data directly, but store DAQC and metadata of transaction batches (see Section 6 for details). In our memory pool-free protocol, transactions from client wallets are placed in buckets managed by designated batch proposers, as shown in Figure 5.
The characteristics of our bucketing solution are as follows:
1) Deduplication mechanism
Each transaction is assigned a unique master batch proposer who is responsible for including the transaction in a batch. This single responsibility model naturally prevents duplicate transactions from being packaged into the blockchain.
2) Redundancy and censorship resistance
To ensure that transactions are not missed, we introduce secondary batch proposers as backup. If the primary batch proposer fails to include a transaction in time, the secondary batch proposer will include the transaction in the batch after a timeout.
-
Although multiple secondary proposers processing transactions simultaneously may result in duplicate packaging, the Supra system maintains consistency by the first appearance of the transaction.
-
Duplicate transactions will be automatically terminated during the execution phase due to invalid transaction sequence numbers and will not affect the on-chain status.
3) Unchangeable record of responsibility
If the secondary proposer successfully includes the transaction in the block, it will generate an unchangeable record proving that the primary proposer has failed to perform his duties. This record can be used for subsequent network analysis to punish batch proposers who censor transactions or cause unnecessary delays, ensuring the fairness and reliability of the system.
The specific process of the bucketing solution without a memory pool is as follows:
-
Each batch proposer maintains two buckets: primary bucket and secondary bucket.
-
For each transaction ttt, according to its unique and unpredictable identifier (hash value), the system assigns it to a specific batch proposer family. In this family, one node is designated as the primary batch proposer of transaction ttt, and the rest of the nodes are secondary batch proposers.
-
When the RPC node receives a transaction ttt from a wallet or dApp frontend, it forwards it to the corresponding batch proposer family based on the transaction identifier. The primary batch proposer stores the transaction ttt in its primary bucket, while the secondary batch proposers store the transaction ttt in their respective secondary buckets.
-
When building a new batch, a batch proposer must include all transactions in its primary bucket. To prevent Byzantine behavior (such as censoring specific transactions by excluding transactions from the primary bucket), secondary batch proposers act as a fallback mechanism.
-
When a batch is finalized and observed by the batch proposer, the proposer removes the transactions included in the batch from its primary and secondary buckets.
-
In addition, each transaction ttt has a configurable timeout. If ttt is not included in the finalized batch before the timeout, the secondary batch proposer in its family must include ttt in the batch from its secondary bucket when building the next batch. This mechanism ensures that transactions are not missed and enhances the systems anti-censorship capabilities.

Figure 6 Conceptual comparison with existing solutions
This two-layer design strikes a delicate balance between efficient deduplication and strong anti-censorship capabilities. In addition, when a secondary batch proposer successfully includes a transaction in a batch, an unchangeable record is generated, proving that the primary proposer failed to fulfill his or her duties. This record can be used for subsequent analysis and to impose corresponding penalties on batch proposers who censor transactions or cause unnecessary delays.
6. No memory pool architecture: efficient decoupling of transaction data propagation and transaction sorting
Next, we will introduce how Supra achieves efficient decoupling of transaction data propagation and transaction sorting through the tribe-clan architecture.
In recent years, some protocols (such as Narwhal/Tusk [11] and Bullshark [20]) have recognized the importance of transaction data transmission and adopted a new design paradigm to decouple data transmission from transaction ordering. This design implements data transmission and ordering respectively through two sub-protocols running in parallel:
-
In the absence of ordering requirements, data transmission is reduced to reliable broadcast (RBC), a fundamental operation that has been widely studied in distributed systems.
-
Specifically, nodes continuously propose and propagate new data blocks through the RBC subprotocol; subsequently, these data blocks are determined and output through the sorting subprotocol.
This design effectively optimizes the utilization of bandwidth resources and significantly improves the system throughput compared to traditional methods. Supra also follows this principle and decouples data transmission from transaction ordering. However, we observe that even in the most advanced consensus protocols, the focus of optimization is still mainly on the ordering sub-protocol, which is actually contrary to the actual bottleneck of the system.
