My XP
0
Login
Original author: @renkingeth
Zero-knowledge proof (ZKP) is widely regarded as one of the most important technological innovations in the blockchain field since distributed ledger technology, and it is also a key area of venture capital. This article systematically reviews the historical literature and latest research on zero-knowledge proof technology over the past four decades.
First, the basic concepts and historical background of zero-knowledge proofs are introduced. Then, the circuit-based zero-knowledge proof technology is analyzed in detail, including the design, application, and optimization methods of models such as zkSNARK, Ben-Sasson, Pinocchio, Bulletproofs, and Ligero. In the field of computing environment, this article introduces ZKVM and ZKEVM, and discusses how they can improve transaction processing capabilities, protect privacy, and improve verification efficiency. The article also introduces the working mechanism and optimization methods of zero-knowledge Rollup (ZK Rollup) as a Layer 2 expansion solution, as well as the latest progress in hardware acceleration, hybrid solutions, and dedicated ZK EVM.
Finally, this paper looks ahead to emerging concepts such as ZKCoprocessor, ZKML, ZKThreads, ZK Sharding, and ZK StateChannels, and explores their potential in blockchain scalability, interoperability, and privacy protection.
By analyzing these latest technologies and development trends, this article provides a comprehensive perspective for understanding and applying zero-knowledge proof technology, demonstrates its great potential in improving the efficiency and security of blockchain systems, and provides an important reference for future investment decisions.
Today, as the Internet is entering the Web3 era, blockchain applications (DApps) are developing rapidly, with new applications emerging almost every day. In recent years, blockchain platforms have hosted millions of user activities and processed billions of transactions every day. The large amount of data generated by these transactions usually includes sensitive personal information such as user identity, transaction amount, account address, and account balance. Given the openness and transparency of blockchain, these stored data are open to everyone, which has caused a variety of security and privacy issues.
Currently, there are several cryptographic techniques that can address these challenges, including homomorphic encryption, ring signatures, secure multi-party computation, and zero-knowledge proofs. Homomorphic encryption allows operations to be performed without decrypting ciphertext, which helps to protect the security of account balances and transaction amounts, but cannot protect the security of account addresses. Ring signatures provide a special form of digital signature that can hide the identity of the signer, thereby protecting the security of account addresses, but cannot protect account balances and transaction amounts. Secure multi-party computation allows computing tasks to be distributed among multiple participants without any participant knowing the data of other participants, effectively protecting the security of account balances and transaction amounts, but also cannot protect the security of account addresses. In addition, homomorphic encryption, ring signatures, and secure multi-party computation cannot be used to verify whether the prover has sufficient transaction amounts in a blockchain environment without revealing transaction amounts, account addresses, and account balances (Sun et al., 2021).
Zero-knowledge proof is a more comprehensive solution. This verification protocol allows the correctness of certain propositions to be verified without revealing any intermediary data (Goldwasser, Micali Rackoff, 1985). The protocol does not require complex public key facilities, and its repeated implementation does not provide malicious users with the opportunity to obtain additional useful information (Goldreich, 2004). Through ZKP, the verifier is able to verify whether the prover has sufficient transaction amount without revealing any private transaction data. The verification process involves generating a proof containing the transaction amount claimed by the prover, and then passing the proof to the verifier, who performs a predefined calculation on the proof and outputs the final calculation result to conclude whether to accept the provers statement. If the provers statement is accepted, it means that they have sufficient transaction amount. The above verification process can be recorded on the blockchain without any falsification (Feige, Fiat Shamir, 1986).
This feature of ZKP makes it play a core role in blockchain transactions and cryptocurrency applications, especially in terms of privacy protection and network expansion, making it not only the focus of academic research, but also widely regarded as one of the most important technological innovations since the successful implementation of distributed ledger technology, especially Bitcoin. It is also a key track for industry applications and venture capital (Konstantopoulos, 2022).
As a result, many ZKP-based network projects have emerged, such as ZkSync, StarkNet, Mina, Filecoin, and Aleo. As these projects develop, algorithmic innovations about ZKP are endless, and new algorithms are reportedly released almost every week (Lavery, 2024; AdaPulse, 2024). In addition, hardware development related to ZKP technology is also progressing rapidly, including chips optimized for ZKP. For example, projects such as Ingonyama, Irreducible, and Cysic have completed large-scale fundraising. These developments not only demonstrate the rapid progress of ZKP technology, but also reflect the shift from general-purpose hardware to specialized hardware such as GPUs, FPGAs, and ASICs (Ingonyama, 2023; Burger, 2022).
These advances demonstrate that zero-knowledge proof technology is not only an important breakthrough in the field of cryptography, but also a key driving force for realizing broader applications of blockchain technology, especially in improving privacy protection and processing capabilities (Zhou et al., 2022).
Therefore, we decided to systematically organize the relevant knowledge of zero-knowledge proof (ZKP) to better assist us in making future investment decisions. To this end, we comprehensively reviewed the core academic papers related to ZKP (sorted by relevance and number of citations); at the same time, we also analyzed in detail the materials and white papers of leading projects in this field (sorted by their financing scale). This comprehensive data collection and analysis provides a solid foundation for the writing of this article.
In 1985, scholars Goldwasser, Micali and Rackoff first proposed zero-knowledge proof (Zero-Knowledge Proof, ZKP) and interactive knowledge proof (InteractiveZero-Knowledge, IZK) in the paper The Knowledge Complexity of Interactive Proof-Systems. This paper is the foundation of zero-knowledge proof and defines many concepts that have influenced subsequent academic research. For example, the definition of knowledge is the output of unfeasible computation, that is, knowledge must be an output and an unfeasible computation, which means that it cannot be a simple function but a complex function. Infeasible computation can usually be understood as an NP problem, that is, a problem whose solution can be verified in polynomial time. Polynomial time means that the running time of the algorithm can be expressed as a polynomial function of the input size. This is an important criterion for measuring the efficiency and feasibility of algorithms in computer science. Since the solution process of NP problems is complex, they are considered to be computationally infeasible; however, their verification process is relatively simple, so they are very suitable for zero-knowledge proof verification (Goldwasser, Micali Rackoff, 1985).
A classic example of an NP problem is the traveling salesman problem, where the shortest path to visit a series of cities and return to the starting point is found. While finding the shortest path can be difficult, given a path, verifying that the path is the shortest is relatively easy. This is because verifying the total distance of a specific path can be done in polynomial time.
Goldwasser et al. introduced the concept of knowledge complexity in their paper to quantify the amount of knowledge leaked by the prover to the verifier in an interactive proof system. They also proposed an interactive proof system (IPS), in which the prover and the verifier prove the truth of a statement through multiple rounds of interaction (Goldwasser, Micali Rackoff, 1985).
In summary, the definition of zero-knowledge proof summarized by Goldwasser et al. is a special interactive proof in which the verifier does not obtain any additional information except the truth value of the statement during the verification process; and three basic characteristics are proposed, including:
Completeness: the fact that an honest prover can convince an honest verifier if the argument is true;
Soundness: If the prover does not know the content of the statement, he can deceive the verifier only with negligible probability;
Zero-knowledge: After the proof process is completed, the verifier only obtains the information that the prover has this knowledge and cannot obtain any additional content (Goldwasser, Micali Rackoff, 1985).
To better understand zero-knowledge proofs and their properties, here is an example of verifying that a prover has some private information in three stages: setup, challenge, and response.
Step 1: Setup
In this step, the provers goal is to create a proof that he knows a secret number s without directly revealing s. Let the secret number be;
Choose two large prime numbers p and q, and calculate their product . Let the prime numbers and , calculated;
Compute,Here,v is sent to the verifier as part of the proof, but it is not sufficient for the verifier or any bystander to infer s. ;
Randomly select an integer r, calculate and send it to the verifier. This value x is used in the subsequent verification process, but s is also not exposed. Let the random integer be calculated.
