My XP
0
Login
Original title: Possible futures of the Ethereum protocol, part 5: The Purge
Original article by Vitalik Buterin
Original translation: Odaily Planet Daily Husband How

Since October 14, Ethereum founder Vitalik Buterin has successively published discussions on the possible future of Ethereum. From The Merge , The Surge , The Scourge , The Verge to the latest release The Purge , they all highlight Vitaliks vision for the future development of the Ethereum mainnet and how to solve the current problems. Solutions.
The Merge: Discusses the need for Ethereum to improve single-slot finality and lower staking thresholds after moving to PoS to increase participation and speed up transaction confirmation.
The Surge: Explores different strategies for scaling Ethereum, especially the Rollup-centric roadmap, and its challenges and solutions in terms of scalability, decentralization, and security.
The Scourge: Explores the risks of centralization and value extraction faced by Ethereum in its transition to PoS, develops multiple mechanisms to enhance decentralization and fairness, and reforms the staking economy to protect user interests.
The Verge: Explores the challenges and solutions of Ethereum’s stateless verification, focusing on how technologies such as Verkle trees and STARKs can enhance the decentralization and efficiency of blockchain.
On October 26, Vitalik Buterin published an article about The Purge, which discussed the challenge facing Ethereum is how to reduce complexity and storage requirements in the long term while maintaining the durability and decentralization of the chain. Key measures include reducing the client storage burden through history expiration and state expiration, and simplifying the protocol through feature cleanup to ensure the sustainability and scalability of the network.
The following is the original content, translated by Odaily Planet Daily.
Special thanks to Justin Drake, Tim Beiko, Matt Garnett, Piper Merriam, Marius van der Wijden, and Tomasz Stanczak for their feedback and reviews.
One of the challenges with Ethereum is that, by default, any blockchain protocol will grow in bloat and complexity over time. This happens in two places:
Historical data: Any transaction made and any account created at any point in history needs to be permanently stored by all clients and downloaded by any new client to be fully synchronized to the network. This causes client load and synchronization time to increase over time, even if the capacity of the chain remains constant.
Protocol features: It is much easier to add new features than to remove old ones, causing code complexity to increase over time.
For Ethereum to be sustainable in the long term, we need to exert strong counter-pressure to both of these trends, reducing complexity and bloat over time. But at the same time, we need to preserve one of the key properties that make blockchains great: durability. You can put an NFT, a love letter in a transaction call data, or a smart contract with $1 million on the chain, go into a cave for ten years, and come out to find it is still there waiting for you to read and interact with it. In order for DApps to feel comfortable fully decentralizing and removing upgrade keys, they need to be confident that their dependencies will not be upgraded in a way that breaks them – especially L1 itself.
It is absolutely possible to strike a balance between these two needs and minimize or reverse bloat, complexity, and decay while maintaining continuity if we are determined to do so. Organisms can do this: while most organisms age over time, a lucky few do not . Even social systems can have extremely long lifespans . Ethereum has succeeded in some cases: proof of work is gone, the SELFDESTRUCT opcode is mostly gone, and beacon chain nodes have been storing up to six months old data. Figuring out this path for Ethereum in a more general way, and toward a long-term stable end result, is the ultimate challenge for Ethereums long-term scalability, technical sustainability, and even security.
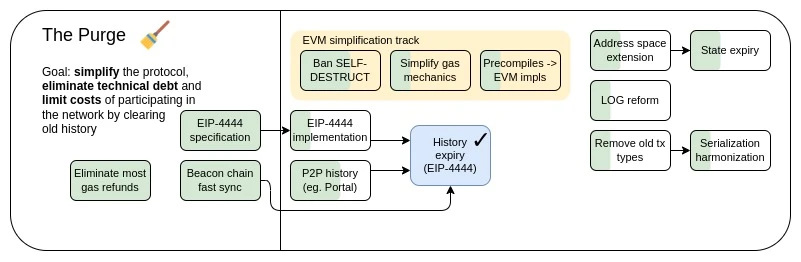
The Purge: Primary goal.
Lower client storage requirements by reducing or eliminating the need for each node to permanently store all history or even final state.
Reduce protocol complexity by eliminating unnecessary functionality.