For example, the main advantage of Tusk [11] and Bullshark [20] is the so-called zero-message ordering, which completely eliminates the communication overhead during the ordering phase. However, as we pointed out earlier, the main source of communication cost is not the ordering, but the data transmission.
Figure 6 compares our approach with existing solutions. Our goal is to reduce the amount of data transmitted by each node during the data transmission phase, especially to reduce the maximum transmission load of any single node. In practical applications, network bandwidth is often the main limiting factor of system throughput. Therefore, by optimizing the data transmission process, we can further improve the overall performance and efficiency of the system.
Supras xRBC Protocol
We significantly reduce the communication cost of data transmission through the following innovation: adopting an independent ordering service run by the same set of nodes.
In traditional methods, data transmission is usually performed through the reliable broadcast (RBC) protocol. RBC requires more than 2/3 honest nodes in the system to prevent the broadcaster from sending different batches of data to different nodes (i.e., the sender ambiguity problem).
However, we found that we can use an independent sorting service to improve the data transmission into a relaxed RBC operation, called xRBC. In xRBC, only more than 1/2 of the honest nodes are needed to complete the data transmission, which greatly reduces the communication cost.
Design advantages of xRBC
In xRBC, relying solely on participating nodes is not enough to completely prevent sender ambiguity. To solve this problem, the sorting service authenticates the broadcasters batches to ensure consensus among honest nodes, thereby eliminating disagreements. Although the sorting service still requires a supermajority (more than 2/3 of honest nodes), xRBC has significant advantages over traditional RBC in the following aspects:
-
Lower communication overhead: By reducing the reliance on a supermajority of honest nodes, the communication complexity of the protocol operation is reduced.
-
Improved performance: xRBC is designed to handle data transfers more efficiently while maintaining security comparable to traditional RBC.
Leveraging Clan Distributed Data Propagation
Since transactions are only executed within a clan (a random subcommittee of a tribe), transaction data only needs to be initially transmitted to the nodes executing that clan. This greatly reduces the network bandwidth load and is more efficient than propagating data to the entire tribe. Within each executing clan, we designate some nodes as batch proposers, who are responsible for building transaction batches from their respective buckets and transmitting them to all nodes in the clan.
It is worth mentioning that batch proposers from different clans can independently and in parallel propagate transaction batches without synchronizing or waiting for protocol steps. This parallel asynchronous propagation mechanism maximizes the utilization efficiency of network bandwidth when pushing data.
