Task
Ranking
已登录
Bee登录
Twitter 授权
TG 授权
Discord 授权
去签到
下一页
关闭
获取登录状态
My XP
0
Original author: jolestar (X: @jolestar )
I saw several friends talking about Based Rollup, most of them talked about it from the perspective of security. I would like to talk about my views on Based Booster Rollup from the perspective of the relationship between L1 and L2, and the construction of applications.
The idea of Based Rollup is actually very simple, that is, users directly submit L2 transactions to L1, which is sorted and packaged by L1. However, L1 does not verify the validity of transactions, but only guarantees the order and availability of transactions. L2 is a pure executor that executes L2 transactions packaged on L1. Does this look familiar to you? Isnt this the Inscription mode? Yes, the Indexer of the inscription can be understood as L2 here. I have said this in the article Is Inscription a Bug or a Feature?
Booster Rollup starts from another perspective. How to directly read the state of L1 through the contract on L2? The idea is not complicated. Since Based Rollup is already executing L2 transactions on L1, why not execute L1 transactions as well? In this way, the states of L1 and L2 are in a large state tree, and the L2 contract can directly read the state of L1.
So there are also projects that combine Based Rollup and Booster Rollup, called Based Booster Rollup (BBR), such as taiko.
From the time BBR was proposed to the time it has attracted market attention, the main background is the split problem brought about by the current mainstream L2 solution of Ethereum, the split between L1 and L2, and the split between L2. The functions provided by the current L2 solution, whether from the developers perspective or the users perspective, are not much different from an Alt-L1. Reading L1 data still depends on Oracle, assets still need a bridge, and wallets have to switch networks. This split also brings another problem. The binding between L1 and L2 is not that tight. L2 can add a set of consensus mechanisms at any time to become an Alt-L1, stand on its own, and make developers and users basically unaware. The current main binding relationship comes from EFs constraints on orthodoxy: L2 must use L1 as DA, but obviously this constraint is not reliable.
So if we replace all current L2 solutions with Based Rollup solutions, will the problem be solved? I guess Optimism and Arbitrum will jump out and say, isn’t it easy to switch to Based Rollup? The main L2 solutions now have Force Inclusion mechanisms. L2 directly removes the Sequencer and allows users to send transactions to L1 through Force Inclusion. Isn’t Based Rollup implemented?
But can this solve the fragmentation problem? No. Although Arb and Op both submit transactions to L1 in real time, and L1 packages and sorts them, they are still fragmented because each only recognizes its own transactions. At this point, everyone should understand that the key to solving the fragmentation problem for Based Rollup is to have transactions or data that can be shared between L2, and this data format requires:
It must be a format تحديned on L1 that is independent of the platform and implementation. Different L2 accounts and virtual machines are different, and their transactions cannot be directly shared.
It requires consensus among L2s and support from multiple L2s.
Therefore, it must be a protocol first, designing a public protocol and data format first, only storing the data required by the protocol on the chain, executing and verifying off the chain, and implementing support solutions for different L2s. But it is actually quite difficult to achieve these two points. First of all, developers in the Ethereum ecosystem generally design protocols through smart contracts, and do not have the habit of designing protocols directly based on data formats. The main attempt in this direction was Ethscriptions when the inscriptions were popular last time. The second point is even more difficult, and it requires practice and time to verify.
After talking about the issue of data sharing, lets talk about the user experience. Obviously, if all transactions are sent directly to L1 by users, the experience is almost the same as using L1, whether it is Gas or confirmation time. So some people began to design a pre-confirmation protocol for Based Rollup, but if the pre-confirmation protocol can really work, all transactions need to pass the pre-confirmation protocol first, then isnt it a Sequencer? Is this a waste of time to talk about this?
This contradiction arises because people confuse several types of transactions:
Transactions submitted directly by users to L1 and executed and verified by L1 are L1 transactions.
The user submits directly to L1, but L1 does not directly verify and execute. The data transaction of the shared protocol between L2 can be called L1.5 transaction.
The user directly submits the transaction to the L2 Sequencer, which is pre-confirmed and executed by the Sequencer, a dedicated transaction of a certain L2.
Based Rollup is only related to 1 and 2. 3 is the current working method of Sequencer Rollup. The two can be combined.
Suppose there is such a Rollup solution:
The Sequencer automatically synchronizes all L1 (including L1.5) transactions and executes them in the order given by L1.
The Sequencer receives L2 transactions at the same time, sorts them together with L1 transactions, and executes them.