Article Directory:
As of this writing, a fully synchronized Ethereum node requires about 1.1 TB of disk space for the execution client , and hundreds of GB more for the consensus client. The vast majority of this is history: data about historical blocks, transactions, and receipts, much of which is many years old. This means that even if the gas limit did not increase at all, the size of the node would continue to increase by hundreds of GB per year.
A key simplifying feature of the history storage problem is that because each block points to the previous block via hash links (and other structures ), consensus on the present is sufficient to reach consensus on the history. As long as the network agrees on the latest block, any historical block or transaction or state (account balance, random number, code, storage) can be provided by any single participant along with a Merkle proof, and that proof allows anyone else to verify its correctness. Consensus is an N/2-of-N trust model, while history is an N-of-N trust model .
This leaves us with a lot of options for how we store history. One natural choice is a network where each node stores only a small fraction of the data. This is how the Seed network has operated for decades: while the network stores and distributes millions of files in total, each participant stores and distributes only a few of them. Perhaps counterintuitively, this approach doesn’t even necessarily reduce the robustness of the data. If, by making it more affordable to run nodes, we can build a network with 100,000 nodes, where each node stores a random 10% of the history, then each piece of data will be replicated 10,000 times – exactly the same replication factor as a 10,000-node network, where each node stores everything.
Today, Ethereum has begun to move away from a model where all nodes store all history permanently. Consensus blocks (i.e. the part related to proof-of-stake consensus) are only stored for about 6 months. Blobs are only stored for about 18 days. EIP-4444 aims to introduce a one-year storage period for historical blocks and receipts. The long-term goal is to establish a uniform period (probably about 18 days) during which each node is responsible for storing everything, and then establish a peer-to-peer network of Ethereum nodes that store old data in a distributed network manner.
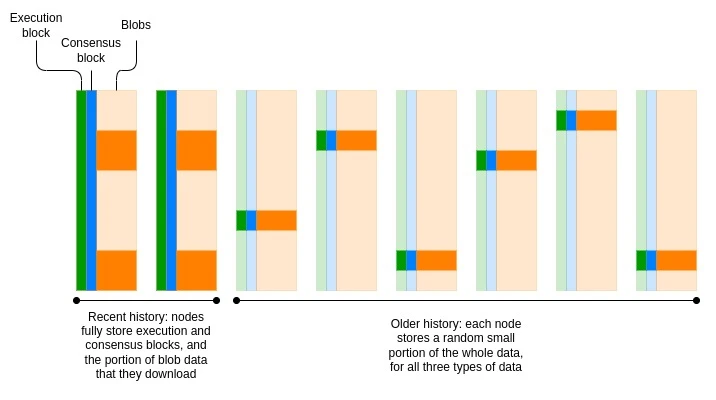
Erasure codes can be used to improve robustness while keeping the replication factor the same. In fact, blobs are already erasure coded to support data availability sampling. The simplest solution is probably to reuse such erasure codes and put the execution and consensus block data into the blob as well.
The main work remaining involves building and integrating a concrete distributed solution for storing history – at least execution history, but eventually consensus and blobs as well. The simplest solutions are (i) simply bringing in existing torrent libraries, and (ii) an Ethereum-native solution called Portal networks . Once either of these are introduced, we can turn on EIP-4444. EIP-4444 itself does not require a hard fork, but it does require a new network protocol version. Therefore, it is valuable to enable it for all clients at the same time, otherwise there is a risk of clients failing because they connect to other nodes expecting to download the full history but actually do not get it.
The main trade-off involves how hard we work to make “ancient” history data available. The simplest solution is to stop storing ancient history tomorrow and rely on existing archive nodes and various centralized providers for replication. This is easy, but it weakens Ethereum as a permanent place of record. The more difficult but safer path is to first build and integrate a torrent network to store history in a distributed way. Here, “how hard we work” has two dimensions:
How do we try to ensure that the largest set of nodes actually stores all the data?
How deeply do we integrate history storage into the protocol?
An extremely paranoid approach to (1) would involve proof of custody : effectively requiring each proof-of-stake validator to store a certain percentage of history, and periodically cryptographically checking that they are doing so. A more moderate approach would be to set a voluntary standard for what percentage of history each client stores.