In addition, in order to achieve state synchronization (to facilitate node redistribution across cycles, see Section 9 for details), transaction data may be further propagated to the entire tribe in subsequent stages. This phased data propagation design ensures the consistency and flexibility of the system while ensuring network performance.
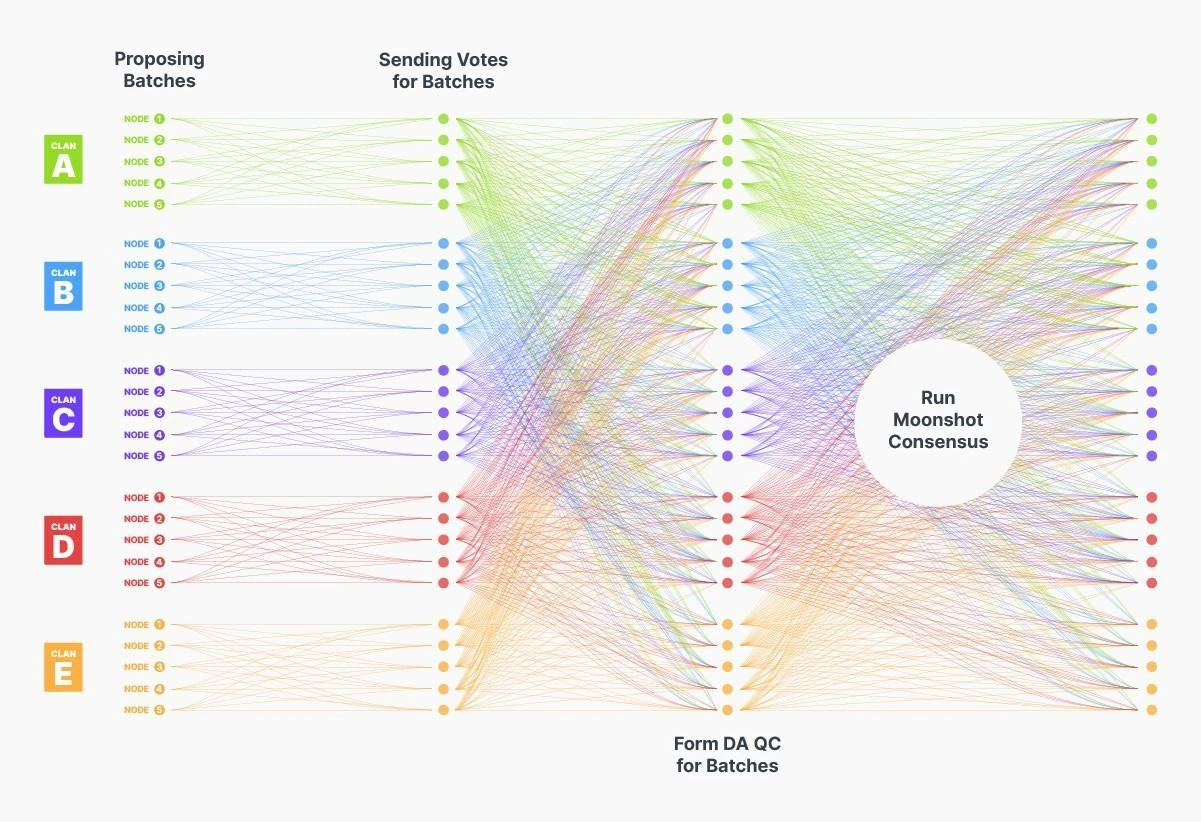
Figure 7 xRBC protocol
Specific process (Figure 7)
-
The batch proposer is responsible for building transaction batches and sending them to all nodes within the clan.
-
When a clan node receives a valid batch, it votes on the data availability of the batch and broadcasts the voting results to all nodes in the clan, other nodes in the tribe, and the designated gateway RPC node.
-
Once a simple majority vote is passed, the system generates a Data Availability Certificate (DAQC) to ensure that at least one honest node has complete transaction data.
-
If a node is missing part of a batch of data, it can request data from a simple majority of clan nodes, and DAQC guarantees that this request will be satisfied.
-
For batches exceeding the size threshold, or when not all clan nodes serve as batch proposers, we introduce erasure coding to ensure uniform distribution of data within the clan and optimize bandwidth usage efficiency.
Block Content and Finality
Only batch certificates are included in the block. When the validator (tribe node) of the consensus protocol acts as a block proposer, it packs all the batches of DAQC it receives into the block. Once the block reaches finality and is confirmed by the validator, the validator removes these included DAQC from the cache because they have been recorded in the finalized block and no longer need to be kept.
Since blocks only contain batch certificates and do not directly store transaction data, the Supra blockchain is actually an extremely lightweight blockchain. This design greatly reduces the size of blocks and improves data transmission efficiency.
7. Consensus Protocol
Byzantine Fault Tolerance (BFT) consensus protocol: the core of blockchain
The BFT consensus protocol is a core component of the blockchain, responsible for providing a standard ordering for blocks, thereby ensuring that transactions within a block also have a standard order. We innovatively designed a new BFT consensus protocol, called Moonshot SMR, which is inspired by the classic Practical Byzantine Fault Tolerance (PBFT) protocol and optimized for performance.
As mentioned above, the consensus protocol is executed in the tribe, while transaction execution is limited to the clan. Therefore, Moonshot adopts a flexible design that can be flexibly adapted according to the actual transaction throughput requirements. It is worth noting that the block does not directly contain transaction data, only batch certificates, which makes the system more efficient and lightweight.