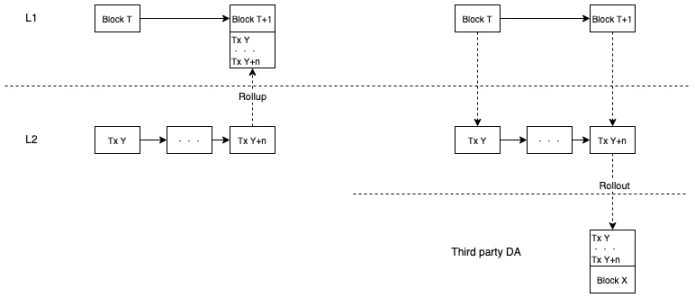
Through 1, it implements Based and Booster, and through 2, it realizes fast confirmation of L2 transactions without sacrificing user experience. According to the previous naming scheme, this should be called BBSR (Based Booster Sequencer Rollup), but it is a bit long and not easy to understand, so I call it Stackable L2. As the name suggests, L2 is stacked on L1, and L2 contains all transactions and states of L1. This is the solution of @RoochNetwork .
If the above solution is adopted, it will be a bit strange for L2 to package its own transactions and submit them to L1 again, because L2 will read the L1 transactions that package its own transactions and re-execute them, which is a bit like its own output also becomes its own input. Therefore, Roochs solution is Rollout instead of Rollup. Because in the long run, L1s block space is very precious, and multiple L2 transactions occupying L1s space is a rolling mode. L1s space should be left for L1 and L1.5 transactions. L2 application-level transactions should seek cheaper block space and expand new block space through rolling out, which is also conducive to the development of the entire industry ecosystem.
The previous descriptions are all from the perspective of Ethereum. As Rooch is Bitcoin’s first BBSR or Stackable L2 practice, let’s talk about the differences in the Bitcoin ecosystem.
There is no Turing-complete smart contract on Bitcoin L2, which becomes an advantage in the Based Rollup mode. Because Based Rollup does not need L1 to execute and verify transactions, it only needs to ensure Permission Less and DA. This also forced projects in the Bitcoin ecosystem to design protocols based on data structures from a long time ago. Whether it is colored coins, or later RGB, Taproot Assets, Ordinals Inscription, Atomicals, Runs, etc., they are all attempts in this category and can be included in the broad concept of CSV (Client-side Validation) protocol. Their transactions are typical L1.5 transactions. If projects in the Ethereum ecosystem want to practice Based L2 and design a protocol shared between multiple L2s, it will be roughly the same as the above protocol.
Let’s take Rooch as an example to explain the working mode of BBSR on Bitcoin:
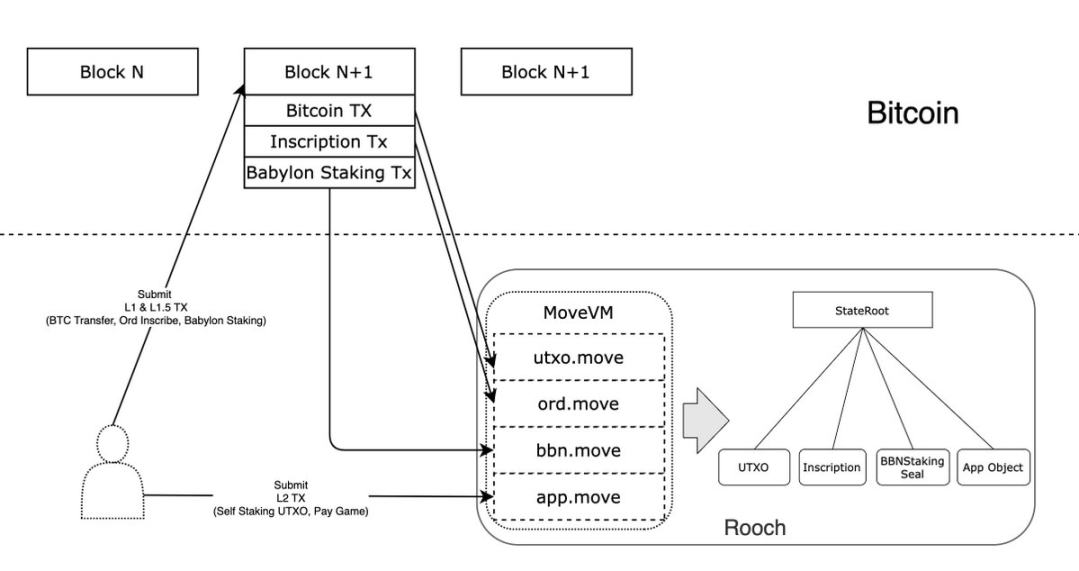
Users will directly submit L1 and L1.5 transactions to Bitcoin. Since the protocol is public, the entry point can be any application.