For (2), the basic implementation only involves work that is already done today: Portal already stores an ERA file containing the entire history of Ethereum. A more thorough implementation would involve actually connecting it to the sync process, so that if someone wants to sync a full history storage node or archive node, they can do so by syncing directly from the Portal network, even if no other archive nodes exist online.
If we want to make it extremely easy to run or spin up a node, then reducing history storage requirements is arguably more important than statelessness: of the 1.1 TB a node requires, ~300 GB is state, and the remaining ~800 GB is history. Only with statelessness and EIP-4444 can we achieve the vision of running an Ethereum node on a smartwatch and setting it up in just minutes.
Limiting historical storage also makes it more feasible for newer Ethereum node implementations to only support the latest version of the protocol, which makes them much simpler. For example, many lines of code can now be safely removed because the empty storage slots created during the 2016 DoS attack have all been deleted . Now that the move to proof-of-stake is history, clients can safely remove all proof-of-work related code.
Even if we eliminated the need for clients to store history, client storage requirements would continue to grow, by about 50 GB per year, as the state continues to grow: account balances and nonces, contract code, and contract storage. Users could pay a one-time fee, thus burdening current and future Ethereum clients forever.
State is harder to expire than history, because the EVM is fundamentally designed around the assumption that once a state object is created, it always exists and can be read by any transaction at any time. If we introduce statelessness, some people think that this problem may not be so bad: only specialized block builder classes need to actually store state, and all other nodes (even list generation!) can run statelessly. However, there is an argument that we dont want to rely too much on statelessness, and eventually we may want to expire state to keep Ethereum decentralized.
Today, when you create a new state object (which can happen in one of three ways: (i) sending ETH to a new account, (ii) creating a new account using code, (iii) setting up a previously untouched storage slot), that state object stays in that state forever. Instead, what we want is for objects to automatically expire over time. The key challenge is to do this in a way that achieves three goals:
Efficiency: No significant amount of additional computation is required to run the expiration process.
User-friendliness: If someone goes into a cave for five years and comes back, they shouldn’t lose access to their ETH, ERC 20, NFT, CDP positions…
Developer-friendliness: Developers don’t have to switch to a completely unfamiliar mental model. Also, currently ossified and unupdated applications should continue to work fine.
Its easy to solve problems that dont meet these goals. For example, you could have each state object also store an expiration date counter (the expiration date can be extended by burning ETH, which could happen automatically any time its read or written), and have a process that loops through the state to remove expired state objects. However, this introduces additional computation (and even storage requirements), and it certainly doesnt meet the requirement of user-friendliness. Its also hard for developers to reason about edge cases involving stored values that sometimes get reset to zero. If you set expiration timers within the scope of the contract, this makes the developers life technically easier, but it makes the economics more difficult: the developer has to think about how to pass on the ongoing storage costs to the user.
These are issues that the Ethereum core development community has been working on for years, including proposals such as “ blockchain rent ” and “ regeneration .” Ultimately, we combined the best parts of the proposals and focused on two categories of “least-worst known solutions”:
Partial status expiration solution
State expiration recommendations based on address cycles.
The partial state expiration proposals all follow the same principle. We split the state into chunks. Each one permanently stores a top-level map where the chunk is either empty or non-empty. The data in each chunk is only stored if that data has been recently accessed. There is a resurrection mechanism that resurrects the chunk if it is no longer stored.
The main differences between these proposals are: (i) how do we define “recently”, and (ii) how do we define “block”? One specific proposal is EIP-7736 , which builds on the “stem-and-leaf” design introduced for Verkle trees (although compatible with any form of stateless state, such as binary trees). In this design, headers, code, and storage slots that are adjacent to each other are stored under the same “trunk”. The data stored under a stem can be up to 256 * 31 = 7,936 bytes. In many cases, the entire header and code of an account, as well as many key storage slots, will be stored under the same trunk. If data under a given trunk has not been read or written for 6 months, the data is no longer stored, and only a 32-byte commitment (“stub”) to that data is stored. Future transactions that access that data will need to “resurrect” the data and provide a proof that it checks against the stub.