Step 2: Challenge
The verifier randomly selects a bit a (which can be 0 or 1) and sends it to the prover. This challenge determines the next steps the prover needs to take.
Step 3: Response
Based on the value a sent by the verifier, the prover responds:
If , the prover sends (here r is a number he chose randomly before).
If, the prover calculates and sends. Let the random bit sent by the verifier, according to the value of a, the prover calculates;
Finally, the verifier verifies whether it is equal to g according to the received g. If the equality is established, the verifier accepts this proof. When , the verifier calculates the verifier calculation, and verifies the right side; when , the verifier calculates the verifier calculation, and verifies the right side.
Here, we see that the verifier calculated that the prover successfully passed the verification process without revealing his secret number s. Here, since a can only be 0 or 1, there are only two possibilities, the probability of the prover passing the verification by luck (when a is 0). But the verifier then challenges the prover again, and the prover keeps changing the relevant numbers and submitting them to the verifier, and always successfully passes the verification process. In this way, the probability of the prover passing the verification by luck (infinitely close to 0), and the conclusion that the prover does know a secret number s is proved. This example proves the integrity, reliability and zero-knowledge of the zero-knowledge proof system (Fiat Shamir, 1986).
Zero-knowledge proof (ZKP) is usually an interactive and online protocol in the traditional concept; for example, the Sigma protocol usually requires three to five rounds of interaction to complete the authentication (Fiat Shamir, 1986). However, in scenarios such as instant transactions or voting, there is often no opportunity for multiple rounds of interaction, especially in blockchain technology applications, offline verification functions are particularly important (Sun et al., 2021).
In 1988, Blum, Feldman, and Micali first proposed the concept of non-interactive zero-knowledge (NIZK) proof, proving the possibility that the prover and the verifier can complete the authentication process without multiple rounds of interaction. This breakthrough makes instant transactions, voting, and blockchain applications feasible (Blum, Feldman Micali, 1988).
They proposed that non-interactive zero-knowledge proof (NIZK) can be divided into three stages:
set up
calculate
verify
The setup phase uses a computation function to convert the security parameters into public knowledge (available to both the prover and the verifier), usually encoded in a common reference string (CRS). This is how the proof is computed and verified using the correct parameters and algorithm.
The calculation phase uses the calculation function, input and proof key, and outputs the calculation result and proof.
In the verification phase, the validity of the proof is verified by verifying the key.
The common reference string (CRS) model they proposed is a non-interactive zero-knowledge proof that implements NP problems based on a string shared by all participants. The operation of this model relies on the trusted generation of CRS, and all participants must have access to the same string. The scheme implemented according to this model can only ensure security if the CRS is generated correctly and securely. For a large number of participants, the generation process of CRS can be complex and time-consuming, so although such schemes are generally easy to operate and have a small proof size, their setup process is quite challenging (Blum, Feldman Micali, 1988).
Subsequently, NIZK technology has experienced rapid development, and a variety of methods have emerged to transform interactive zero-knowledge proofs into non-interactive proofs. These methods differ in the construction of the system or the assumptions of the underlying encryption model.
Fiat-Shamir Transformation, also known as Fiat-Shamir Heurisitc (heuristic), or Fiat-Shamir Paradigm (paradigm); proposed by Fiat and Shamir in 1986, is a method that can convert interactive zero-knowledge proofs into non-interactive ones. This method reduces the number of interactions by introducing hash functions, and relies on security assumptions to ensure the authenticity of the proof and its difficult-to-forge properties. Fiat-Shamir Transformation uses public cryptographic hash functions to replace some randomness and interactivity, and its output can be regarded as CRS to some extent. Although this protocol is considered secure in the random oracle model, it relies on the assumption that the hash function output is uniformly random and independent of different inputs (Fiat Shamir, 1986). Canetti, Goldreich, and Halevis research in 2003 showed that although this assumption is valid in theoretical models, it may encounter challenges in practical applications, so there is a risk of failure when used (Canetti, Goldreich Halevi, 2003). Micali later improved this method by compressing multiple rounds of interaction into a single round, further simplifying the interaction process (Micali, 1994).
Jens Groths subsequent research has greatly promoted the application of zero-knowledge proofs in cryptography and blockchain technology. In 2005, he, Ostrovsky and Sahai jointly proposed the first perfect non-interactive zero-knowledge proof system applicable to any NP language, which can guarantee universal combinatorial security (UC) even in the face of dynamic/adaptive adversaries. In addition, they used the number theory complexity assumption to design a concise and efficient non-interactive zero-knowledge proof system, which significantly reduced the size of CRS and proofs (Groth Sahai, 2005).
In 2007, Groth, Cramer and Damgård began to commercialize these technologies. Through experimental verification, their public key encryption and signature schemes have significantly improved efficiency and security, although these schemes are based on the assumption of bilinear groups (Groth Sahai, 2007). In 2011, Groth further explored how to combine fully homomorphic encryption with non-interactive zero-knowledge proofs and proposed a scheme to reduce communication overhead, making the size of NIZK consistent with the size of the proof witness (Groth, 2011). In the following years, he and other researchers have further studied pairing-based techniques, providing compact and efficient non-interactive proofs for large-scale statements, although these proofs still do not leave the bilinear group framework (Bayer Groth, 2012; Groth, Kohlweiss Pintore, 2016; Bootle, Cerulli, Chaidos, Groth Petit, 2015; Groth, Ostrovsky Sahai, 2012; Groth Maller, 2017).
In specific application scenarios, non-interactive zero-knowledge proofs for specific verifiers have shown their unique practical value. For example, Cramer and Shoup used a public key encryption scheme based on a universal hash function to effectively resist selective ciphertext attacks in 1998 and 2002. In addition, in the key registration model, a new non-interactive zero-knowledge proof method was successfully developed, which is suitable for solving all NP-class problems. The key is that participants need to register their own keys for subsequent verification (Cramer Shou, 1998, 2002).
In addition, Damgård, Fazio, and Nicolosi proposed a new method to improve the existing Fiat-Shamir transformation in 2006, allowing non-interactive zero-knowledge proofs without direct interaction. In their method, the verifier first needs to register a public key to prepare for subsequent encryption operations. The prover uses additive homomorphic encryption technology to operate on the data without knowing it and generate encrypted information containing the answer as a response to the challenge. The security of this method is based on the complexity leverage hypothesis, which believes that for opponents with extraordinary computing resources, some computational problems that are considered difficult to solve may be solved (Damgård, Fazio Nicolosi, 2006).
The concept of weakly attributable reliability proposed by Ventre and Visconti in 2009 is an alternative to this assumption. It requires that when an adversary presents a false proof, he must not only be aware of its falsity, but also be clear about how he successfully fabricated the false proof. This requirement significantly increases the difficulty of deception because the adversary must be clear about his means of deception. In practice, an adversary using this concept needs to provide a specific proof that contains ciphertext information for a specified verifier. It is difficult to complete the proof without the private key of the verifier, so that when the adversary attempts to forge a proof, his behavior is exposed through detection (Ventre and Visconti, 2009).
The Unruh transform is an alternative to the Fiat-Shamir transform proposed in 2015. The Fiat-Shamir method is generally not safe against quantum computation and can produce insecure schemes for some protocols (Unruh, 2015). In contrast, the Unruh transform provides non-interactive zero-knowledge proofs (NIZKs) that are provably secure against quantum adversaries for any interactive protocol in the random oracle model (ROM). Similar to the Fiat-Shamir method, the Unruh transform does not require additional setup steps (Ambainis, Rosmanis Unruh, 2014).
In addition, Kalai et al. proposed an argumentation system for arbitrary decision problems based on private information retrieval technology. This method adopts the multi-prover interactive proof system (MIP) model and converts MIP into an argumentation system through the method of Aiello et al. This construction runs in the standard model and does not need to rely on the random oracle assumption. This method has been applied to some zero-knowledge arguments based on Proofs-for-Muggles (Kalai, Raz Rothblum, 2014).
