My XP
0
تسجيل الدخول
So far, this round of crypto bull market cycle is the most boring one in terms of business innovation. It lacks phenomenal hot tracks such as DeFi, NFT, and Gamefi in the previous bull market, resulting in a lack of industry hotspots in the overall market, and the growth of users, industry investment, and developers is relatively weak.
This is also reflected in the current asset prices. Throughout the entire cycle, the exchange rates of most Alt coins against BTC continue to lose money, including ETH. After all, the valuation of smart contract platforms is determined by the prosperity of applications. When the development and innovation of applications are lackluster, the valuation of public chains is also difficult to increase.
As a relatively new crypto business category in this round, AI has benefited from the explosive development speed and continuous hot spots in the external business world, and it is still likely to bring a good increase in attention to AI track projects in the crypto world.
في the IO.NET report released by the author in April, the necessity of combining AI and Crypto was sorted out. That is, the advantages of crypto-economic solutions in certainty, mobilizing and allocating resources, and trustlessness may be one of the solutions to the three challenges of AI randomness, resource intensity, and difficulty in distinguishing between humans and machines.
In the AI track of the crypto economy, the author attempts to discuss and deduce some important issues through another article, including:
What other narratives are budding in the crypto Ai track that may explode in the future?
The catalytic paths and logic of these narratives
Narrative-related project goals
Risk and uncertainty in narrative deduction
This article is the author’s interim thinking up to the time of publication. It may change in the future, and the views are highly subjective. There may also be errors in facts, data, and reasoning logic. Please do not use it as an investment reference. Criticism and discussion from colleagues are welcome.
The following is the main text.
Before we formally review the next wave of narratives in the crypto AI track, let’s first look at the main narratives of the current crypto AI. From the perspective of market capitalization, the ones with a market capitalization of more than 1 billion US dollars are:
Computing power: Render (RNDR, market value of 3.85 billion), Akash (market value of 1.2 billion), IO.NET (the latest round of primary financing valuation of 1 billion)
Algorithmic Network: Bittensor (TAO, market value of 2.97 billion)
AI agent: Fetchai (FET, pre-merger market value 2.1 billion)
*Data time: 2024.5.24, currency unit is US dollars.
In addition to the above fields, which AI track will have the next single project market value exceeding 1 billion?
The author believes that it can be speculated from two perspectives: the narrative of the industry supply side and the narrative of the GPT moment.
From the perspective of industry supply, the four driving forces behind the development of AI are:
Algorithms: High-quality algorithms can perform training and inference tasks more efficiently
Computing power: Both model training and model reasoning require GPU hardware to provide computing power, which is also the main bottleneck of the industry. The shortage of chips in the industry has led to high prices for mid- and high-end chips.
Energy: The data computing centers required by AI consume a lot of energy. In addition to the power required by the GPU itself to perform computing tasks, a lot of energy is also required to handle GPU heat dissipation. The cooling system of a large data center accounts for about 40% of the total energy consumption.
Data: Improving the performance of large models requires expanding training parameters, which means a large amount of high-quality data is needed.
Regarding the driving forces of the above four industries, the algorithm and computing power tracks both have crypto projects with a market capitalization of more than 1 billion US dollars, while the energy and data tracks have not yet seen projects of the same market value.
In fact, the supply shortage of energy and data may soon come, becoming a new wave of industry hotspots, thereby driving a boom in crypto-related projects.
Let’s talk about energy first.
On February 29, 2024, Musk said at the Bosch Connected World 2024 Conference: I predicted the chip shortage more than a year ago. The next shortage will be electricity. I think there will not be enough electricity to run all the chips next year.
From the specific data, the Human-Centered Artificial Intelligence Institute at Stanford University, led by Fei-Fei Li, publishes the AI Index Report every year. In the report on the AI industry in 2021 released by the team in 2022, the research team estimated that the scale of AI energy consumption in that year only accounted for 0.9% of the global electricity demand, and the pressure on energy and the environment was limited. In 2023, the International Energy Agency (IEA) summarized the year 2022 as follows: global data centers consumed about 460 terawatt hours (TWh) of electricity, accounting for 2% of global electricity demand, and predicted that by 2026, the global data center energy consumption will be at least 620 TWh and at most 1,050 TWh.