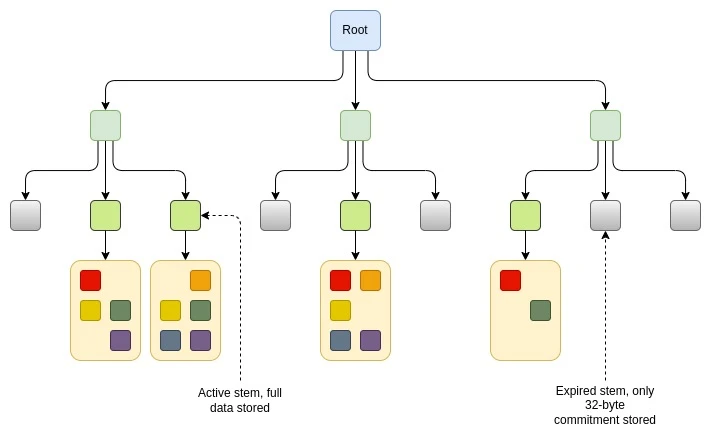
There are other ways to implement similar ideas. For example, if the account level granularity is not enough, we could make a scheme where each 1/2 32 part of the tree is controlled by a similar stem-and-leaf mechanism.
This is made more tricky because of incentives: an attacker could force clients to store large amounts of state permanently by putting large amounts of data into a single subtree and sending a single transaction every year to update the tree. If you make the renewal cost proportional to the tree size (or inversely proportional to the renewal duration), then someone could potentially harm other users by putting large amounts of data into the same subtree as them. One could try to limit both of these problems by making the granularity dynamic with respect to the subtree size: e.g., each consecutive 216 = 65536 state objects could be considered a group. However, these ideas are more complex; stem-based approaches are simple, and incentives can be aligned because typically all data under a stem is related to the same application or user.
What if we want to avoid any permanent state growth at all, even a 32-byte stub? This is a hard problem due to resurrection conflicts : what if a state object is deleted, and later EVM execution puts another state object in the exact same place, but then someone who cares about the original state object comes back and tries to restore it? When part of the state expires, the stub prevents new data from being created. With the state fully expired, we cant even store the stub.
The address-cycle based design is the most well-known idea to solve this problem. Instead of having one state tree storing the entire state, we have a growing list of state trees, and any state read or written is saved in the latest state tree. A new empty state tree is added once every epoch (e.g.: 1 year). The old trees are frozen solid. Full nodes only store the two most recent trees. If a state object has not been touched in two epochs and thus falls into the expired tree, it can still be read or written, but transactions need to prove its Merkle proof – once proven, a copy is saved again in the latest tree.

A key idea that makes this user- and developer-friendly is the concept of address periods. An address period is a number that is part of an address. The key rule is that an address with address period N can only be read from or written to during or after period N (i.e., when the state tree list reaches length N). If you are saving a new state object (e.g., a new contract, or a new ERC 20 balance), if you make sure you put the state object into a contract with address period N or N-1, then you can save it immediately, without having to provide proof that nothing was there before. On the other hand, any additions or edits made during the old address period will require proof.
This design retains most of Ethereums current properties, does not require additional computation, allows applications to be written almost as they are now (ERC 20 needs to be rewritten to ensure that address balances with address cycle N are stored in subcontracts, which themselves have address cycle N), and solves the users in caves for five years problem. However, it has a big problem: addresses need to be expanded to more than 20 bytes to accommodate address cycles.
One proposal is to introduce a new 32-byte address format that includes a version number, address cycle number, and extended hash.
0x 01 (red) 0000 (orange) 000001 (green) 57 aE 408398 dF 7 E 5 f 4552091 A 69125 d5 FWf 7 B 8 C 2659029395 bdF (blue).
The red one is the version number. The four orange zeros here are intended to be blank spaces that can accommodate shard numbers in the future. The green one is the address cycle number. The blue one is the 26-byte hash value.
The key challenge here is backward compatibility. Existing contracts are designed around 20-byte addresses, and often use strict byte packing techniques that explicitly assume addresses are exactly 20 bytes long. One idea to address this involves a conversion mapping, where legacy contracts interacting with new-style addresses will see a 20-byte hash of the new-style address. However, there are significant complexities in ensuring this is secure.
