My XP
0
Login
Original title: Glue and coprocessor architectures
المؤلف الأصلي: فيتاليك بوتيرين، مؤسس إيثريوم
الترجمة الأصلية: دينج تونج، جولدن فاينانس
Special thanks to Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra, and various Flashbots contributors for their feedback and comments.
If you analyze in even moderate detail any resource-intensive computation going on in the modern world, one thing you’ll find again and again is that computation can be broken down into two parts:
A relatively small amount of complex but computationally inexpensive business logic
A lot of intensive but highly structured “expensive work”.
These two forms of computing are best handled differently: the former, whose architectures may be less efficient but need to be very general; the latter, whose architectures may be less general but need to be very efficient.
First, let’s take a look at the environment I’m most familiar with: the Ethereum Virtual Machine (EVM). Here’s a geth debug trace of a recent Ethereum transaction I made: updating the IPFS hash of my blog on ENS. The transaction consumed a total of 46924 gas, which can be broken down as follows:
Basic cost: 21,000
Call data: 1,556 EVM
Execution: 24,368 SLOAD
Opcode: 6,400 SSTORE
Opcode: 10, 100 LOG
Opcode: 2, 149
Others: 6,719
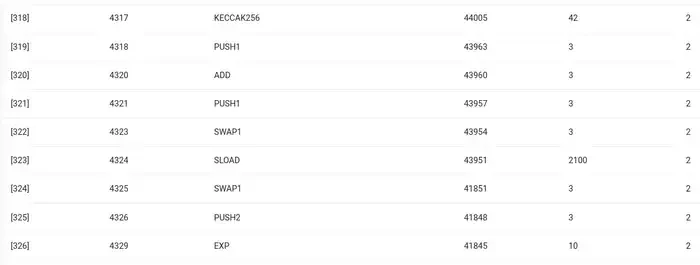
EVM trace of ENS hash updates. The second to last column is the gas cost.
The moral of the story is this: the bulk of execution (~73% if you look at just the EVM, ~85% if you include the base cost portion covering compute) is concentrated in a very small number of structured expensive operations: storage reads and writes, logging, and cryptography (base cost includes 3000 for payment signature verification, and the EVM includes an additional 272 for payment hashing). The rest of the execution is business logic: swapping bits of calldata to extract the ID of the record Im trying to set and the hash Im setting it to, etc. In a token transfer this would include adding and subtracting balances, in more advanced applications this might include loops, etc.
In the EVM, these two forms of execution are handled differently. High-level business logic is written in a higher-level language, typically Solidity, which compiles to the EVM. Expensive work is still triggered by EVM opcodes (SLOAD, etc.), but more than 99% of the actual computation is done in dedicated modules written directly inside client code (or even libraries).
To reinforce our understanding of this pattern, let’s explore it in another context: AI code written in Python using torch.

Forward pass of one block of the Transformer model
What do we see here? We see a relatively small amount of “business logic” written in Python, which describes the structure of the operations being performed. In a real application, there would be another type of business logic that determines details such as how to get inputs and what operations to perform on the outputs. However, if we drill down into each individual operation itself (the individual steps inside self.norm, torch.cat, +, *, self.attn, …), we see vectorized computation: the same operation computes a large number of values in parallel. Similar to the first example, a small portion of the computation is used for business logic, and the majority of the computation is used to perform large structured matrix and vector operations – in fact, most of them are just matrix multiplications.
Just like in the EVM example, these two types of work are handled in two different ways. High-level business logic code is written in Python, a highly general and flexible language, but also very slow, and we just accept the inefficiency because it only involves a small part of the total computational cost. At the same time, intensive operations are written in highly optimized code, usually CUDA code that runs on GPUs. Increasingly, we are even starting to see LLM inference being done on ASICs.
Modern programmable cryptography, like SNARKs, again follows a similar pattern on two levels. First, the prover can be written in a high-level language where the heavy lifting is done with vectorized operations, just like the AI example above. My circular STARK code here demonstrates this. Second, the programs executed inside the cryptography itself can be written in a way that is divided between common business logic and highly structured expensive work.
To understand how this works, we can look at one of the latest trends in STARK proofs. To be general and easy to use, teams are increasingly building STARK provers for widely adopted minimal virtual machines, such as RISC-V. Any program that needs to have its execution proven can be compiled into RISC-V, and then the prover can prove the RISC-V execution of that code.