In fact, the IEAs estimate is still conservative, because there are already a large number of AI-related projects about to be launched, and the corresponding energy demand scale far exceeds its imagination 23 years ago.
For example, Microsoft and OpenAI are planning the Stargate project. The project is expected to start in 2028 and be completed around 2030. The project plans to build a supercomputer with millions of dedicated AI chips to provide OpenAI with unprecedented computing power to support its research and development in artificial intelligence, especially large language models. The project is expected to cost more than $100 billion, which is 100 times more than the current large data center cost.
The energy consumption of the Stargate project alone is as high as 50 terawatt hours.
That’s why Sam Altman, founder of OpenAI, said at the Davos Forum in January this year: “Artificial intelligence will require energy breakthroughs in the future, because the electricity consumed by artificial intelligence will far exceed people’s expectations.”
After computing power and energy, the next area of shortage in the rapidly growing AI industry is likely to be data.
In other words, the shortage of high-quality data required for AI has become a reality.
At present, humans have basically figured out the law of growth of large language model capabilities from the evolution of GPT – that is, by expanding model parameters and training data, the models capabilities can be improved exponentially – and there is no technical bottleneck in this process in the short term.
But the problem is that high-quality and public data may become increasingly scarce in the future, and AI products may face the same supply and demand contradiction in data as chips and energy.
The first is the increase in disputes over data ownership.
On December 27, 2023, The New York Times formally sued OpenAI and Microsoft in the U.S. Federal District Court, accusing them of using millions of its articles without permission to train the GPT model, and demanding that they billions of dollars in statutory and actual damages for illegal copying and use of works of unique value and destroy all models and training data containing The New York Times copyrighted materials.
Later in late March, the New York Times published a new statement, targeting not only OpenAI, but also Google and Meta. The New York Times said in the statement that OpenAI transcribed the speech parts of a large number of YouTube videos through a speech recognition tool called Whisper, and then generated text as text to train GPT-4. The New York Times said that it is now very common for large companies to use petty theft when training AI models, and said that Google is also doing this. They also convert YouTube video content into text for the training of their own large models, which essentially infringes on the rights of video content creators.
The New York Times vs. OpenAI is the first AI copyright case. Considering the complexity of the case and its far-reaching impact on the future of content and the AI industry, it may not be possible to reach a conclusion soon. One possible outcome is that the two parties settle out of court, with Microsoft and OpenAI, who have deep pockets, paying a large amount of compensation. However, more data copyright frictions in the future are bound to raise the overall cost of high-quality data.
In addition, as the worlds largest search engine, Google has also revealed that it is considering charging for its own search function, but the target of the charges is not the general public, but AI companies.
Source: Reuters
Googles search engine servers store a large amount of content, and it can even be said that Google stores all the content that has appeared on Internet pages since the 21st century. Currently, AI-driven search products, such as Perplexity overseas and Kimi and Mita in China, process these searched data through AI and then output them to users. The charges for AI by search engines will inevitably increase the cost of obtaining data.
In fact, in addition to public data, AI giants are also eyeing non-public internal data.

Photobucket is a long-established photo and video hosting website that had 70 million users and nearly half of the U.S. online photo market share in the early 2000s. With the rise of social media, the number of Photobucket users has dropped significantly, and there are only 2 million active users left (they have to pay a high fee of $399 per year). According to the agreement and privacy policy signed by users when registering, accounts that have not been used for more than a year will be recycled, and Photobucket also supports the right to use the pictures and video data uploaded by users. Photobucket CEO Ted Leonard revealed that the 1.3 billion photos and video data it owns are extremely valuable for training generative AI models. He is negotiating with several technology companies to sell this data, with quotes ranging from 5 cents to $1 per photo and more than $1 per video. He estimates that the data that Photobucket can provide is worth more than $1 billion.