Another approach goes in the opposite direction: we immediately ban some subrange of size 2 128 (for example, all addresses starting with 0x ffffffff ), and then use that range to introduce addresses with address cycles and 14-byte hash values.
0x ffffffff 000169125 d5 FWf 7 B 8 C2659029395bdF
The main sacrifice made by this approach is the security risk of introducing counterfactual addresses : addresses that hold assets or permissions but whose code has not yet been published to the chain. The risk involves someone creating an address that claims to own a piece of (as-yet-unpublished) code, but also has another valid piece of code that hashes to the same address. Calculating such a collision today requires 2 80 hashes; address space shrinkage will reduce this number to an easily accessible 2 56 hashes.
The key risk area, counterfactual addresses for wallets not held by a single owner, is relatively rare today, but will likely become more common as we move into a multi-L2 world. The only solution is to simply accept this risk, but identify all common use cases where it could go wrong, and come up with effective workarounds.
Early Proposals
Partial Status Expiration Proposal
EIP-7736 ;
Address Space Extension Documentation
I see four possible paths forward:
We make it stateless, and never introduce state expiration. The state is growing (albeit slowly: we probably won’t see it exceed 8 TB for decades), but only by a relatively special class of users: not even PoS validators need state.
One feature that requires access to part of the state is inclusion list generation, but we can do this in a decentralized way: Each user is responsible for maintaining the portion of the state trie that contains their own account. When they broadcast a transaction, they broadcast it along with proofs of the state objects accessed during the verification step (this works for both EOA and ERC-4337 accounts). The stateless validator can then combine these proofs into a proof of the entire inclusion list.
We perform partial state expiration and accept a much lower but still non-zero permanent state size growth rate. This result is arguably similar to how history expiration proposals involving peer-to-peer networks accept a much lower but still non-zero permanent history storage growth rate where each client must store a lower but fixed percentage of history data.
We are doing state expiration via address space extensions. This will involve a multi-year process to ensure the address format conversion method is effective and safe, including for existing applications.
We perform state expiration by shrinking the address space. This will involve a multi-year process to ensure that all security risks involving address conflicts (including cross-chain situations) are handled.
The important point is that whether or not a state expiration scheme that relies on address format changes is implemented, the hard problem of address space expansion and contraction must eventually be solved. Today, generating an address collision requires about 2 80 hashes, and this computational load is already feasible for extremely resourceful actors: a GPU can perform about 2 27 hashes, so it can calculate 2 52 in a year, so all about 2 30 GPUs in the world can calculate a collision in about 1/4 of a year, and FPGAs and ASICs can accelerate this process further. In the future, such attacks will be open to more and more people. Therefore, the actual cost of implementing full state expiration may not be as high as it seems, because we have to solve this very challenging address problem anyway.
Doing state expiration may make it easier to transition from one state trie format to another, because no conversion process is required: you can simply start creating a new tree with the new format, and then do a hard fork to convert the old tree. So while state expiration is complex, it does have the benefit of simplifying other aspects of the roadmap.
One of the key prerequisites for security, accessibility, and trusted neutrality is simplicity. If a protocol is beautiful and simple, it is less likely to have bugs. It increases the chances that new developers will be able to participate in any part of it. It is more likely to be fair and easier to defend against special interests. Unfortunately, protocols, like any social system, will by default become more complex over time. If we don’t want Ethereum to fall into a black hole of increasing complexity, we need to do one of two things: (i) stop making changes and ossifying the protocol, or (ii) be able to actually remove features and reduce complexity. A middle path is also possible, making fewer changes to the protocol and removing at least a little complexity over time. This section discusses how to reduce or eliminate complexity.
There is no major single fix that will reduce the complexity of the protocol; the nature of the problem is that there are many small fixes.
One example that has been mostly completed, and can serve as a blueprint for how to approach the other examples, is the removal of the SELFDESTRUCT opcode . The SELFDESTRUCT opcode was the only opcode that could modify an unlimited number of storage slots within a single block, requiring clients to implement significantly more complexity to avoid DoS attacks. The original purpose of the opcode was to enable voluntary state liquidation, allowing the state size to decrease over time. In practice, few people ended up using it. The opcode was nerfed to only allow self-destructing accounts created in the same transaction as the Dencun hard fork. This solves the DoS issue and can significantly simplify client code. In the future, it may make sense to eventually remove the opcode entirely.
