My XP
0
Login
Original author: Jaehyun Ha
Compiled by: TechFlow
While zero-knowledge proofs (ZKPs) hold promise for a more private and scalable blockchain ecosystem, many aspects of zero-knowledge (ZK) are misunderstood or implemented differently than commonly believed.
There are two main aspects of ZKPs: “zero knowledge” and “succinctness.” While this statement is not wrong, most ZK rollups only utilize the succinctness property, and transaction data and account information are not completely zero-knowledge or private.
For various types of DApps, ZK rollups may not be the best choice for development stacks . For example, generating ZKPs may become a bottleneck for fast finality, thereby reducing the performance of Web3 games, while data availability guarantees based on state difference publication may harm the services of DeFi lending protocols.

Figure 1: ZK is a great buzzword
Source: imgflip
The current state of the blockchain industry can be likened to the Zero Knowledge (ZK) era. ZK stands out wherever you go, and it is becoming increasingly rare to find a next-generation blockchain project that does not incorporate ZK into its name. From a technical perspective, there is no denying that ZK is a promising technology that can contribute to a more scalable and private blockchain ecosystem. However, due to the complex technical background of ZK, many investors, both retail and institutional, often invest in ZK projects based on the “belief” that it looks cool, novel, and may solve the blockchain trilemma, without fully understanding how ZK technology can benefit each project.
In this ZK series, we’ll explore the inconvenient truths (the shortcomings and disadvantages) of ZK rollups and their beneficial applications. First, we’ll unpack the two core properties of ZK proofs (ZKPs) in blockchain: “zero knowledge” and “succinctness”. We’ll then discuss how a large number of ZK rollups currently in service don’t really take advantage of the “zero knowledge” aspect. Next, we’ll look at areas where applying ZK rollups can be more harmful than helpful, avoiding well-known issues like implementation complexity. Finally, we’ll highlight standout projects that effectively embody ZK principles and actually gain clear benefits from using ZK technology.
Rollup is a scaling solution that addresses L1 throughput limitations by executing transaction bundles off-chain and then storing summary data of the latest L2 state on L1. Among them, the outstanding feature of ZK Rollups is the ability to quickly withdraw funds by submitting proof of validity of off-chain computations on-chain. Before we delve into the problems of ZK rollups, let’s briefly review its transaction lifecycle.

Figure 2: Transaction lifecycle in ZK rollups
Source: Presto Research Center
Each L2 user generates and submits their transaction to the sequencer.
The sequencer aggregates and sorts multiple transactions, and then executes these transactions off-chain to calculate the new rollup state. The sequencer then submits this new rollup state to the on-chain state smart contract in a batch form and compresses the corresponding L2 transaction data into data blocks to ensure data availability.
This batch is sent to the prover, who creates a proof of validity (or ZKP) of the execution of the batch. This proof of validity is then sent to the validator smart contract on L1 along with additional data (i.e. the previous state root), which helps the validator identify what it is validating.
After the validator contract checks that the proof is valid, the status of the rollup is updated and the L2 transactions in the submitted batch are considered complete.
(Note that this explanation is a simplified version of the ZK Rollup process, and each implementation may vary from protocol to protocol. If we distinguish roles, there may be more entities in L2, such as aggregators, executors, and proposers. The hierarchy of data blocks may also be different, such as blocks, block groups, and batches, depending on their purpose. The above explanation assumes a situation where a centralized sequencer has strong authority to execute transactions and also generates a unified data block format as batches.)
Unlike Optimistic Rollups, thanks to ZKPs (such as ZK-SNARKs or ZK-STARKs), ZK Rollups can verify the correctness of the execution of thousands of transactions by verifying a simple proof without replaying all transactions. So, what is this ZKP and what are its characteristics?
As the name implies, a ZKP is basically a proof. A proof can be anything that can sufficiently support the providers claim. Lets say Bob (provider) wants to convince Alice (verifier) that he has authority over his laptop. The simplest way to prove this is for Bob to just tell Alice the password, and Alice enters the password on the laptop and verifies that Bob does have authority. However, this verification process is unsatisfactory for both Alice and Bob. If Bob sets a very long and complex password, it will be very challenging for Alice to enter it correctly (assuming Alice cant copy and paste). More realistically, Bob may not be willing to reveal his password to Alice to prove his authority.