EPOCH, a research team focusing on the development trend of artificial intelligence, has published a report on the data required for machine learning , Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning , based on the use of data and the generation of new data in machine learning in 2022, taking into account the growth of computing resources. The report concludes that high-quality text data will be exhausted between February 2023 and 2026, and image data will be exhausted between 2030 and 2060. If the efficiency of data utilization cannot be significantly improved or new data sources emerge, the current trend of large-scale machine learning models that rely on massive data sets may slow down.
Judging from the current situation where AI giants are purchasing data at high prices, free high-quality text data has basically been exhausted. EPOCHs prediction two years ago was relatively accurate.
At the same time, solutions to the demand for “AI data shortage” are also emerging, namely: AI data provision services.
Defined.ai is a company that provides customized, real, high-quality data to AI companies.

Examples of data types that Defined.ai can provide: https://www.defined.ai/datasets
Its business model is: AI companies provide Defined.ai with their own data needs. For example, in terms of pictures, the quality needs to be above a certain resolution, avoid blur, overexposure, and the content needs to be authentic. In terms of content, AI companies can customize specific themes according to their own training tasks, such as photos of night, cones, parking lots, and signboards at night, to improve AIs recognition rate in night scenes. The public can take tasks, upload them after shooting, and then the company will review them. Then the parts that meet the requirements will be settled by the number of photos. The price is about 1-2 US dollars for a high-quality picture, 5-7 US dollars for a short film of more than 10 seconds, 100-300 US dollars for a high-quality film of more than 10 minutes, and 1 US dollar for a thousand words of text. Those who take subcontracting tasks can get about 20% of the fees. Data provision may become another crowdsourcing business after data labeling.
Global crowdsourcing of tasks, economic incentives, pricing, circulation and privacy protection of data assets, and participation by everyone, sounds like a business that fits the Web3 paradigm.
AI narrative targets from the perspective of industry supply side
The concern caused by the chip shortage has permeated the crypto industry, making distributed computing power the hottest and most valuable AI track category to date.
So if the supply and demand contradiction of energy and data in the AI industry breaks out in the next 1-2 years, what narrative-related projects are currently in the crypto industry?
Let’s first look at energy-related targets.
There are very few energy projects that have been listed on the top CEXs, with only Power Ledger (token Powr) being the only one.
Power Ledger was established in 2017. It is an integrated energy platform based on blockchain technology. It aims to decentralize energy transactions, promote direct electricity trading between individuals and communities, support the widespread application of renewable energy, and ensure the transparency and efficiency of transactions through smart contracts. Initially, Power Ledger operated on a consortium chain based on Ethereum. In the second half of 2023, Power Ledger updated its white paper and launched its own integrated public chain, which was transformed from Solanas technical framework to facilitate the processing of high-frequency micro-transactions in the distributed energy market. At present, Power Ledgers main businesses include:
Energy trading: Allows users to buy and sell electricity directly on a peer-to-peer basis, particularly electricity from renewable sources.
Environmental product trading: such as the trading of carbon credits and renewable energy certificates, as well as financing based on environmental products.
Public chain operation: Attract application developers to build applications on the Powerledger blockchain, and the transaction fees of the public chain are paid in Powr tokens.
The current circulating market value of the Power Ledger project is $170 million, and the total circulating market value is $320 million.
Compared with energy-related encrypted targets, the number of encrypted targets in the data track is more abundant.
The author only lists the data track projects that he is currently paying attention to and have been launched on at least one of the CEXs, Binance, OKX and Coinbase, and arranges them from low to high according to FDV:
1. Streamr – DATA
Streamrs value proposition is to build a decentralized real-time data network that allows users to freely trade and share data while maintaining full control over their own data. Through its data المتجر, Streamr hopes to enable data producers to sell data streams directly to interested consumers without the need for intermediaries, thereby reducing costs and increasing efficiency.