Based on these technologies, non-interactive zero-knowledge proofs (NIZK) have been widely used in various fields that require high security and privacy protection, such as financial transactions, electronic voting, and blockchain technology. By reducing the number of interactions and optimizing the proof generation and verification process, NIZK not only improves the efficiency of the system, but also enhances security and privacy protection capabilities. In the future, with the further development and improvement of these technologies, we can expect NIZK to play an important role in more fields and provide a solid technical foundation for more secure and efficient information processing and transmission (Partala, Nguyen Pirttikangas, 2020).
In the field of cryptography, the traditional Turing machine model shows certain limitations, especially when dealing with tasks that require high parallelization and specific types of computing (such as large-scale matrix operations). The Turing machine model needs to simulate infinitely long paper tapes through complex memory management mechanisms, and is not suitable for directly expressing parallel computing and pipeline operations. In contrast, the circuit model, with its unique computing structure advantages, is more suitable for certain specific cryptographic processing tasks (Chaidos, 2017). This article will discuss in detail the circuit-based zero-knowledge proof system (Zero-Knowledge Proof Systems Based on Circuit Models), which places special emphasis on the use of circuits (usually arithmetic circuits or Boolean circuits) to express and verify the computing process.
In the circuit-based computing model, a circuit is defined as a special computing model that can convert any computing process into a series of gates and wires that perform specific logical or arithmetic operations. Specifically, circuit models are mainly divided into two categories:
Arithmetic circuits: They are mainly composed of addition and multiplication gates and are used to process elements over finite fields. Arithmetic circuits are suitable for performing complex numerical operations and are widely used in encryption algorithms and numerical analysis.
Logic circuit: It is composed of basic logic gates such as AND gate, OR gate, NOT gate, etc., and is used to process Boolean operations. Logic circuits are suitable for performing simple judgment logic and binary calculations, and are often used to implement various control systems and simple data processing tasks (Chaidos, 2017).
In a zero-knowledge proof system, the process of circuit design involves expressing the problem to be proved as a circuit. This process requires a lot of reverse thinking to design zk circuits: If the claimed output of a computation is true, the output must satisfy certain requirements. If these requirements are difficult to model with just addition or multiplication, we ask the prover to do extra work so that we can more easily model these requirements. The design process usually follows these steps (Chaidos, 2017):
Problem representation: First, convert the problem to be proved, such as the calculation process of cryptographic hash functions, into the form of a circuit. This includes decomposing the calculation steps into basic units in the circuit, such as gates and wires.
Circuit optimization: Through technical means such as gate merging and constant folding, the circuit design is optimized to reduce the number of gates and calculation steps required, thereby improving the operating efficiency and response speed of the system.
Convert to polynomial representation: To adapt to zero-knowledge proof technology, the optimized circuit is further converted to polynomial form. Each circuit element and connection corresponds to a specific polynomial constraint.
Generate a Common Reference String (CRS): During the system initialization phase, a common reference string including a proof key and a verification key is generated for use in the subsequent proof generation and verification process.
Proof generation and verification: The prover performs computation on the circuit based on its private input and CRS to generate a zero-knowledge proof. The verifier can verify the correctness of the proof based on the public circuit description and CRS without knowing the provers private information (Chaidos, 2017).
Zero-knowledge proof circuit design involves converting a specific computational process into a circuit representation and ensuring the accuracy of the computational results by constructing polynomial constraints while avoiding the disclosure of any additional personal information. In circuit design, the key task is to optimize the structure of the circuit and generate an effective polynomial representation in order to improve the efficiency of proof generation and verification. Through these steps, zero-knowledge proof technology can verify the correctness of the calculation without leaking additional information, ensuring that the dual needs of privacy protection and data security are met (Chaidos, 2017).
Disadvantages include:
Circuit complexity and scale: Complex computations require large circuits, which significantly increases the computational cost of proof generation and verification, especially when dealing with large-scale data;
Difficulty of optimization: Although technical means (such as gate merging, constant folding, etc.) can optimize circuits, designing and optimizing efficient circuits still requires deep expertise;
Adaptability to specific computing tasks: Different computing tasks require different circuit designs. Designing efficient circuits for each specific task can be time-consuming and difficult to generalize.
Difficulty in implementing cryptographic algorithms: Implementing complex cryptographic algorithms (such as hash functions or public key encryption) may require a large number of logic gates, making circuit design and implementation difficult;
Resource consumption: Large-scale circuits require a lot of hardware resources and may encounter bottlenecks in actual hardware implementation in terms of power consumption, heat, and physical space (Goldreich, 2004; Chaidos, 2017; Partala, Nguyen, Pirttikangas, 2020; Sun et al., 2021).
Solutions and improvement directions:
Circuit compression technology: Reduce the number of logic gates and computing resources required by studying and applying efficient circuit compression technology;
Modular design: By designing circuits in a modular way, the reusability and scalability of circuit design can be improved, and the workload of redesigning circuits for different tasks can be reduced;
Hardware acceleration: Using specialized hardware (such as FPGA or ASIC) to accelerate circuit computation and improve the overall performance of zero-knowledge proofs (Goldreich, 2004; Chaidos, 2017; Partala, Nguyen Pirttikangas, 2020; Sun et al., 2021).
Circuit-based zero-knowledge proofs have poor versatility and require the development of new models and algorithms for specific problems. There are a variety of high-level language compilers and low-level circuit combination tools to generate circuits and design algorithms. The conversion of related calculations can be completed by manual circuit construction tools or automatic compilers. Manual conversion usually produces more optimized circuits, while automatic conversion is more convenient for developers. Performance-critical applications usually require manual conversion tools (Chaidos, 2017; Partala, Nguyen Pirttikangas, 2020; Sun et al., 2021).
This article will discuss the most notable ones. In general, these models are extensions or variations of zkSNARKs technology, each trying to provide optimizations in specific application requirements (such as proof size, computational complexity, setup requirements, etc.).
Each protocol has its specific applications, advantages, and limitations, especially in terms of setup requirements, proof size, verification speed, and computational overhead. They are used in various fields, ranging from cryptocurrency privacy and secure voting systems to general computation verified in a zero-knowledge manner (Čapko, Vukmirović Nedić, 2019).
1. zkSNARK model: In 2011, cryptographer Bitansky et al. proposed zkSNARK as an abbreviation of Zero-Knowledge Succinct Non-Interactive Argument of Knowledge. It is an improved zero-knowledge proof mechanism. If there is an extractable collision-resistant hash (ECRH) function, it is possible to implement SNARK for NP problems. It also demonstrates the applicability of SNARK in various scenarios such as computational delegation, succinct non-interactive zero-knowledge proof, and succinct two-party secure computation. This study also shows that the existence of SNARK implies the necessity of ECRH, establishing the fundamental connection between these cryptographic primitives (Bitansky et al., 2011).
The zkSNARK system consists of three parts: setup, prover, and verifier. The setup process generates a proving key (PK) and a verification key (VK) using predefined security parameters l and an F-arithmetic circuit C. All inputs and outputs of this circuit are elements in the field F. PK is used to generate verifiable proofs, while VK is used to verify the generated proofs. Based on the generated PK, the prover generates a proof p using input x ∈ Fn and witness W ∈ Fh, where C(x, W) = 0 l. Here, C(x, W) = 0 l means that the output of circuit C is 0 l, and x and W are the input parameters of circuit C. n, h, and l represent the dimensions of the output of x, W, and C, respectively. Finally, the verifier uses VK, x, and p to verify p, and decides to accept or reject the proof based on the verification result (Bitanskyet al., 2011).