What if there was a verification process where Alice could quickly verify access to the computer without Bob revealing his password? For example, Bob could unlock his laptop with fingerprint recognition in front of Alice, as shown in Figure 3 (note that this is not a perfect example of a ZKP). This is where both Alice and Bob can benefit from two key properties of ZKPs: the zero-knowledge property and the simplicity property.

Figure 3: High-level intuition of zero knowledge and simplicity
Source: imgflip
Zero Knowledge (ZK)
The zero-knowledge property refers to the fact that the proof generated by the provider does not reveal any information about the secret witness (i.e., private data) except the validity of the proof, leaving the verifier in the dark about the data. In blockchain, this property can be used to protect the privacy of individual users. If ZKPs are applied to each transaction, users can prove the legitimacy of their actions (i.e., prove that a user has enough funds to conduct a transaction) without exposing their transaction details (e.g., transfers, account balance updates, smart contract deployment and execution) to the public.
Simplicity
The succinct property refers to ZK’s ability to generate a short and fast-verifiable proof from a large-sized statement, in other words, it compresses something big into a compact form. In blockchain, this is particularly useful for rollups. Using ZKPs, a verifier in L2 can claim the correct execution of a transaction by submitting a succinct proof to a verifier in L1 (the validity of a TB-sized transaction can be represented by a 10~100 KB proof). The verifier can then easily confirm the validity of the execution in a short time (i.e., 10 milliseconds to 1 second) by verifying the succinct proof instead of replaying all the transactions.
The properties of ZKPs described above are well utilized in ZK Rollups. While validators cannot infer the original transaction data from the ZKPs received from providers, verifying succinct proofs allows them to effectively verify the providers claims (i.e., the new L2 state). That said, it is misleading to assert that current ZK Rollups fully adhere to the zero-knowledge and succinctness properties. This may be true when focusing on the interaction between providers and validators, but there are other components in ZK Rollups such as sequencers, providers, and rollup nodes. So, is the zero-knowledge principle also ensured for them?
The challenge of achieving full privacy with ZKPs in any ZK Rollups comes from the compromises that can occur if some parts are made private via ZK while others remain public. Think about the transaction lifecycle in ZK Rollups, is privacy maintained when transactions are sent from users to the sequencer? What about for providers? Or is the privacy of individual account information preserved when L2 batches are submitted to the DA layer? Currently, none of these are true.
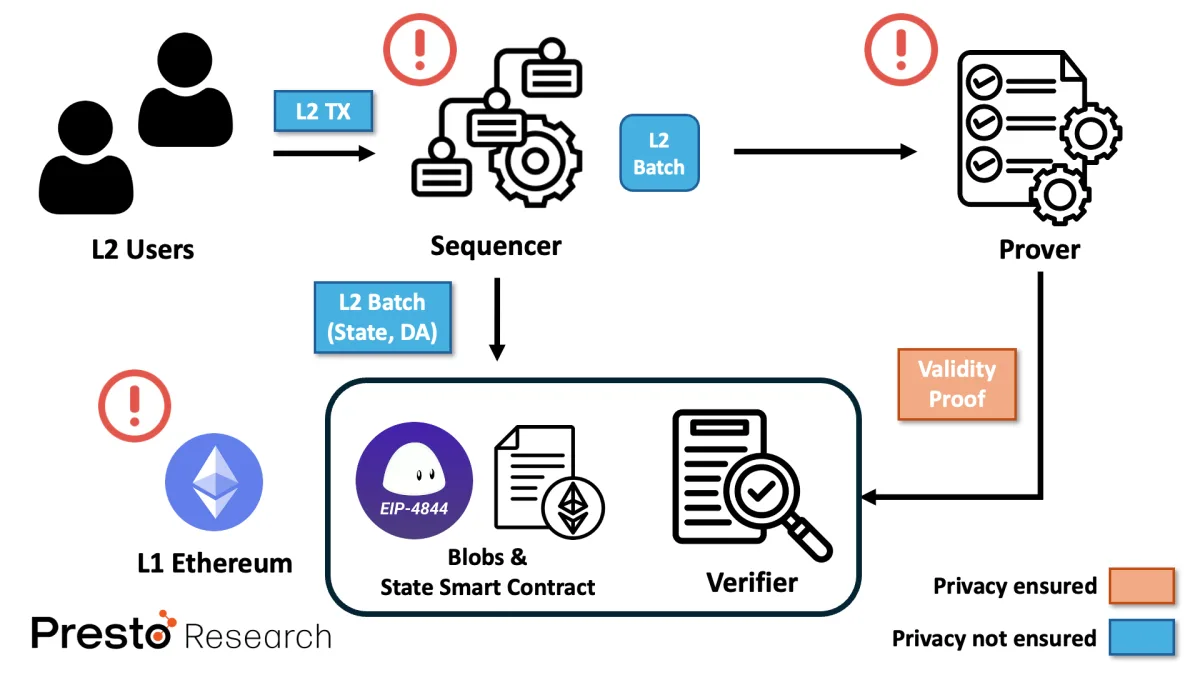
Figure 4: Privacy leakage in ZK rollups
Source: Presto Research