Source: https://streamr.network/hub/projects
In an actual cooperation case, Streamr cooperated with another Web3 in-vehicle hardware project DIMO to collect temperature, air pressure and other data through DIMO hardware sensors installed on vehicles, forming a weather data stream for transmission to agencies in need.
Compared with other data projects, Streamr focuses more on the data of the Internet of Things and hardware sensors. In addition to the DIMO vehicle data mentioned above, other projects include real-time traffic data streams in Helsinki, etc. Therefore, Streamrs project token DATA also created a doubling of its value in a single day in December last year when the Depin concept was the hottest.
The current circulating market value of the Streamr project is $44 million, and the total circulating market value is $58 million.
2. Covalent – CQT
Unlike other data projects, Covalent provides blockchain data. The Covalent network reads data from blockchain nodes through RPC, and then processes and organizes the data to create an efficient query database. In this way, Covalent users can quickly retrieve the information they need without having to perform complex queries directly from blockchain nodes. This type of service is also called blockchain data indexing.
Covalents clients are mainly B-side, including Dapp projects, such as various Defi, and many centralized crypto companies, such as Consensys (Metamasks parent company), CoinGecko (a well-known crypto asset market station), Rotki (tax tool), Rainbow (crypto wallet), etc. In addition, Fidelity, a giant in the traditional financial industry, and Ernst Young, one of the Big Four accounting firms, are also Covalents clients. According to the official data disclosed by Covalent, the projects revenue from data services has exceeded that of The Graph, a leading project in the same field.
Due to the integrity, openness, authenticity and real-time nature of on-chain data, the Web3 industry is expected to become a high-quality data source for segmented AI scenarios and specific AI mini-models. As a data provider, Covalent has begun to provide data for various AI scenarios and has launched verifiable structured data specifically for AI.

Source: https://www.covalenthq.com/solutions/decentralized-ai/
For example, it provides data to the on-chain intelligent trading platform SmartWhales, using AI to identify profitable trading patterns and addresses; Entendre Finance uses Covalents structured data and AI processing for real-time insights, anomaly detection, and predictive analysis.
At present, the main scenarios of on-chain data services provided by Covalent are still mainly finance, but with the generalization of Web3 products and data types, the usage scenarios of on-chain data will be further expanded.
Currently, the Covalent project has a circulating market value of $150 million and a full circulating market value of $235 million. Compared with The Graph, a blockchain data index project in the same field, it has a relatively obvious valuation advantage.
3. Hivemapper – Honey
Among all data materials, the unit price of video data is often the highest. Hivemapper can provide data including video and map information to AI companies. Hivemapper itself is a decentralized global map project that aims to create a detailed, dynamic and accessible map system through blockchain technology and community contributions. Participants can capture map data through dashcams and add it to the open source Hivemapper data network, and receive rewards based on their contributions in the project token HONEY. In order to improve the network effect and reduce interaction costs, Hivemapper is built on Solana.
Hivemapper was first founded in 2015 with the original vision of using drones to create maps, but later found that this model was difficult to scale, so it turned to using dash cams and smartphones to capture geographic data, reducing the cost of global map production.
Compared with street view and mapping software such as Google Map, Hivemapper can more efficiently expand map coverage, maintain the freshness of map real scenes, and improve video quality through incentive networks and crowdsourcing models.
Before AI’s demand for data exploded, Hivemapper’s main customers included the auto industry’s autonomous driving sector, navigation service companies, governments, insurance and real estate companies, etc. Today, Hivemapper can provide extensive road and environmental data to AI and large models through APIs. With the input of continuously updated image and road feature data streams, AI and ML models will be able to better transform data into improved capabilities and perform tasks related to geographic location and visual judgment.

Data source: https://hivemapper.com/blog/diversify-ai-computer-vision-models-with-global-road-imagery-map-data/
Currently, the circulating market value of the Hivemapper-Honey project is $120 million, and the total circulating market value is $496 million.