Moonshot Performance
Moonshot achieved the following key performance indicators:
-
Continuous proposal delay (minimum delay between two block proposals): 1 message delay (md).
-
Submission delay: 3 md.
-
Cumulative delay in batch dissemination and data availability certificate generation: 2 md.
-
Since blocks are proposed every network hop, data availability certificates need to queue up for the next block proposal, with an average queuing delay of 0.5 md.
Therefore, the overall end-to-end latency of the system is 5.5 md.
Formal Verification: Ensuring Protocol Security
Distributed protocols often have complex behaviors and infinite state spaces, which makes it extremely challenging to prove their correctness. Formal verification is the gold standard for ensuring the security of protocols because it can mathematically prove that the protocol does not have errors.
To this end, we used Microsofts IvY validator to formally verify the security properties of the Moonshot consensus protocol, strictly proved its never-forking property, and provided mathematical guarantees for the correctness and security of the protocol.
Experimental Evaluation
We conducted an extensive evaluation on Google Cloud Platform (GCP), distributing the nodes evenly across five different regions:
-
us-east 1-b (South Carolina)
-
us-west 1-a (Oregon)
-
europe-north 1-a (Hamina, Finland)
-
asia-northeast 1-a(Tokyo)
-
australia-southeast 1-a (Sydney)
The experimental setup is as follows:
-
Clients and consensus nodes are co-located
-
Each transaction consists of 512 bytes of random data, and the batch size is set to 500 KB
-
Each experiment ran for 180 seconds
-
Latency measurement: Calculate the average time from when a transaction is generated to when it is committed by all non-faulty nodes to determine the end-to-end latency
-
Throughput measurement: evaluated based on the number of transactions finalized per second
The architecture we tested consisted of 300 nodes, divided into 5 clans, each containing 60 nodes (12 nodes deployed in each GCP region). In this configuration, the probability of a clan (60 nodes) failing due to internal dishonest majority in a 300-node network is 0.0107.
Nevertheless, our goal is not only to demonstrate the high performance of this architecture, but also to prove that it can maintain high throughput and low latency even in larger systems.
Hardware configuration:
-
We used e 2-standard-32 machines, each with 32 vCPUs, 128 GB of memory, and up to 16 Gbps of egress bandwidth.
Through these experiments, we verified the powerful capabilities of the Supra architecture in terms of performance and scalability.
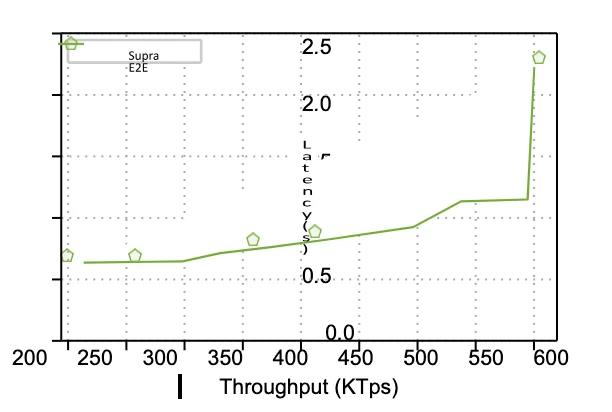
Figure 8 Throughput and end-to-end delay
We observed the relationship between the system throughput and end-to-end latency, as shown in Figure 8:
-
When the throughput reaches 500,000 TPS, the end-to-end latency remains under 1 second.
-
At 300,000 TPS, the latency is about 650 milliseconds, which is close to the theoretical limit of our architecture design.
Additionally, we measured the generation time of the Data Availability Certificate (DAQC), which was approximately 160 milliseconds.
In summary:
-
The pre-confirmation delay for transactions is about 160 milliseconds;
-
The sorting finality latency is less than 1 second.
DAG consensus protocol
Inspired by the research on DAG (directed acyclic graph) consensus protocols, we designed a new DAG consensus protocol called Sailfish. This protocol optimizes the commit latency to 1 reliable broadcast + 1 message delay (md) without sacrificing system throughput, surpassing the performance of the most advanced DAG consensus protocols.