In addition, zkSNARKs have some additional features. First, the verification process can be completed in a short time, and the size of the proof is usually only a few bytes. Second, there is no need for synchronous communication between the prover and the verifier, and any verifier can verify the proof offline. Finally, the prover algorithm can only be implemented in polynomial time. Since then, a variety of improved zkSNARK models have emerged, further optimizing its performance and application scope (Bitanskyet al., 2011).
2. Ben-Sassons model: Ben-Sasson et al. proposed a new zkSNARK model for program execution on von Neumann RISC architecture in 2013 and 2014. Then, based on the proposed universal circuit generator, Ben-Sasson et al. built a system and demonstrated its application in verifying program execution. The system consists of two components: a cryptographic proof system for verifying the satisfiability of arithmetic circuits, and a circuit generator that converts program execution into arithmetic circuits. The design is superior to previous work in terms of functionality and efficiency, especially the universality of the circuit generator and the additive dependence of the output circuit size. Experimental evaluation shows that the system can process programs of up to 10,000 instructions and generate concise proofs at a high security level with a verification time of only 5 milliseconds. Its value lies in providing an efficient, universal and secure zk-SNARKs solution for practical applications such as blockchain and privacy-preserving smart contracts (Ben-Sasson et al., 2013, 2014).
3. Pinocchio model: Parno et al. (2013) proposed a complete non-interactive zero-knowledge argument generation suite (Parno etal., 2013). It includes a high-level compiler that provides developers with an easy way to convert computations into circuits. These compilers accept code written in high-level languages, so both new and old algorithms can be easily converted. However, there may be some restrictions on the code structure to generate circuits of appropriate size.
Another feature of Pinocchio is the use of a mathematical structure called Quadratic Arithmetic Programs (QAPs), which can efficiently convert computational tasks into verification tasks. QAPs can encode arbitrary arithmetic circuits as sets of polynomials, and only linear time and space complexity are required to generate these polynomials. The proof size generated by Pinocchio is 288 bytes, which does not change with the complexity of the computational task and the input and output size. This greatly reduces the overhead of data transmission and storage. Pinocchios verification time is typically 10 milliseconds, which is 5-7 orders of magnitude less than previous work. For some applications, Pinocchio can even achieve faster verification speeds than local execution. Reduce worker proof overhead: Pinocchio also reduces the workers overhead of generating proofs, which is 19-60 times less than previous work (Parno et al., 2013).
4. Bulletproofs model: In 2017, Benedikt Bünz et al. (2018) designed a new non-interactive ZKP model. No trusted setup is required, and the proof size grows logarithmically with the size of the witness value. Bulletproofs is particularly suitable for interval proofs in confidential transactions, and can prove that a value is within a certain range by using the minimum number of group and field elements. In addition, Bulletproofs also supports the aggregation of interval proofs, so that a single proof can be generated through a concise multi-party computing protocol, greatly reducing communication and verification time. The design of Bulletproofs makes it highly efficient and practical in distributed and trustless environments such as cryptocurrencies. Bulletproofs are not strictly traditional circuit-based protocols. They are not as concise as SNARKs, and it takes longer to verify Bulletproofs than to verify SNARK proofs. But it is more efficient in scenarios where a trusted setup is not required.
5. Ligero model: A lightweight zero-knowledge proof model proposed by Ames et al. (2017). The communication complexity of Ligero is proportional to the square root of the size of the verification circuit. In addition, Ligero can rely on any collision-resistant hash function. In addition, Ligero can be a zkSNARK scheme in the random oracle model. This model does not require a trusted setup or public key cryptosystem. Ligero can be used for very large verification circuits. At the same time, it is suitable for moderately large circuits in applications.
Ishai and Paskin (2007) proposed using additive homomorphic public key encryption to reduce the communication complexity of interactive linear PCP. Subsequently, Groth et al. published several studies from 2006 to 2008 and proposed the NIZK scheme based on the discrete logarithm problem and bilinear pairing, which achieved perfect completeness, computational correctness and perfect zero knowledge. The scheme represents the statement as an algebraic constraint satisfaction problem, and uses a cryptographic commitment scheme similar to the Pedersen commitment to achieve sublinear proof length and non-interactivity without the need for the Fiat-Shamir heuristic. Although a large CRS and strong cryptographic assumptions of exponential knowledge are required, a sufficiently long CRS can achieve a constant proof length. The verification and proof costs are high, and it is recommended to adopt the simulated extractability security model. This type of scheme is based on linear PCP and/or discrete logarithm problems, but neither has quantum security (Groth, 2006, 2006, 2008; Groth Sahai, 2007).
6. Groth 16 model: It is an efficient non-interactive zero-knowledge proof system proposed by Jens Groth in 2016. The protocol is based on elliptic curve pairing and quadratic arithmetic program (QAP), aiming to provide concise, fast and secure zero-knowledge proof.
7. Sonic model: M. Maller et al. (2019) proposed a Groth-based updatable CRS model using a polynomial commitment scheme, pairing, and arithmetic circuits. A trusted setup is required, which can be implemented through secure multi-party computation. Once the CRS is generated, it supports circuits of arbitrary size.
8. PLONK model: A general zk-SNARK proposed in 2019, which uses permutation polynomials to simplify arithmetic circuit representation, making proofs simpler and more efficient; it is versatile and supports recursive proof combination (Gabizon, Williamson Ciobotaru, 2019). The PLONK model claims to reduce the proof length of Sonic and improve the proof efficiency, but has not yet passed peer review.
9. Marlin model: An improved zk-SNARK protocol that combines the efficiency of algebraic proof systems with the universal and updatable setting properties of Sonic and PLONK, providing improvements in proof size and verification time (Chiesa et al., 2019).
10. SLONK model: A new protocol introduced by Zac and Ariel in a paper on ethresear, an extension of PLONK that aims to solve specific computational efficiency problems and enhance the functionality of the original PLONK system, usually involving changes in underlying cryptographic assumptions or implementations (Ethereum Research, 2019).
11. SuperSonic model: A novel polynomial commitment scheme is used to transform Sonic into a zero-knowledge scheme that does not require a trusted setup. It is not quantum-safe (Bünz, Fisch Szepieniec, 2019).
Proofs-for-Muggles is a new zero-knowledge proof method proposed by Goldwasser, Kalai, and Rothblum in 2008. This method constructs interactive proofs for polynomial-time provers in the original interactive proof model and is applicable to a wide range of problems. Through the transformation of Kalai et al., these proofs can be turned into non-interactive zero-knowledge proofs (Kalai, Raz Rothblum, 2014).
12. Hyrax model: Based on ordinary peoples proof, Wahby et al. (2018) first designed a low-communication, low-cost zero-knowledge proof scheme Hyrax, which is low cost for provers and verifiers. In this scheme, there is no trusted setup in this proof. If applied to batch statements, the verification time has a sublinear relationship with the arithmetic circuit size, and the constant is very good. The running time of the prover is linear with the arithmetic circuit size, and the constant is also very good. Non-interactivity is achieved using the Fiat-Shamir heuristic, based on the discrete logarithm problem, and quantum security is not achieved.
13. Libra model: The first ZKP model with linear prover time, concise proof size, and verification time. In Libra, in order to reduce the verification overhead, the zero-knowledge mechanism is implemented through a method that can mask the provers response with a slightly random polynomial. In addition, Libra requires a one-time trusted setup, which only depends on the input size of the circuit. Libra has excellent asymptotic performance and excellent efficiency of the prover. Its performance in proof size and verification time is also very efficient (Xie et al., 2019).
In terms of the computational complexity of the prover algorithm, Libra outperforms Ben-Sassons model, Ligero, Hyrax, and Aurora. In addition, the computational complexity of Libras prover algorithm is independent of the circuit type (Partala, Nguyen Pirttikangas, 2020).
14. Spartan model: A zero-knowledge proof system proposed by Srinath Setty (2019) that aims to provide efficient proofs without the need for a trusted setup; it uses the Fiat-Shamir transformation to achieve non-interactivity. It is known for its lightweight design and ability to efficiently handle large circuits.