In addition to the above three projects, other projects in the data track include The Graph – GRT (market value of $3.2 billion, FDV of $3.7 billion), whose business is similar to Covalent and also provides blockchain data indexing services; and Ocean Protocol – OCEAN (market value of $670 million, FDV of $1.45 billion, this project is about to merge with Fetch.ai and SingularityNET, and the token will be converted to ASI), an open source protocol designed to facilitate the exchange and monetization of data and data-related services, connecting data consumers with data providers, so as to share data while ensuring trust, transparency and traceability.
In my opinion, the first year of the AI track in the crypto industry is 2023 when GPT shocked the world. The surge in crypto AI projects is more of the aftermath brought about by the explosive development of the AI industry.
Although the capabilities of GPT 4, turbo, etc. have been continuously upgraded after GPT 3.5, and Sora has demonstrated amazing video creation capabilities, and large language models outside of OpenAI have also developed rapidly, it is undeniable that the cognitive impact of AIs technological progress on the public is weakening, people are gradually beginning to use AI tools, and large-scale job replacement does not seem to have occurred yet.
So, will there be another GPT moment in the field of AI in the future, with a leap forward in AI that shocks the public and makes people realize that their lives and work will be changed as a result?
That moment could be the advent of artificial general intelligence (AGI).
AGI refers to machines that have comprehensive cognitive abilities similar to those of humans and can solve a variety of complex problems, not just specific tasks. AGI systems have the ability to think in a highly abstract way, have extensive background knowledge, reason about common sense in all fields, understand causal relationships, and transfer learning across disciplines. AGIs performance is no different from the best humans in each field, and in terms of comprehensive capabilities, it completely surpasses the best human group.
In fact, whether it is presented in science fiction novels, games, movies and TV shows, or the publics expectations after the rapid popularization of GPT, the public has long anticipated the emergence of AGI that exceeds the level of human cognition. In other words, GPT itself is the forerunner of AGI and the prophetic version of general artificial intelligence.
The reason why GPT has such great industrial energy and psychological impact is that its speed of implementation and performance exceeded public expectations: people did not expect that an artificial intelligence system that can complete the Turing test would really arrive, and at such a fast speed.
In fact, artificial intelligence (AGI) may reproduce the suddenness of the GPT moment again within 1-2 years: people have just adapted to the assistance of GPT, and they find that AI is no longer just an assistant. It can even independently complete extremely creative and challenging tasks, including those difficult problems that have trapped top human scientists for decades.
On April 8 of this year, Musk was interviewed by Nicolai Tangen, chief investment officer of the Norwegian Sovereign Wealth Fund, and talked about when AGI will appear.
“If you define AGI as being smarter than the smartest humans, I think it’s very likely to happen by 2025,” he said.
That is to say, according to his inference, it will take at most one and a half years for AGI to arrive. Of course, he added a prerequisite, which is if the electricity and hardware can keep up.
The benefits of the advent of AGI are obvious.
It means that the productivity of mankind will be greatly improved, and a large number of scientific research problems that have troubled us for decades will be solved. If we define the smartest part of humanity as the level of Nobel Prize winners, it means that as long as there is enough energy, computing power and data, we can have countless tireless Nobel Prize winners working around the clock to solve the most difficult scientific problems.
In fact, Nobel Prize winners are not as rare as one in a hundred million. Most of them are at the level of professors at top universities in terms of ability and intelligence, but because of probability and luck, they chose the right direction, continued to work on it and got the results. People with the same level as him, his equally excellent colleagues, may also have won the Nobel Prize in the parallel universe of scientific research. But unfortunately, there are still not enough people who are professors at top universities and participate in scientific research breakthroughs, so the speed of traversing all the correct directions of scientific research is still very slow.
With AGI, if energy and computing power are fully supplied, we can have unlimited Nobel Prize winner-level AGIs to conduct in-depth exploration in any possible scientific breakthrough direction, and the speed of technological advancement will be dozens of times faster. The advancement of technology will lead to a hundredfold increase in resources that we now consider to be quite expensive and scarce in 10 to 20 years, such as food production, new materials, new drugs, high-level education, etc. The cost of obtaining these will also decrease exponentially, allowing us to feed more people with fewer resources, and the per capita wealth will increase rapidly.