Some key examples of protocol simplification opportunities identified to date include the following. First, some examples outside of the EVM; these are relatively non-invasive and therefore easier to reach consensus on and implement in a shorter time.
RLP → SSZ conversion: Originally, Ethereum objects were serialized using an encoding called RLP . RLP is untyped and unnecessarily complex. Today, the beacon chain uses SSZ , which is significantly better in many ways, including supporting not only serialization but also hashing. Eventually, we hope to get rid of RLP completely and move all data types to SSZ structures, which in turn will make upgrades much easier. Current EIPs include [1] [2] [3] .
Removing legacy transaction types: There are too many transaction types today, and many of them could potentially be removed. A more modest alternative to complete removal is an account abstraction feature, whereby Smart Accounts could contain code to handle and validate legacy transactions if they so wish.
LOG Reform: Log creation bloom filters and other logic add complexity to the protocol, but are not actually used by clients because it is too slow. We can remove these features and work on alternatives, such as out-of-protocol decentralized log reading tools using modern technologies such as SNARKs.
Eventually remove the Beacon Chain Sync Committee mechanism: The Sync Committee mechanism was originally introduced to enable light client verification for Ethereum. However, it significantly increases the complexity of the protocol. Eventually, we will be able to verify the Ethereum consensus layer directly using SNARKs , which will eliminate the need for a dedicated light client verification protocol. Potentially, the consensus change could enable us to remove the Sync Committee earlier by creating a more native light client protocol that involves verifying signatures from a random subset of Ethereum consensus validators.
Data format unification: Today, execution state is stored in Merkle Patricia trees, consensus state is stored in SSZ trees , and blobs are committed via KZG commitments . In the future, it would make sense to have a single unified format for block data and a single unified format for state. These formats would satisfy all important requirements: (i) simple proofs for stateless clients, (ii) serialization and erasure coding of data, and (iii) standardized data structures.
Removing the Beacon Chain Committee: This mechanism was originally introduced to support a specific version of execution sharding . Instead, we ended up sharding via L2 and blobs . As such, the committee is unnecessary, so the move to eliminate it is being made .
Remove mixed endianness: EVM is big endian, consensus layer is little endian. It might make sense to reconcile and make everything one way or the other (probably big endian, since EVM is harder to change)
Now, some examples in the EVM:
Simplification of the gas mechanism: Current gas rules are not well optimized to give clear limits on the amount of resources required to validate a block. Key examples of this include (i) storage read/write costs, which are intended to limit the number of reads/writes in a block but are currently quite arbitrary, and (ii) memory padding rules, where it is currently difficult to estimate the maximum memory consumption of the EVM. Proposed fixes include a stateless gas cost change (which unifies all storage-related costs into a simple formula) and a memory pricing proposal .
Removing precompiles: Many of the precompiles Ethereum currently has are both unnecessarily complex and relatively unused, and account for a large portion of consensus failures when barely used by any applications. The two ways to deal with this are (i) simply removing the precompile, and (ii) replacing it with a piece of (inevitably more expensive) EVM code that implements the same logic. This draft EIP proposes to do this for identity precompiles as a first step; later, RIPEMD 160, MODEXP, and BLAKE may become candidates for removal.
Remove gas observability: Make it so that the EVM execution can no longer see how much gas it has left. This will break some applications (most notably sponsored transactions), but will make it easier to upgrade in the future (e.g. to more advanced versions with multidimensional gas ). The EOF spec already makes gas unobservable, but to simplify the protocol, EOF needs to be mandatory.
Improvements to static analysis: EVM code is difficult to statically analyze today, especially because jumps can be dynamic. This also makes it harder to optimize EVM implementations (precompile EVM code into other languages). We can fix this by removing dynamic jumps (or making them more expensive, e.g., linear in gas cost of the total number of JUMPDESTs in a contract). EOF does just that, although enforcing EOF is required to gain the protocol simplification benefits from it.