In addition, we have developed a variant of Sailfish that combines it with the tribe-clan architecture to further improve system throughput. We are currently conducting extensive experimental testing on this design. If Sailfish outperforms the existing Moonshot protocol in a large-scale network environment, we plan to switch the core consensus protocol to Sailfish to achieve a more efficient consensus process.
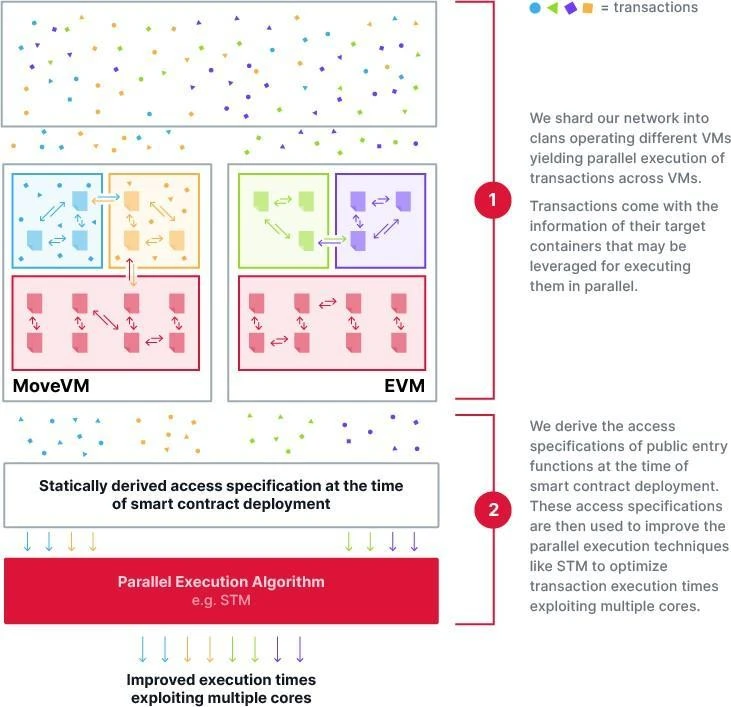
Figure 9 Supras parallel execution method
8. Execution
The current state of the blockchain contains all assets and their ownership information, as well as the latest data of all smart contracts. When executing a finalized block transaction, it is necessary to load the relevant state part, update the state according to the order of transactions in the block, and store the modified state persistently.
In modern blockchains, as transaction processing capabilities continue to improve, execution time has become an important factor that cannot be ignored in the end-to-end latency of transaction final confirmation. This trend is particularly evident in chains such as Solana, Sui, Aptos, and Monad, which effectively shorten latency by parallelizing execution.
Our tribe-clan architecture also implements parallel execution of transactions, but it is optimized at the network level. Specifically, the execution of transactions is limited to the clan, and different clans process their own transaction batches in parallel, which significantly improves the execution efficiency of the system (see Figure 9).
8.1 Parallel Execution of Transactions
In addition to achieving parallelism at the network level, we also conduct in-depth research on how to efficiently execute transactions in parallel by fully utilizing multi-core processors within a single node. Common parallel execution methods in the literature and industry can be divided into two categories:
-
Optimistic/speculative execution techniques
-
Predetermination technology based on deterministic dependencies
Software Transactional Memory (STM)
STM technology is widely used in the field of traditional computing for the parallel execution of multi-core programs. Aptos BlockSTM introduces STM technology into blockchain transaction execution. Its core idea is:
-
Optimistically execute transactions in parallel across all available cores;
-
Then verify if there are any dependency conflicts between transactions;
-
If a conflict is found, the conflicting transactions are re-executed through a cooperative scheduler.
Supra Innovation
We propose an innovative STM parallel execution algorithm that can efficiently resolve conflicts without a scheduler, unlike Aptos BlockSTM. This approach is comparable to BlockSTM in performance and architecture, and we are currently conducting an in-depth evaluation of this design to verify its advantages in practical applications.