Kilian (1992) constructed the first interactive zero-knowledge argument scheme for NP, implementing polylogarithmic communication. The scheme used collision-resistant hash functions, interactive proof systems (IP), and probabilistically checkable proofs (PCP). The prover and the verifier (as a randomized algorithm) communicate through multiple rounds, and the verifier tests the provers knowledge of the statement. Usually only one-sided faults are considered: the prover can always defend a true statement, but the verifier may accept a false statement with low probability. In 2000, Micali used the Fiat-Shamir transformation to transform the scheme into a single-message non-interactive scheme. The following implementation can be considered to adopt this approach:
15. STARK model: In 2018, ZK-STARKs (Scalable Transparent ARgument of Knowledge) technology was proposed by Ben-Sasson et al. to solve the inefficiency of zk-SNARKs in processing complex proofs. At the same time, it solves the problem of verifying the integrity of computations on private data, and can provide transparent and post-quantum secure proofs without relying on any trusted party.
In the same year, Ben-Sasson and others founded StarkWareIndustries and developed the first scalability solution StarkEx based on ZK-STARKs. According to Ethereums official documentation, it can achieve non-interactivity in the random oracle model through the Fiat-Shamir paradigm. This construction is quantum-resistant, but its security relies on non-standard cryptographic assumptions about Reed-Solomon codes. ZK-STARKs has the same characteristics as ZK-SNARKs, but includes the following advantages: a) Scalability: The verification process is faster. Transparency: The verification process is public. Larger proof size: requires higher transaction fees (StarkWare Industries, 2018, 2018)
16. Aurora model: Ben-Sasson et al. (2019) proposed a succinct non-interactive argument based on STARK (SNARG). The non-interactivity is based on the Fiat-Shamir construction. It applies to the satisfiability of arithmetic circuits. The argument size of Aurora is polylogarithmically related to the circuit size. In addition, Aurora has several attractive features. In Aurora, there is a transparent setting. There is no effective quantum computing attack that can crack Aurora. In addition, fast symmetric encryption is used as a black box. Aurora optimizes the proof size. For example, if the security parameter is 128 bits, the proof size of Aurora is at most 250 kilobytes. Aurora and Ligero optimize the proof size and computational overhead, making them very suitable for zero-knowledge proofs on resource-limited devices. These optimizations not only improve efficiency, but also expand the scope of application of zero-knowledge proof technology, enabling it to be applied in more practical scenarios.
17. Succinct Aurora Model: Ben-Sasson et al. (2019) proposed in the same paper: An extension of the Aurora protocol that provides a more optimized proof size and verification process. It maintains Aurora’s transparent setup and security features while enhancing efficiency.
18. Fractal Model: Chiesa et al. (2020) proposed a preprocessing SNARK that uses recursive composition to improve efficiency and scalability. It takes advantage of logarithmic proof size and verification time, and is particularly suitable for complex computations.
Generation 1 (G 1) – Each circuit requires a separate trusted setup. zkSNARK, Pinocchio and Groth 16
Generation 2 (G 2) – initially set once for all circuits. PlonK, Sonic, Marlin, Slonk and Libra
Third generation (G 3) – proof systems that do not require a trusted setup. Bulletproofs, STARKs, Spartan, Fractal, Supersonic, Ligero, Aurora and SuccinctAurora (Čapko, Vukmirović Nedić, 2019; Partala, Nguyen Pirttikangas, 2020).
The previous part is more about the development of zero-knowledge proof ZKP in cryptography. Next, we will briefly introduce its development in the computer field.
In 2019, Andreev et al. first proposed the concept of ZK-VM at the ZkVM: Fast, Private, Flexible Blockchain Contracts conference as a way to implement a zero-knowledge proof system. The goal of ZK-VM is to generate zero-knowledge proofs by running virtual machine programs to verify the correctness of program execution without leaking input data.
VM (Virtual Machine) is a software-simulated computer system that can execute programs, similar to a physical computer. VMs are often used to create independent operating system environments, perform software testing and development, etc. VM or VM abstraction can be equivalent to CPU abstraction in most cases. It refers to the abstraction of the complex operations and architecture of the computers processing unit (CPU) into a set of simple, operational instruction set architectures (ISA) to simplify the design and execution of computer programs. In this abstraction, computer programs can be run through virtual machines (VMs) that simulate the operating behavior of real CPUs (Henderson, 2007).
Zero-knowledge proofs (ZKPs) often require execution via CPU abstraction. The setting is that the prover runs a public program on private inputs and wants to prove to the verifier that the program executed correctly and produced the asserted output, without revealing the inputs or intermediate states of the computation. CPU abstraction is very useful in this context because it allows the program to be run in a controlled virtual environment while generating proofs (Arun, Setty Thaler, 2024).
Example: The prover wishes to prove that he possesses a hashed password without revealing the password:
Password → Hash function → Hash value
Private → Public
In general, the prover should be able to run code that performs the hashing operation and produce a proof that allows anyone to verify the correctness of the proof, i.e., that the prover does have a valid preimage for a given hash value.
Systems that generate these VM abstract proofs are often called zkVMs. This name is actually misleading because ZKVM does not necessarily provide zero knowledge. In short, ZKVM is a virtual machine focused on zero-knowledge proofs, which extends the functionality of traditional VMs, can generally lower the threshold for the development of zero-knowledge circuits, and can instantly generate proofs for any application or calculation (Zhang et al., 2023).
According to the design goals, it is mainly divided into three categories:
1. Mainstream ZKVM
These ZKVMs leverage existing standard instruction set architectures (ISAs) and compiler toolchains, making them suitable for a wide range of applications and development environments.
RISCZero (2021): uses the RISC-V instruction set and has a rich compiler ecosystem (Bögli, 2024).
PolygonMiden (2021): Based on standard ISA, it enables simple and efficient development (Chawla, 2021).
zkWASM (2022): zkWASM implements zero-knowledge proofs for the WebAssembly (WASM) instruction set, a widely adopted standard instruction set (DelphinusLab, 2022).
2. EVM-equivalent ZKVM
These ZKVMs are specifically designed to be compatible with the Ethereum Virtual Machine (EVM) and are able to run Ethereum’s bytecode directly.
zkEVM projects: Several projects are working on achieving bytecode-level compatibility with the EVM, such as zkSync (MatterLabs, 2020) and Polygon Hermez (Polygon Labs, 2021).
3. Zero-knowledge-optimized (zero-knowledge-friendly) ZKVM
These ZKVMs optimize the efficiency and performance of zero-knowledge proofs and are designed for specific application scenarios.
Cairo-VM (2018): Simple and compatible with SNARK proofs, its instruction set is specially designed to be arithmetic-friendly, making it easy to implement basic arithmetic operations such as addition, multiplication, etc. in zero-knowledge circuits (StarkWare, 2018).
Valida (2023): Optimized for specific applications, such as reducing the computing resources and time required to generate proofs by optimizing algorithms; its lightweight design makes it suitable for a variety of hardware and software environments (LitaFoundation, 2023).
TinyRAM (2013): Not dependent on standard toolchains: Due to its simplified and optimized design, it is generally not supported by LLVM or GCC toolchains and can only be used for small-scale custom software components (Ben-Sasson et al., 2013).
The prevailing view is that simpler VMs can be transformed into circuits with fewer gates per step. This is most evident in the design of particularly simple and apparently SNARK-friendly VMs such as TinyRAM and Cairo-VM. However, this comes with additional overhead, as implementing the primitive operations of a real-world CPU on a simple VM requires many primitive instructions (Arun, Setty, Thaler, 2024).