A method for off-chain secure log retrieval using incremental verifiable computation (read: recursive STARKs);
The main trade-offs in doing this kind of feature simplification are (i) how much and how fast we simplify vs. (ii) backwards compatibility. Ethereum’s value as a chain comes from it being a platform where you can deploy an application and be confident that it will still work years later. At the same time, this ideal can also be taken too far and, in the words of William Jennings Bryan , “nail Ethereum to the cross of backwards compatibility”. If there are only two applications in all of Ethereum that use a given feature, and one application has had zero users for years, while the other application is almost completely unused and has gained a total of $57 in value, then we should remove the feature and pay the victim $57 out of pocket if necessary.
The broader societal problem is creating a standardized pipeline for making non-urgent, backwards-compatibility-breaking changes. One way to address this is to examine and extend existing precedents, such as the self-destruct process. The pipeline would look something like this:
Start talking about removing feature X;
Conduct an analysis to determine the impact of removing X on the application, and depending on the outcome: (i) abandon the idea, (ii) proceed as planned, or (iii) determine a revised “least disruptive” approach to removing X and proceeding;
Make a formal EIP to deprecate X. Make sure popular higher-level infrastructure (e.g. programming languages, wallets) respect this and stop using the feature. ;
Finally, actually delete X;
There should be a multi-year pipeline between steps 1 and 4, with clear articulation of which projects are in which step. At this point, there is a trade-off between the vigor and speed of the feature removal process versus being more conservative and investing more resources in other areas of protocol development, but we are far from the Pareto frontier.
The main set of changes proposed to the EVM is the EVM Object Format (EOF) . EOF introduces a lot of changes, such as disabling gas observability, code observability (i.e. no CODECOPY), and only allowing static jumps. The goal is to allow the EVM to be upgraded more in a way that has stronger properties while maintaining backward compatibility (because the EVM before EOF still exists).
The advantage of this is that it creates a natural path for adding new EVM features and encourages migration to a stricter EVM with stronger guarantees. The disadvantage is that it significantly increases the complexity of the protocol unless we can find a way to eventually deprecate and remove the old EVM. A major question is: what role does EOF play in the EVM simplification proposal, especially if the goal is to reduce the complexity of the entire EVM?
Many of the Improvement suggestions in the rest of the roadmap are also opportunities to simplify older features. To repeat some of the examples above:
Switching to single-slot finality gives us the opportunity to remove committees, redesign economics, and make other proof-of-stake related simplifications.
Fully implementing account abstraction will allow us to remove a lot of existing transaction processing logic and move it into a “default account EVM code” that all EOAs can replace.
If we move the Ethereum state to a binary hash tree, this can be reconciled with a new version of SSZ so that all Ethereum data structures can be hashed in the same way.
A more radical strategy for simplifying Ethereum would be to keep the protocol intact but move much of it away from protocol functionality and into contract code.
The most extreme version would be to have Ethereum L1 “technically” just the beacon chain, and introduce a minimal virtual machine (e.g. RISC-V , Cairo , or something even more minimal specifically for proof systems) that allows others to create their own rollups. The EVM would then become the first of these rollups. Ironically, this is exactly the same outcome as the 2019-20 execution environment proposal , although SNARKs make it more feasible to actually implement.
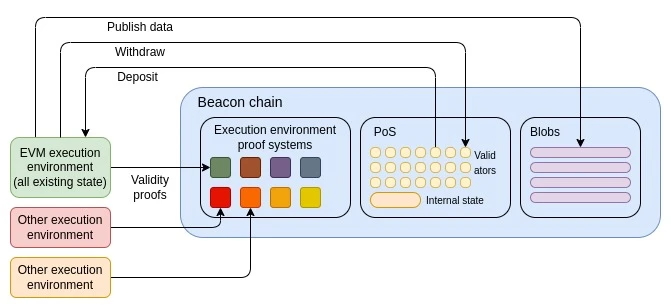
A more modest approach would be to keep the relationship between the beacon chain and the current Ethereum execution environment unchanged, but swap the EVM in place. We could choose RISC-V, Cairo, or another VM as the new official Ethereum VM, and then force all EVM contracts to be converted to the new VM code that interprets the logic of the original code (either by compilation or interpretation). In theory, this could even be done with the target virtual machine being a version of EOF.
This article is sourced from the internet: Vitalik’s new article: The possible future of Ethereum (V) — The Purge