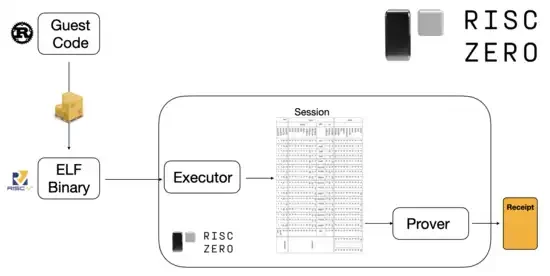
Diagram from the RiscZero documentation
This is very convenient: it means we only have to write the proof logic once, and from then on any program that needs a proof can be written in any traditional programming language (RiskZero supports Rust, for example). However, there is a problem: this approach incurs a lot of overhead. Programmable crypto is already very expensive; adding the overhead of running code in a RISC-V interpreter is too much. So, the developers came up with a trick: identify the specific expensive operations that make up the majority of the computation (usually hashing and signing), and then create specialized modules to prove those operations very efficiently. Then you just combine the inefficient but general RISC-V proof system with the efficient but specialized proof system, and you get the best of both worlds.
Programmable cryptography beyond ZK-SNARKs, such as multi-party computation (MPC) and fully homomorphic encryption (FHE), may be optimized using similar approaches.
Modern computing increasingly follows what I call a glue and coprocessor architecture: you have some central glue component, which is high generality but low efficiency, that is responsible for passing data between one or more coprocessor components, which are low generality but high efficiency.

This is a simplification: in practice, the trade-off curve between efficiency and generality almost always has more than two levels. GPUs and other chips, often called “coprocessors” in the industry, are less general than CPUs, but more general than ASICs. The trade-offs in terms of degree of specialization are complex, and depend on predictions and intuitions about which parts of an algorithm will remain the same in five years, and which parts will change in six months. We often see similar multiple levels of specialization in ZK proof architectures. But for a broad mental model, it’s sufficient to consider two levels. There are similar situations in many areas of computing:
From the above examples, it certainly seems like a natural law that computing can be split in this way. In fact, you can find examples of computing specialization going back decades. However, I think this separation is increasing. I think there are reasons for this:
We have only recently reached the limits of CPU clock speed increases, so further gains can only be made through parallelization. However, parallelization is difficult to reason about, so it is often more practical for developers to continue to reason about sequentially and let parallelization happen in the backend, wrapped in dedicated modules built for specific operations.
Computation has only recently become so fast that the computational cost of business logic has become truly negligible. In this world, it also makes sense to optimize the VM where the business logic runs for goals other than computational efficiency: developer friendliness, familiarity, security, and other similar goals. In the meantime, dedicated coprocessor modules can continue to be designed for efficiency and gain their security and developer friendliness from their relatively simple interface to the binder.
Its becoming increasingly clear what the most important expensive operations are. This is most evident in cryptography, where specific types of expensive operations are most likely to be used: modular operations, elliptic curve linear combinations (aka multi-scalar multiplication), fast Fourier transforms, and so on. This is also becoming increasingly clear in AI, where for more than two decades most computation has been mostly matrix multiplication (albeit at varying levels of precision). Similar trends are emerging in other fields. There are far fewer unknown unknowns in (compute-intensive) computations than there were 20 years ago.
A key point is that the glue should be optimized to be a good glue, and the coprocessor should be optimized to be a good coprocessor. We can explore the implications of this in a few key areas.
Blockchain virtual machines (such as the EVM) do not need to be efficient, just familiar. With the addition of the right coprocessors (aka precompilation), computations in an inefficient VM can actually be just as efficient as computations in a native, efficient VM. For example, the overhead incurred by the EVMs 256-bit registers is relatively small, while the benefits of the EVMs familiarity and existing developer ecosystem are large and lasting. Development teams optimizing the EVM have even found that lack of parallelization is not generally a major barrier to scalability.
The best ways to improve the EVM might just be (i) adding better precompiled or specialized opcodes, e.g. some combination of EVM-MAX and SIMD might be reasonable, and (ii) improving storage layout, e.g. changes to Verkle trees greatly reduce the cost of accessing storage slots that are adjacent to each other as a side effect.
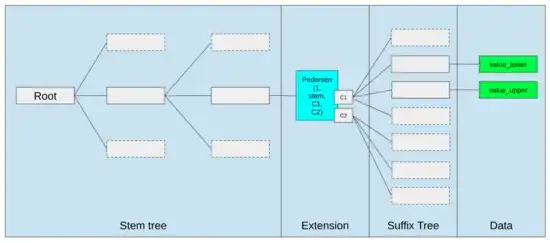
Storage optimizations in Ethereum’s Verkle tree proposal put adjacent storage keys together and adjust gas costs to reflect this. Optimizations like this, combined with better precompiles, may be more important than tweaking the EVM itself.
One of the big challenges in improving the security of modern computing at the hardware level is its overly complex and proprietary nature: Chips are designed to be efficient, which requires proprietary optimizations. Backdoors are easy to hide, and side-channel vulnerabilities are constantly being discovered.
Efforts to push for more open, more secure alternatives continue from multiple angles. Some computing is increasingly done in trusted execution environments, including on users’ phones, which has improved security for users. The push for more open source consumer hardware continues, with some recent wins, such as RISC-V laptops running Ubuntu.

RISC-V laptop running Debian
However, efficiency remains an issue. The author of the above linked article writes:
Newer open-source chip designs like RISC-V can’t possibly compete with processor technology that’s been around and improved over decades. Progress always has to start somewhere.