Parallelization based on access specifications
Some blockchains achieve parallelization by specifying the access pattern of transactions:
-
Solana’s Sealevel requires transactions to explicitly state the accounts that need to be read and written.
-
Sui requires transactions to specify the objects to be read and written (via object identifiers) and to declare whether those objects are exclusive or shared.
-
Polygons approach is different. The block proposer uses BlockSTM technology to execute blocks, pre-calculate the dependencies between transactions, and include this dependency information in the block, allowing other validators to execute independent transactions in parallel.
However, it is important to note that either explicitly declaring access modes in transactions or including dependency information in blocks will significantly increase block size. This may lead to faster bandwidth saturation, thus limiting the maximum throughput that can be achieved by the system.
Drawing on these approaches, we are developing a deterministic parallel execution algorithm that statically analyzes smart contracts, automatically infers their access specifications when they are deployed, and stores these specifications in the blockchain state without requiring RPC nodes or wallets to explicitly provide access patterns. These specifications allow us to optimize the linear transaction order in the finalized block into a partial (relaxed) order, thereby enabling parallel execution of independent transactions. This approach not only reduces bandwidth usage, but also improves overall system throughput and efficiency.
Hybrid Approach
We believe that the hybrid approach of improving the STM algorithm by exploiting statically derived access specifications is the ultimate form of optimized execution technology (see Figure 9). We are currently conducting a comprehensive evaluation of this design.
8.2 Fairness of Execution Order
To ensure fairness in transaction ordering, we designed a two-step process:
-
Initial random ordering: The consensus protocol first generates an initial random seed ordering of transactions.
-
Final ordering: The final transaction order is derived through the on-chain random number protocol generated by the block-based BLS threshold signature, which determines the actual execution order of transactions.
This additional layer of randomization effectively mitigates Maximum Extractable Value (MEV) attacks, as batch proposers or block proposers can neither predict nor manipulate the final randomized transaction execution order.
To address the spam problem, we introduced a local fee market. In a disputed state, the cost of a transaction will increase exponentially, thereby improving the systems ability to resist interference while ensuring the efficiency and fairness of transaction sorting.
8.3 Multi-VM
Ethereum introduced EVM, a Turing-complete on-chain programming environment, which greatly unleashed the creativity of dApp development, especially providing strong support for DeFi applications. EVM drew on the experience of Web 2.0 programming languages and gave birth to Solidity. However, with the development of blockchain technology, the community gradually realized that a programming language designed specifically for asset transfer and on-chain asset management was needed. Therefore, Metas Diem team developed the Move language, which later spawned variants such as Aptos Move and Sui Move.
Supra deeply understands the importance of customized on-chain transaction programming languages, so it chose Move language as the first choice for our smart contract platform and will launch our L1 blockchain with the support of Move.
At the same time, we also see the huge potential of the multi-virtual machine ecosystem. Developers under different virtual machines can complement each other and jointly promote the innovation and development of the blockchain industry. Therefore, we designed an efficient multi-virtual machine architecture.
Based on the natural sharding characteristics of the tribe-clan architecture, each clan hosts a state shard, and different clans can host different virtual machines.
After integrating the Move smart contract platform, Supra will further expand to the Ethereum Virtual Machine (EVM) to achieve compatibility with the vast Ethereum ecosystem. Next, we will integrate the Solana Virtual Machine (SVM) to support developers to build smart contracts using widely used programming languages such as Rust, C, and C++.
Eventually, Supra will also support CosmWasm, enabling seamless connection with the active Cosmos ecosystem.
Inter-VM Communication
In a multi-VM environment, users may have multiple accounts on different VMs and want to transfer assets across VMs. In addition, Supra’s native token $SUPRA must be managed uniformly across all VMs. To solve this problem, we propose a simple and efficient three-step workflow:
-
Submit a cross-virtual machine transfer transaction. The user initiates a cross-virtual machine asset transfer transaction ttt. The transaction consists of two parts:
-
Source virtual machine deduction transaction tdt_dtd
-
Incoming transaction tct_ctc of the target virtual machine.