Rooch will synchronize all L1 transactions, process the UTXOs in them, and find out whether there are additional protocol information, and then use the corresponding Move module to process it. For example, transactions identified as Inscription will be processed by the ord module, while Babylon Staking transactions will be processed by the bbn module.
Users directly submit L2 transactions to Roochs Sequencer node for processing. The execution results of the above three transactions will generate a complete state tree, and the application contract can make full use of the states generated by L1 and L1.5 transactions.
Applications in this mode can design two types of transactions, one is the public protocol transaction (Based part, on L1), and the other is the application transaction (sequenced by Sequencer). The two can cooperate with each other through the Booster mode to ensure Permission Less while also ensuring user experience.
As mentioned earlier, the design of public protocols requires time and practice to verify and reach consensus, and Rooch can provide such a convenient experimental environment: if you want to design a new application or asset protocol on Bitcoin, you only need to define the protocol format, and then deploy a corresponding Move contract module to process it, and then you can experiment by constructing application scenarios.
Of course, the Bitcoin ecosystem also faces some challenges along this route:
When Bitcoin was first designed, it did not leave enough room for expansion for this DA scenario. Therefore, how to write data to Bitcoin was one of the directions that various protocols have tried to explore, such as embedding data in OP_RETURN, through Witness, and even through signatures. Currently, there is still a lack of standardized solutions.
The Bitcoin ecosystem has not reached a broad consensus on the value of embedded data on the chain. This is what I have been calling for since the last inscription craze. The Bitcoin ecosystem should attach importance to the value of Bitcoin as a global public data bus.
Since the DeFi summer, the entire Crypto field has been exploring new applications beyond DeFi. Whether it is the Bitcoin inscription craze or the recent Based Rollup hot discussion, it can be understood as a rediscovery of the value of L1 as a data bus. From the perspective of distributed systems, the decoupling between systems can be achieved through the data bus, and the decoupling between systems is one of the key prerequisites for achieving permission less. For example, the decentralized exchange in the Crypto ecosystem has made full use of the blockchain as a Data Bus to achieve decentralized docking, which is difficult to achieve directly in the traditional financial system. If you want to support more complex applications, you only need to upgrade simple transfer transactions to application protocol transactions to achieve application-level permission less, and this method is the least invasive to existing applications.
This article mainly discusses BBR from the perspective of ecology and application. The security of the BBR mode and the interoperability of the L1, L1.5, and L2 states under the BBR mode will be discussed in detail in later articles. Some related links are attached at the end, including my historical articles and the explanations of Based Rollup from different perspectives by Twitter friends.
Related Links:
1. Stackable L2 — A new blockchain expansion solution https://rooch.network/zh-CN/blog/stackable-l2
2. How should Bitcoins Layer 2 be done? https://x.com/jolestar/status/1717358817992995120 I designed the initial plan based on how L2 uses the state and data on Bitcoin L1. A friend mentioned the Booster solution in the comments, and finally adopted the Booster solution in practice.
3. Is the inscription a bug or a feature? https://x.com/jolestar/status/1732711942563959185 This article explains the value of inscriptions from the perspective of how L2 is constructed, including the incentive compatibility problem between L1 and L2.
4. Discussion on Based Rollup from the perspective of subtraction theory @kerne l1 983 https://web3 caff.com/zh/archives/108241
5. @jason_chen 998’s article on Based Rollup https://x.com/jason_chen998/status/1799692331635048697
6. Based Rollup Track Research Report https://research.web3 caff.com/zh/archives/22719
This article is sourced from the internet: In-depth analysis of Based Booster Rollup: background, practice and prospects
Related: PayFi’s secure passwords in the payment revolution guard the core of Web3 finance
This article Hash (SHA 1): 8656ff83d95af1de9dab2b925597cf72c6f63c66 No.: Lianyuan Security Knowledge No.032 With the continuous development of blockchain technology, the financial industry is undergoing an unprecedented transformation. In this context, an emerging concept has gradually emerged: PayFi (Payment Finance). This term was first proposed by Lily Liu, Chairman of the Solana Foundation, at the 2024 EthCC conference to explore an innovative payment and financial model. PayFis vision is not only a payment system based on تشفيرcurrency, but also hopes to provide users with safer, faster, and lower-cost financial services through decentralized technology combined with the time value of currency. 1. PayFi’s core concept: the time value of money and decentralized finance What is PayFi Lily Liu mentioned that the core motivation of PayFi is to realize the original vision of Bitcoin…