Global GDP trend chart, data source: World Bank
This may sound a bit sensational, but lets look at two examples that I have used in previous research reports on IO.NET :
In 2018, Francis Arnold, Nobel Prize winner in Chemistry, said at the award ceremony: Today we can read, write and edit any DNA sequence in practical applications, but we cannot compose it yet. Just five years after his speech, in 2023, researchers from Stanford University and Salesforce Research, an AI startup in Silicon Valley, published a paper in Nature Biotechnology. They created 1 million new proteins from scratch through a large language model fine-tuned based on GPT 3, and found 2 proteins with completely different structures but both with bactericidal ability, which are expected to become a bacterial anti-bacterial solution besides antibiotics. In other words: with the help of AI, the bottleneck of protein creation has been broken.
Prior to this, the artificial intelligence AlphaFold algorithm predicted almost all of the 214 million protein structures on Earth within 18 months. This achievement is hundreds of times the work of all human structural biologists in the past.
The change is already happening, and the advent of AGI will further accelerate the process.
On the other hand, the challenges brought by the advent of AGI are also enormous.
AGI will not only replace a large number of mental workers, but also physical service workers who are now considered less affected by AI will be impacted as the maturity of robotics technology and the reduction of production costs brought about by the research and development of new materials. The proportion of jobs replaced by machines and software will increase rapidly.
At that time, two problems that once seemed very far away will soon surface:
Employment and income issues for a large number of unemployed people
In a world where AI is everywhere, how to distinguish between AI and humans
WorldcoinWorldchain is trying to provide a solution, which is to use the UBI (Universal Basic Income) system to provide basic income to the public and use iris-based biometrics to distinguish between people and AI.
In fact, UBI, which gives money to everyone, is not a castle in the air without real practice. Countries such as Finland and England have implemented universal basic income, and political parties in Canada, Spain, India and other countries are actively proposing to promote related experiments.
The advantage of distributing UBI based on the biometric recognition + blockchain model is that the system is global and covers a wider population. In addition, other business models can be built based on the user network expanded through income distribution, such as financial services (Defi), social networking, task crowdsourcing, etc., to form business synergy within the network.
One of the corresponding targets for the impact effect brought about by the advent of AGI is Worldcoin – WLD, which has a circulation market value of $1.03 billion and a total circulation market value of $47.2 billion.
This article is different from many project and track research reports previously released by Mint Ventures. The deduction and prediction of the narrative are highly subjective. Please treat the content of this article as a divergent discussion rather than a prediction of the future. The above narrative deduction faces many uncertainties, which lead to wrong guesses. These risks or influencing factors include but are not limited to:
Energy: GPU upgrades lead to a rapid drop in energy consumption
Although the energy demand for AI has soared, chip manufacturers such as NVIDIA are providing higher computing power with lower power consumption through continuous hardware upgrades. For example, in March this year, NVIDIA released a new generation of AI computing card GB 200 that integrates two B 200 GPUs and one Grace CPU. Its training performance is 4 times that of the previous generation of main AI GPU H 100, and its reasoning performance is 7 times that of H 100, but the energy consumption required is only 1/4 of H 100. Of course, despite this, peoples desire for power from AI is far from over. With the decline of unit energy consumption, as AI application scenarios and demand further expand, the total energy consumption may actually increase.
Data: Q* plans to achieve self-generated data
There has always been a rumored project Q* within OpenAI, which was mentioned in an internal message sent by OpenAI to employees. According to Reuters, citing OpenAI insiders, this may be a breakthrough for OpenAI in its pursuit of super intelligence/general artificial intelligence (AGI). Q* can not only solve mathematical problems that have never been seen before with its abstract ability, but also create data for training large models by itself without the need for real-world data feeding. If the rumor is true, the bottleneck of AI large model training limited by insufficient high-quality data will be broken.