In most mainstream ZK Rollups, the sequencer or provider (or other centralized entity with powerful permissions) can clearly see the transaction details, including transfer amounts, account balance updates, contract deployment and execution. As a simple example, you can easily observe all the mentioned details by visiting any ZK Rollup block browser. Not only that, consider a situation where the centralized sequencer stops serving for some reason and another rollup node tries to recover the rollup state. It will extract information from the L2 data publicly released by the DA layer (in most cases, L1 Ethereum) and reconstruct the L2 state. In this process, any node that can replay the L2 transactions stored by the DA layer can recover information about the state of each users account.
Therefore, the terminology of “zero knowledge” is implemented in a fragmented form in current ZK Rollups. While this cannot be considered wrong, it is clearly different from the common perception that “ZK means zero knowledge equivalent to full privacy”. The novelty of current ZK Rollups is to exploit the “succinctness” property instead of “zero knowledge”, that is, to execute transactions off-chain and generate succinct proofs for validators so that they can quickly and scalably verify the validity of the execution without having to re-execute them.
For this reason, some ZK Rollups, like Starknet, refer to themselves as “Validity Rollups” to avoid confusion, while others that ensure true ZK privacy, like Aztec, label themselves as ZK-ZK rollups.
As mentioned earlier, most ZK Rollups do not fully implement ZK privacy. So, what is our next goal? To achieve complete transaction privacy by fully deploying ZK in every part of the Rollup? In fact, this is not a simple question. In addition to the need for significant technical progress to further mature the technology, ZK still has controversial issues in ideology (such as illegal uses of private transactions) and practicality (such as is it really useful?). Given that discussing the ethical issues of complete transaction privacy is beyond the scope of this article, we will focus on two practical issues of ZK Rollups encountered in blockchain projects.
Point 1: Generating ZKPs can be a bottleneck to fast finality
First lets discuss the practicality of ZK Rollups itself. The most compelling selling point of ZK Rollups is the reduced latency of asset withdrawals due to the fast finality of its transactions, thanks to ZKP. Increased TPS and low transaction fees are additional benefits. The field that most effectively utilizes the characteristics of ZK Rollups is the gaming industry, because the deposits and withdrawals of in-game currencies are very frequent, generating a large number of in-game transactions every second.
But can ZK Rollups really be considered the best technology stack for games? To this end, we need to think more deeply about the concept of fast finality in ZK Rollups. Imagine a user is enjoying a Web3 game running on a technology stack based on ZK Rollup. The user trades in-game items for game coins and tries to withdraw the asset from the game.