From the perspective of programming, ZKP systems can generally be divided into two parts: the frontend and the backend. The frontend part of the ZKP system mainly uses low-level languages to represent high-level languages. For example, a general computational problem can be represented using a lower-level circuit language, such as R 1 CS circuit constraints to construct computations (for example, circom uses R 1 CS to describe its frontend circuit). The backend part of the ZKP system is the cryptographic proof system, which mainly converts the circuit described by the low-level language constructed by the frontend into generating proofs and verifying correctness. For example, commonly used backend system protocols include Groth 16 and Plonk (Arun, Setty Thaler, 2024; Zhang et al., 2023).
Typically, the circuit will incrementally “execute” each step of a computational program (with the help of untrusted “suggested input”). Executing a CPU step conceptually involves two tasks: (1) identifying the basic instructions that should be executed for that step, and (2) executing the instructions and updating the CPU state appropriately. Existing front ends implement these tasks via carefully designed gates or constraints. This is time-consuming and error-prone, and also results in circuits that are much larger than they actually need to be (Arun, Setty, Thaler, 2024; Zhang et al., 2023).
advantage:
Leverage existing ISAs: For example, RISC-V and EVM instruction sets can leverage existing compiler infrastructure and toolchains, without having to build infrastructure from scratch. Existing compilers can be directly called to convert witness check programs written in high-level languages into assembly code for the ISA and benefit from previous audits or other verification work.
Single circuit supports multiple programs: zkVM allows one circuit to run all programs until a certain time limit is reached, while other approaches may need to re-run the front end for each program.
Circuits with repetitive structures: The front-end outputs circuits with repetitive structures, which the back-end can process faster (Arun, Setty, Thaler, 2024; Zhang et al., 2023).
shortcoming:
Cost of universality: In order to support all possible CPU instruction sequences, zkVM circuits need to pay the price for their universality, resulting in an increase in circuit size and proof cost.
Expensive operations: Some important operations, such as cryptographic operations, are very expensive to implement in zkVM. For example, ECDSA signature verification takes 100 microseconds on a real CPU and millions of instructions on RISC-V. Therefore, the zkVM project contains hand-optimized circuits and lookup tables for computing specific functions.
High proof cost: Even for very simple ISAs, the prover cost of existing zkVMs is still very high. For example, the prover of Cairo-VM needs to encrypt and submit 51 domain elements per step, which means that executing one original instruction may require millions of instructions on a real CPU, limiting its applicability in complex applications (Arun, Setty, Thaler, 2024; Zhang et al., 2023).
ZKEVM (Zero-Knowledge Ethereum Virtual Machine) and ZKVM (Zero-Knowledge Virtual Machine) are both virtual machines that apply zero-knowledge proof (ZKP) technology. The Ethereum Virtual Machine (EVM) is part of the Ethereum blockchain system and is responsible for handling the deployment and execution of smart contracts. EVM has a stack-based architecture and is a computational engine that provides computation and storage of a specific set of instructions (such as log operations, execution, memory and storage access, control flow, logging, calling, etc.). The role of EVM is to update the state of Ethereum after applying the operations of smart contracts. ZKEVM is designed specifically for Ethereum and is mainly used to verify the correctness of smart contract execution while protecting transaction privacy. ZKEVM converts the EVM instruction set into the ZK system for execution, and each instruction requires proof, including state proof and execution correctness proof (Čapko, Vukmirović Nedić, 2019).
The current mainstream solutions for ZKEVM include STARKWARE, ZkSync, Polygen-Hermez, Scroll, etc. The following is a brief introduction to these projects (Čapko, Vukmirović Nedić, 2019):
STARKWARE: Founded by Ben-Sasson et al. (2018), dedicated to using STARK zero-knowledge proof technology to improve the privacy and scalability of blockchain
zkSync: Founded by Alex Gluchowski (2020) and others, Matter Labs proposed an Ethereum Layer 2 scaling solution based on zk-rollups.
Polygon-Hermez: Hermez was originally an independent project and was released in 2020. After being acquired by Polygon in August 2021, it became PolygonHermez, focusing on high-throughput zk-rollups solutions.
Scroll: Founded by Zhang and Peng (2021), it achieves higher transaction throughput and lower gas fees, thereby improving the overall performance and user experience of Ethereum.
Generally, they can be divided into the following categories according to the level of compatibility with EVM (Čapko, Vukmirović Nedić, 2019):
EVM-EVM-compatibility Smart contract function level compatibility, such as STARKWARE, zkSync
EVM-equivalence, EVM instruction level compatibility (equivalence), such as polygen-Hrmez, scroll
See Figure 1 for the improved solution of the Ethereum system based on zero knowledge
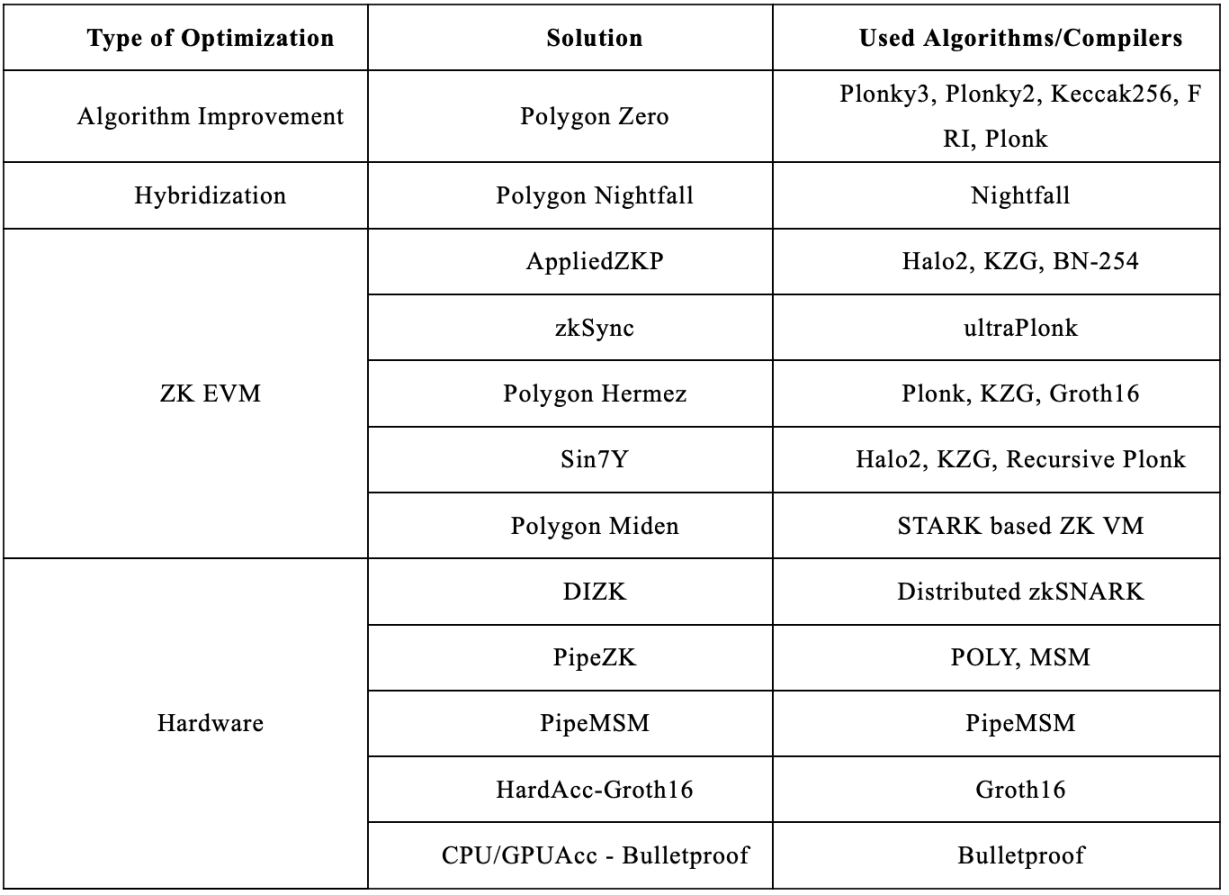
Figure 1 Ethereum system improvement solution based on zero knowledge
Node program processing: The node program processes and verifies execution logs, block headers, transactions, contract bytecodes, Merkle proofs, etc., and sends this data to zkEVM for processing.