The advent of AGI: OpenAIs hidden worries
Whether AGI will come in 2025 as Musk said is still unknown, but it is only a matter of time. However, as a direct beneficiary of the AGI advent narrative, Worldcoin’s biggest concern may come from OpenAI, after all, it is recognized as an “OpenAI shadow token”.
In the early morning of May 14, OpenAI demonstrated the performance of the latest GPT-4 o and 19 other different versions of large language models in comprehensive task scores at its spring new product launch conference. Judging from the table alone, GPT-4 o scored 1310, which visually seems to be much higher than the latter few, but in terms of the total score, it is only 4.5% higher than the second-place GPT 4 turbo, 4.9% higher than the fourth-place Google Gemini 1.5 Pro, and 5.1% higher than the fifth-place Anthropic Claude 3 Opus.
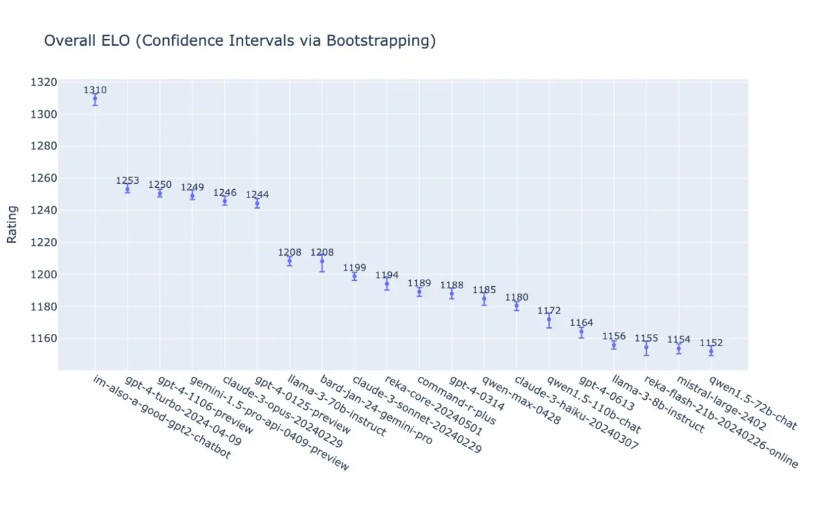
Just over a year has passed since GPT 3.5 shocked the world when it was first released, and OpenAIs competitors have already caught up very closely (although GPT 5 has not yet been released and is expected to be released this year). Whether OpenAI can maintain its leading position in the industry in the future seems to be becoming unclear. If OpenAIs leading advantage and dominance are diluted or even surpassed, then the narrative value of Worldcoin as OpenAIs shadow token will also decline.
In addition to Worldcoin’s iris authentication solution, more and more competitors are entering this market. For example, the palm scanning ID project Humanity Protocol has just announced a new round of financing of $30 million at a valuation of $1 billion. LayerZero Labs also announced that it will run on Humanity and join its validator node network, using ZK proofs to authenticate credentials.
Finally, although the author has deduced the subsequent narrative of the AI track, the AI track is different from crypto-native tracks such as DeFi. It is more of a product of the spillover of the AI craze into the currency circle. Many current projects have not been successful in terms of business models, and many projects are more like AI-themed memes (for example, Rndr is similar to Nvidia’s meme, and Worldcoin is similar to OpenAI’s meme). Readers should view them with caution.
This article is sourced from the internet: The next wave of narrative deduction in the crypto AI track: catalytic factors, development paths and related targets
Original|Odaily Planet Daily Author: Azuma Last weekend, Blast officially announced the distribution details of the second phase of Gold Points (Blast Gold), and announced that it will distribute a total of 10 million Gold Points to 70 ecological projects this week. As another major contribution evaluation indicator independent of the ordinary points system that is becoming increasingly inflated, since Blast has previously stated that 50% of the airdrop shares will be allocated to gold points holders, the gold points are also considered to be the most valuable on Blast . Compared with the first phase of allocation opportunities, the total allocation of Golden Points in this phase (10 million) has not changed, but the number of selected projects has been halved (140 in the first phase), and Blast has used…