More paranoid ideas, like this design of building a RISC-V computer on an FPGA, face even greater overhead. But what if glue and coprocessor architectures mean that this overhead doesn’t actually matter? What if we accept that open and secure chips will be slower than proprietary chips, even giving up common optimizations like speculative execution and branch prediction if necessary, but try to make up for this by adding (proprietary if necessary) ASIC modules that are used for the specific types of computation that are most intensive? Sensitive computations could be done in the “main chip”, which would be optimized for security, open source design, and side-channel resistance. More intensive computations (e.g. ZK proofs, AI) would be done in ASIC modules, which would know less information about the computations being performed (potentially, through cryptographic blinding, or even zero information in some cases).
Another key point is that all of this is very optimistic about cryptography, and especially programmable cryptography, going mainstream. We’ve already seen super-optimized implementations of certain specific highly structured computations in SNARK, MPC, and other settings: some hash functions are only a few hundred times more expensive than running the computation directly, and AI (mainly matrix multiplication) has very low overhead as well. Further improvements such as GKR may reduce this further. Fully general VM execution, especially when executed in a RISC-V interpreter, will probably continue to have an overhead of about ten thousand times, but for the reasons described in this paper this doesn’t matter: as long as the most intensive parts of the computation are handled separately using efficient, specialized techniques, the total overhead is manageable.
Simplified diagram of a dedicated MPC for matrix multiplication, the largest component in AI model inference. See this article for more details, including how models and inputs are kept private.
One exception to the idea that the glue layer only needs to be familiar, not efficient, is latency, and to a lesser extent data bandwidth. If the computation involves heavy operations on the same data dozens of times over (as in cryptography and AI), then any latency caused by an inefficient glue layer can become a major bottleneck in runtime. Therefore, the glue layer also has efficiency requirements, although these are more specific.
Overall, I think the trends described above are very positive developments from multiple perspectives. First, it’s a reasonable approach to maximizing computational efficiency while remaining developer-friendly, and being able to get more of both is good for everyone. In particular, by enabling specialization on the client side to improve efficiency, it improves our ability to run sensitive and performance-demanding computations (e.g., ZK proofs, LLM reasoning) locally on user hardware. Second, it creates a huge window of opportunity to ensure that the pursuit of efficiency does not compromise other values, most notably security, openness, and simplicity: side-channel security and openness in computer hardware, reduced circuit complexity in ZK-SNARKs, and reduced complexity in virtual machines. Historically, the pursuit of efficiency has caused these other factors to take a back seat. With glue and coprocessor architectures, it no longer needs to. One part of the machine optimizes for efficiency, and another part optimizes for generality and other values, and the two work together.
This trend is also very good for cryptography, because cryptography itself is a prime example of expensive structured computation, and this trend accelerates it. This adds another opportunity for improved security. In the blockchain world, improved security is also possible: we can worry less about optimizing the virtual machine and focus more on optimizing precompilation and other features that coexist with the virtual machine.
Third, this trend opens up opportunities for smaller, newer players to participate. If computation becomes less monolithic and more modular, this greatly lowers the barrier to entry. Even ASICs that use one type of computation have the potential to make a difference. This is also true in the area of ZK proofs and EVM optimizations. It becomes easier and more accessible to write code with near-leading-edge efficiency. It becomes easier and more accessible to audit and formally verify such code. Finally, because these very different areas of computation are converging on some common patterns, there is more room for collaboration and learning between them.
This article is sourced from the internet: Vitaliks new article: Glue and co-processor architecture, a new idea to improve efficiency and security
ذات صلة: ابتكار تكنولوجي أم سرد مبالغ فيه؟ نظرة على النظام البيئي المبكر لعملة البيتكوين الكسرية
المؤلف الأصلي: shaofaye 123، Foresight News لقد اتخذ فريق UniSat إجراءً مرة أخرى. لقد أثار Fractal Bitcoin طفرة في السوق، وتجاوز عدد عناوين المحفظة على شبكة الاختبار 10 ملايين. ارتفعت Pizza وSats واحدة تلو الأخرى. هل هي نقطة الانفجار التالية لنظام Bitcoin البيئي أم BSV 2.0؟ يتعايش FUD وFOMO، والشبكة الرئيسية على وشك الإصدار. ستأخذك هذه المقالة إلى نظرة عامة على البيئة المبكرة لـ Fractal Bitcoin. حول Fractal Bitcoin Fractal Bitcoin هو حل آخر لتوسيع Bitcoin طوره فريق UniSat. من خلال استخدام كود BTC الأساسي، فإنه يبتكر طبقة توسع لا نهائية على السلسلة الرئيسية لتحسين قدرات معالجة المعاملات والسرعة، مع التوافق التام مع نظام Bitcoin البيئي الحالي. إنه ...