Generate ZK proofs: zkEVM uses circuits to generate ZK proofs of execution results (state and execution correctness proofs). These circuit functions are mainly implemented using tables and special circuits.
Aggregate proofs: Use aggregate circuits to generate smaller proofs from large proofs, such as using recursive proofs.
Send to L1 contract: The aggregated proof is sent to the L1 contract in the form of a transaction for execution (Čapko, Vukmirović Nedić, 2019).
Get data: Get data from the Ethereum blockchain system, including transactions, block headers, contracts, etc.
Processing data: Processing and verifying execution logs, block headers, transactions, contract bytecode, Merkle proofs, etc.
Generate proof: Use circuits to generate ZK proofs to ensure the state update and execution correctness of each instruction.
Recursive proofs: Compress the generated large proof into smaller aggregate proofs.
Submit proof: Submit the aggregate proof to the L1 contract to complete the transaction verification (Čapko, Vukmirović Nedić, 2019).
Improve transaction processing capabilities: Execute transactions through ZKEVM on L2, reducing the load on L1.
Privacy protection: Protect transaction privacy while verifying smart contract execution.
Efficient Verification: Use zero-knowledge proof techniques to achieve efficient state and execution correctness verification (Čapko, Vukmirović Nedić, 2019).
The Ethereum blockchain is one of the most widely adopted blockchain ecosystems. However, Ethereum faces serious scalability issues, which makes it expensive to use. ZK Rollup is based on zero-knowledge proof (ZKP) and is a Layer 2 solution for Ethereum expansion. It overcomes the defect of OptimisticRollups transaction final confirmation time being too long (Ganguly, 2023).
ZK Rollup allows scalability within a single transaction. The smart contract on L1 is responsible for processing and verifying all transfers, ideally generating only one transaction. This is done by executing transactions off-chain to reduce the use of computing resources on Ethereum and putting the final signed transaction back on-chain. This step is called Validity Proof. In some cases, verification may not be completed within a single proof, and additional transactions are required to publish the data on the rollup to the Ethereum main chain to ensure the availability of the data (Ganguly, 2023).
In terms of space, using ZK Rollup improves efficiency since there is no need to store data like normal smart contracts. Each transaction only requires verification of the proof, which further confirms the minimization of data, making them cheaper and faster (Ganguly, 2023).
Although ZK Rollup contains the term ZK (zero-knowledge) in its name, they mainly utilize the simplicity of zero-knowledge proofs to improve the processing efficiency of blockchain transactions, rather than focusing primarily on privacy protection (Ganguly, 2023).
ZK Rollup (Zero Knowledge Rollup) is a Layer 2 solution for Ethereum scalability. Although it excels in improving transaction processing efficiency, its main problem is that the computational cost is very high. However, through some optimization solutions, the performance and feasibility of ZK Rollup can be significantly improved (Čapko, Vukmirović Nedić, 2019).
1. Optimize the calculation of cryptographic algorithms
Optimizing the computational process of cryptographic algorithms can improve the efficiency of ZK Rollup and reduce computing time and resource consumption. For example, Plonky 2, proposed by PolygonZero (formerly MIR), is a decentralized ZK Rollup solution. Plonky 2 is a recursive SNARK that is 100 times faster than other Ethereum-compatible alternatives and combines the best features of STARKs and SNARKs:
Plonk and FRI: Providing fast proofs without trustless setup.
Support recursion: Improve efficiency through recursive proof.
Low verification cost: Efficient proof is achieved by combining 64-bit recursive FRI with Plonk.
2. Hybrid Optimistic and ZK Rollup
For example, PolygonNightfall is a hybrid Rollup that combines features of Optimistic and ZK Rollups, aiming to increase transaction privacy and reduce transfer fees (up to 86%).
3. Develop a dedicated ZK EVM
The dedicated ZK EVM is designed to improve the ZK Rollup algorithm and optimize the zero-knowledge proof process. Here are a few specific solutions:
AppliedZKP: An open source project funded by the Ethereum Foundation that implements ZK for Ethereum EVM native opcodes, using cryptographic algorithms such as Halo 2, KZG, and Barreto-Naehrig (BN-254) elliptic curve pairing.
zkSync: zkEVM, developed by Matter Labs, is a custom EVM that implements the compilation of contract code into YUL (the intermediate language of the Solidity compiler) and then into supported custom bytecode, using ultraPlonk, an extended version of Plonk.
Polygon Hermez: Custom EVM-compatible decentralized Rollup that compiles contract code into supported microinstruction sets, using Plonk, KZG and Groth 16 proof systems.
Sin 7 Y zkEVM: Implements ZK of EVM native opcodes and optimizes specialized opcodes, using halo 2, KZG, and RecursivePlonk.
Polygon Miden: A universal zero-knowledge virtual machine based on STARK.
4. Hardware Optimization
Hardware optimization can significantly improve the performance of ZK Rollup. Here are several hardware optimization solutions:
DIZK (DIstributedZero Knowledge): Optimizes zkSNARK proofs by distributing them on a computing cluster. The hardware architecture includes two subsystems, one for polynomial computation (POLY) with large-scale number theoretic transforms (NTTs), and the other for performing multi-scalar multiplication (MSM) on elliptic curves (ECs). PipeMSM is a pipelined MSM algorithm for implementation on FPGAs.
FPGA-based ZKP hardware accelerator design: including multiple FFT (Fast Fourier Transform) units and decomposition of FFT operations, multiple MAC (Multiply-Add Circuit) units, and multiple ECP (Elliptic Curve Processing) units to reduce computational overhead. The FPGA-based zk-SNARK design reduces the proof time by about 10 times.
Hardware acceleration of the Bulletproof protocol: via a CPU-GPU collaboration framework and parallel Bulletproofs on GPU (Čapko, Vukmirović Nedić, 2019).
Zero-knowledge proof protocols (such as ZKSNARKs and ZKSTARKs) usually involve a large number of complex mathematical operations during execution, which need to be completed in a very short time, placing extremely high demands on computing resources (such as CPU and GPU), resulting in high computational complexity and long computation time. In addition, generating and verifying zero-knowledge proofs requires frequent access to large amounts of data, which places high demands on memory bandwidth. The limited memory bandwidth of modern computer systems cannot efficiently support such high-frequency data access requirements, resulting in performance bottlenecks. Ultimately, high computational loads lead to high energy consumption, especially in blockchains and decentralized applications, when a large number of proof calculations need to be performed continuously. Therefore, although software optimization solutions can partially alleviate these problems, it is difficult to achieve the high efficiency and low energy consumption levels of hardware acceleration due to the physical limitations of general-purpose computing hardware. Hybrid solutions can achieve higher performance improvements while maintaining flexibility (Zhang et al., 2021).
ZK-ASIC (Application Specific Integrated Circuit)
During 2020, several projects emerged, aiming to improve efficiency by accelerating the generation and verification process of zero-knowledge proofs (ZKP) through hardware such as GPUs or FPGAs (Filecoin, 2024; Coda, 2024; GPU groth 16 prover, 2024; Roy et al., 2019; Devlin, 2024; Javeed Wang, 2017).
2021: Zhang et al. proposed a zero-knowledge proof acceleration scheme based on a pipeline architecture, using the Pippenger algorithm to optimize multi-scalar multiplication (MSM) and reduce data transmission delay by unrolling the fast Fourier transform (FFT) (Zhang et al., 2021).
ZKCoprocessor
Axiom (2022) proposed the concept of ZKCoprocessor, or ZK coprocessor. A coprocessor is a separate chip that enhances the CPU and provides specialized operations such as floating-point operations, cryptographic operations, or graphics processing. Although the term is no longer commonly used as CPUs become more powerful, GPUs can still be considered a coprocessor for the CPU, especially in the context of machine learning.