Transaction ttt is first executed on the source virtual machine, completing the deduction and triggering the corresponding event.
-
Event Monitoring and Submission A family is randomly selected from the clan of the source virtual machine (the family contains at least one honest node). These nodes monitor the deduction events and are responsible for submitting the incoming transaction tct_ctc.
-
Execute the target virtual machine accounting. The clan of the target virtual machine receives and executes tct_ctc to complete the asset accounting. At this point, the cross-virtual machine transfer process is completed.
9. Eras and Cycles
In Supras architecture, adding new nodes to a tribe or removing existing nodes is allowed only at the boundaries of an epoch. The duration of an epoch is configurable and is usually تحديned in terms of the number of blocks or actual time. We plan to set the length of an epoch to about a week. During each epoch, all nodes in the tribe perform sorting services by running the consensus protocol.
As shown in Figure 10, an epoch is further divided into multiple cycles, each of which typically lasts about one day. In each cycle, nodes in the tribe are randomly assigned to different clans through Supras VRF (Verifiable Random Function). For example:
-
In Epoch 1, Cycle 2 (e 1 c 2), a node may serve as a DORA validator;
-
Meanwhile, in epoch 1, cycle 3 (e 1 c 3), the same node may be tasked with executing EVM transactions.
This mechanism of randomly reassigning node roles every cycle significantly improves the security of the system and can effectively defend against attacks by malicious actors attempting to target specific roles or functions.

Figure 10 Era and week
An attacker attacking a specific service (for example, service SSS) may try to disrupt the service by disabling some nodes of the clan that provides service SSS.
To counter this threat, a distributed key generation (DKG) protocol is run every cycle to reorganize the clan. We are able to achieve such frequent reorganizations thanks to our innovation in the field of DKG – developing a high-performance class-group based DKG protocol.
The probability of a bad clan appearing
As described in Section 3, we analyze the security impact of partitioning a tribe of 625 nodes into 5 clans of 125 nodes each:
-
Definition of a bad clan: Byzantine nodes occupy a simple majority of a clan.
-
Probability of bad clan formation: The probability of a bad clan forming randomly is about 35 in a million.
Assuming each cycle is one day, and that clans reassign nodes every day through reorganization, this means that even in the most extreme case (33% of the nodes in the clan are controlled by Byzantine actors), the probability of a bad clan emerging is extremely low, and is expected to occur only once every 78 years.
This extremely low probability is almost negligible, which fully proves the reliability of our clan formation mechanism in providing strong security guarantees.
10. Container
Supra Container is an important feature designed for the developer community, which is inspired by the currently popular concept of Appchain.
We fully recognize the advantages of application chains, especially their unique value in providing sovereign capabilities to dApp developers and their communities. In addition, application chains can also support application-based business models. Currently, Layer 2, side chains, Polkadot parachains, Cosmos Zones, and Avalanche Subnets are the leading solutions in the application chain field.
However, we also realize that these solutions are not ideal in the context of high-throughput blockchains such as Supra L1. Application chains typically need to provide the following key functions:
-
Restricted deployment of smart contracts
-
Custom Gas رمز مميزس
-
Custom Gas Pricing
When these application chains are hosted on secondary chains (such as parachains, regional chains, subnets, etc.), their gas prices will not compete with the gas prices of the corresponding main chains (such as Polkadot relay chain, Cosmos Hub or Avalanche C-Chain), nor will they fluctuate with the gas prices of the main chains. This localized fee market provides users with a more predictable transaction fee experience, which is very ideal in practical applications.
Through the Supra container, we aim to combine the advantages of these application chains with the capabilities of high-performance L1 blockchains to create a more flexible and stable ecosystem for developers and users.