The term ZK coprocessor extends the analogy of physical coprocessor chips to blockchain computation, allowing smart contract developers to statelessly prove off-chain computations on existing on-chain data. One of the biggest bottlenecks facing smart contract developers remains the high cost of on-chain computation. Since gas is calculated for each operation, the cost of complex application logic can quickly become prohibitive. ZK coprocessors introduce a new design pattern for on-chain applications, removing the limitation that computations must be done in the blockchain virtual machine. This enables applications to access more data and operate at a larger scale than before (Axiom, 2022).
Concepts of ZKML
Zero-Knowledge Machine Learning (ZKML) is an emerging field that applies zero-knowledge proof (ZKP) technology to machine learning. The core idea of ZKML is to allow machine learning calculation results to be verified without revealing data or model details. This not only protects data privacy, but also ensures the credibility and correctness of calculation results (Zhang et al., 2020).
The development of ZKML
In 2020, Zhang et al. systematically proposed the concept of ZKML for the first time at the 2020 CCS conference, demonstrating how to perform zero-knowledge proof of decision tree predictions without revealing data or model details. This laid the theoretical foundation for ZKML.
In 2022, Wang and Hoang further studied and implemented ZKML and proposed an efficient zero-knowledge machine learning reasoning pipeline, showing how to implement ZKML in real-world applications. The study showed that although ZKP technology is complex, through reasonable optimization, acceptable computing performance can be achieved while ensuring data privacy and computational correctness.
The concept of ZKThreads
In 2021, StarkWare proposed the concept of ZKThreads, which aims to combine zero-knowledge proof (ZKP) and sharding technology to provide scalability and customization for decentralized applications (DApps) without fragmentation problems. ZKThreads improves security and composability by directly falling back on the base layer to ensure real-time performance at every step.
ZKThreads has been optimized mainly in three aspects: single-chain structure, rollup liquidity issues, and Proto-Danksharding.
Single-chain solution: In the traditional single-chain architecture, all transactions are processed on one chain, resulting in excessive system load and poor scalability. ZKThreads significantly improves processing efficiency by distributing data and computing tasks to multiple shards.
ZK-rollups solution: Although ZK-rollups have significantly increased transaction processing speed and reduced costs, they are usually run independently, resulting in liquidity fragmentation and interoperability issues. ZKThreads provides a standardized development environment that supports interoperability between different shards, solving the problem of liquidity fragmentation.
Proto-Danksharding technology: This is an internal improvement plan of Ethereum that reduces the transaction cost of zk-rollups by temporarily storing data blocks. ZKThreads further improves on this basis, reducing the reliance on temporary data storage through a more efficient sharding architecture, and improving the overall efficiency and security of the system (StarkWare, 2021).
The concept of ZK Sharding
Later, in 2022, NilFoundation proposed the concept of ZK Sharding, which aims to achieve Ethereums scalability and faster transaction speed by combining zero-knowledge proof (ZKP) and sharding technology. This technology aims to divide the Ethereum network into multiple parts to process transactions in a cheaper and more efficient way. The technology includes zkSharding, which uses zero-knowledge technology to generate proofs to ensure that transactions across different shards are valid before being submitted to the main chain. This approach not only improves transaction speed, but also reduces the fragmentation of on-chain data, ensuring economic security and liquidity.
ZK State Channels
In 2021, the concept of ZK StateChannels was proposed by Virtual Labs, which combines zero-knowledge proof (ZKP) and state channel technology. It aims to achieve efficient off-chain transactions through state channels while using zero-knowledge proof to ensure the privacy and security of transactions.
ZK State Channels replace the original solution
1. Traditional State Channels:
Original solution: Traditional state channels allow two users to conduct peer-to-peer (P2P) transactions in a smart contract by locking funds. Since the funds are locked, signature exchanges between users can be carried out directly without any gas fees and delays. However, this method requires predefined addresses, and the opening and closing of channels requires on-chain operations, which limits its flexibility.
Alternative: ZK StateChannels provides support for unlimited participants, allowing dynamic entry and exit without pre-defined user addresses. In addition, through zero-knowledge proof, ZK StateChannels provides instant cross-chain access and self-verified proof, solving the flexibility and scalability problems of traditional state channels.
2. Multi-chain support:
Original solution: Traditional state channels usually only support transactions on a single chain and cannot implement cross-chain operations, limiting the users operating scope.
Alternative: ZK StateChannels uses zero-knowledge proof technology to achieve instant cross-chain transactions and asset flows without the need for intermediate bridges, greatly improving multi-chain interoperability.
3. Predefined address restrictions:
Original solution: In traditional state channels, the addresses of transaction participants must be predefined when the channel is created. If new participants join or leave, the channel must be closed and reopened, which increases operational complexity and costs.
Alternative: ZK StateChannels allows dynamic joining and exiting. New participants can join existing channels at any time without affecting the operations of current users, greatly improving the flexibility of the system and user experience.
4.ZK Omnichain InteroperabilityProtocol
In 2022, ZKOmnichain Interoperability Protocol was proposed by Way Network to achieve cross-chain asset and data interoperability based on zero-knowledge proof. The protocol achieves full-chain communication and data transmission by using zkRelayer, ZK Verifier, IPFS, Sender and Receiver.
The Omnichain project focuses on cross-chain interoperability and aims to provide a low-latency, secure network that connects different blockchains. It introduces a standardized cross-chain transaction protocol that allows assets and data to be transferred seamlessly between blockchains. This approach not only improves the efficiency of transactions, but also ensures the security of cross-chain operations.
Way Network can be seen as a specific implementation of the Omnichain concept, especially in terms of using zero-knowledge proof technology to enhance privacy and security. Way Networks technical architecture enables it to achieve seamless interoperability between chains while maintaining decentralization and efficiency.
In summary, Omnichain provides an overall framework for cross-chain interoperability, while Way Network provides stronger privacy protection and security for this framework through zero-knowledge proof technology.
This paper presents a comprehensive literature review of zero-knowledge proof (ZKP) technology and its recent developments and applications in the blockchain space. We systematically review ZKPs in the blockchain context, survey the state-of-the-art zero-knowledge proof schemes applicable to blockchain and verifiable computation, and explore their applications in anonymous and confidential transactions as well as privacy-focused smart contracts. The paper enumerates the pros and cons of these academic peer-reviewed schemes and methods, provides references for practical evaluation and comparison of these schemes, and highlights the skills and knowledge that developers need to possess when choosing a suitable scheme for a specific use case.
In addition, this paper also looks forward to the future development direction of zero-knowledge proof in hardware acceleration, blockchain scalability, interoperability and privacy protection. Through a detailed analysis of these latest technologies and development trends, this paper provides a comprehensive perspective for understanding and applying zero-knowledge proof technology, demonstrating its great potential in improving the efficiency and security of blockchain systems. At the same time, this research lays a solid foundation for subsequent research on ZK project investment.
This article is sourced from the internet: ArkStream Capital: A milestone in zero-knowledge proof technology development over the past 40 years
Related: ? How to Bind a Card to Alipay
Open your Alipay app, click on “Bank Cards” – Add Card Scan or enter your Card Number manually Get your card details on the Bee Network App, from “Profile – Overview – Card Info” and input these details into Alipay. Agree to Terms and Add. When you see this page, it means your Bee Card has been bound to Alipay successfully. All set! Now You Can Start Using Your Linked Bee Card with Alipay for any Purchases. Related: Bitcoin (BTC) Eyes Major Rally: Growing Demand to Drive Recovery In Brief Bitcoin’s price is still moving within a flag pattern, preparing for a potential breakout by securing $65,000 as support. The NUPL shows that demand has seen a considerable increase in this cycle, powered by institutional interest. This demand will likely increase going forward, given…