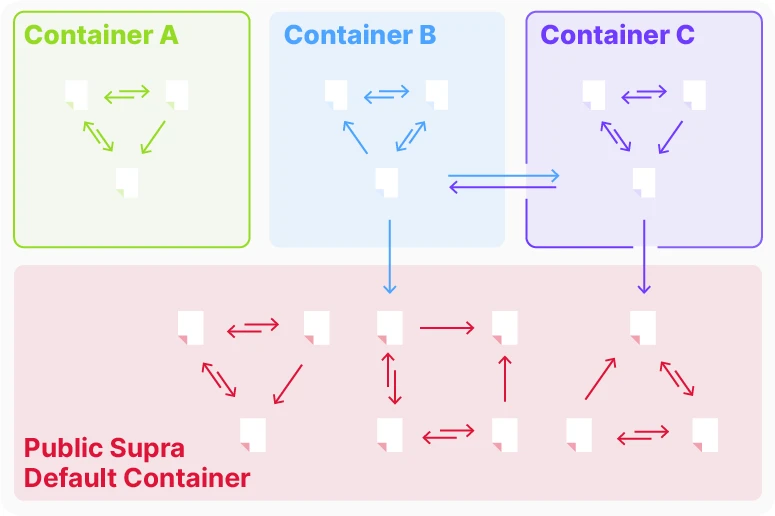
Figure 11 Container
Supra Container is a new concept in the blockchain space. We define it as a collection or bundle of smart contracts that serve a single or a group of related dApps. With Supra Container, we have optimized the Supra runtime framework to provide dApp developers with an Appchain-like experience, with the following notable features:
-
Custom Gas Tokens
-
Custom Gas Pricing
-
Restricted deployment of smart contracts
All of this can be achieved at a very low cost, completely eliminating the tedious process of launching a whole new secondary network (such as a validator network that requires staking incentives).
Solving the problem of liquidity fragmentation
More importantly, we overcome a major problem commonly faced by application chains – liquidity fragmentation – by supporting atomic composability of cross-container method calls. This design ensures efficient interaction between containers while retaining the centralization of liquidity.
Facilitating parallel execution
In the Ethereum EVM model, each smart contract has independent storage space. After introducing the Supra container into the EVM model, the blockchain state can be divided into multiple partitions:
-
Intra-container transactions access only the state of the target container without affecting the state of other containers.
-
This state isolation optimizes the execution time of transactions within a container and reduces conflicts between different containers.
Based on this feature, we built a simple and efficient work-sharing queue to optimize parallel execution. Through this design, the Supra container significantly improves the execution efficiency of the blockchain, simplifies the developer experience, and drives performance improvements for the entire ecosystem.
11. Conclusion
Supra is a fully vertically integrated IntraLayer, and its ambitious vision is taking shape after years of rigorous research. We have published a large number of research results in multiple top academic conferences, such as IEEE Security Privacy, Network and Distributed Security Symposium (NDSS), ACM Conference on Computer and Communications Security (CCS), etc. In addition, we have also released a series of white papers on core components, including:
-
Moonshot and Sailfish Consensus Protocol
-
Distributed Oracle Protocol (DORA)
-
Distributed Verifiable Random Function (DVRF)
-
Efficient group-based distributed key generation (DKG)
-
Supra Container
-
HyperLoop
-
HyperNova
Supra is the first full demonstration of our vision for a fully vertically integrated blockchain infrastructure stack that combines many innovative protocols developed over the years to create an extremely high-performance, all-in-one blockchain.
This article is sourced from the internet: Technical Guide: A Complete Guide to Supra’s Blockchain Technology Stack
Related: CoinW Research Institute Weekly Report (2024.12.02-2024.12.08)
Key Takeaways: The total market value of global cryptocurrencies is $3.84 trillion, up 5.2% from $3.63 trillion last week. The market value of Bitcoin is $1.98 trillion, accounting for 51.44%. The total market value of stablecoins is $204 billion, accounting for 5.32% of the total market value of cryptocurrencies. Among them, the market value of USDT is $138 billion, accounting for 67.6% of the total market value of stablecoins; followed by USDC with a market value of $41 billion, accounting for 20% of the total market value of stablecoins; and DAI with a market value of $5.37 billion, accounting for 2.6% of the total market value of stablecoins. This week, the total TVL of DeFi is 137.4 billion US dollars, an increase of 8.8% compared with last week. According to…