To withdraw assets, in-game transactions must be finalized. This means that the transaction must be included in a new Rollup state commitment, the corresponding ZKP should be submitted to L1, and it is necessary to wait for the finality of the proof in L1 Ethereum to ensure that the transaction is irreversible. If all of these processes can happen instantly, then we can achieve the instant transaction confirmation that ZK Rollups often tout, allowing users to withdraw assets immediately.
However, the reality is far from this. According to the finality time statistics of different ZK Rollups provided by L2beat , zkSync Era takes about 2 hours, Linea takes 3 hours, and Starknet takes about 8 hours on average. This is because it takes time to generate a ZKP, and it also takes additional time to include more transactions in a batch (i.e., a single proof) to reduce transaction fees. In other words, the speed of generating and submitting proofs is a potential bottleneck for achieving fast finality of ZK Rollups, which may reduce the user experience in Web3 games.

Figure 5: ZKP generation can be a potential bottleneck for fast finality of ZK rollups
Source: imgflip
On the other hand, gaming-optimized chains like Ronin (which powers Web3 games like Pixels and Axie Infinity) ensure ultra-fast finality, sacrificing decentralization and security. Ronin is not a ZK or Rollup-based chain: it is an EVM blockchain running under the PoA (Proof of Authority) + DPoS (Delegated Proof of Stake) consensus algorithm. It selects 22 validators based on the number of stakes delegated, and these validators then generate and validate blocks in a PoA manner (i.e., a voting process among the 22 validators alone). As a result, on Ronin, transactions are able to finalize quickly, are included in blocks with almost no delay, and have a low validation time. After the Shillin hard fork, it took an average of only 6 seconds for each transaction to finalize. Ronin achieves all of this without the need for ZKP.
Of course, Ronin also has disadvantages. Being managed by centralized validators makes it relatively more vulnerable to the threat of a 51% attack. In addition, since it does not use Ethereum as a settlement layer, it cannot inherit Ethereums security. There are also security risks in using cross-chain bridges. But from a users perspective: do they care about these? Current ZK Rollups without decentralized ordering also have single point of failure (SPOF) problems. Ethereum provides them with guarantees because it reduces the possibility of transaction rollbacks, but ZK Rollups can also freeze if the centralized sequencer or validator fails. Note again that the ZK in ZK Rollups is only used to verify the validity of the execution correctness. If there is another project that provides the same functionality but faster and cheaper, ZK Rollups may no longer be considered the preferred technology stack by Web3 game users and developers.
Point 2: Release status differences are a double-edged sword
Another point is the practicality of the ZK Rollup protocol implementation. Among them, here we focus on state difference publishing, which is one of the methods to ensure data availability in ZK rollups (see Unlocking Dencun Upgrade: Unseen Truth of Scaling DA Layers , Jaehyun Ha, 12 Apr 24).
A simple way to understand data availability in Rollups is to imagine an amateur climber proving and documenting his ascent of Mount Everest. The simplest way to do this is to record every step from base camp to the summit on video. Although the video file may be large, anyone can verify the climbers ascent and potentially replay the recording. This metaphor can be compared to the original transaction data publishing approach to ensure data availability. Optimistic Rollups follow this approach so that individual challengers can replay and verify correct execution because the sequencers state commitments cannot be trusted. In ZK Rollups, Polygon zkEVM and Scroll take this approach, storing the original L2 transaction data in a compressed form on L1 so that anyone can replay the L2 transactions to restore the state of the Rollup when needed.
Going back to the example of the amateur climber, another verification method might be for a famous climber to climb Everest with the amateur climber to prove to the world that the climb was indeed completed. Since the climb has been confirmed by a trusted individual, the climber no longer needs to record every step for record keeping. Simply taking a photo at the starting point and at the top of the mountain will allow others to believe that the climber has reached the top. This metaphor reflects the state difference approach used to ensure data availability. In ZK Rollups, zkSync Era and StarkNet adopt this approach, storing only the state difference before and after the L2 transaction is executed on L1, so that anyone can calculate the state difference from the initial state to restore the state of the Rollup if necessary.
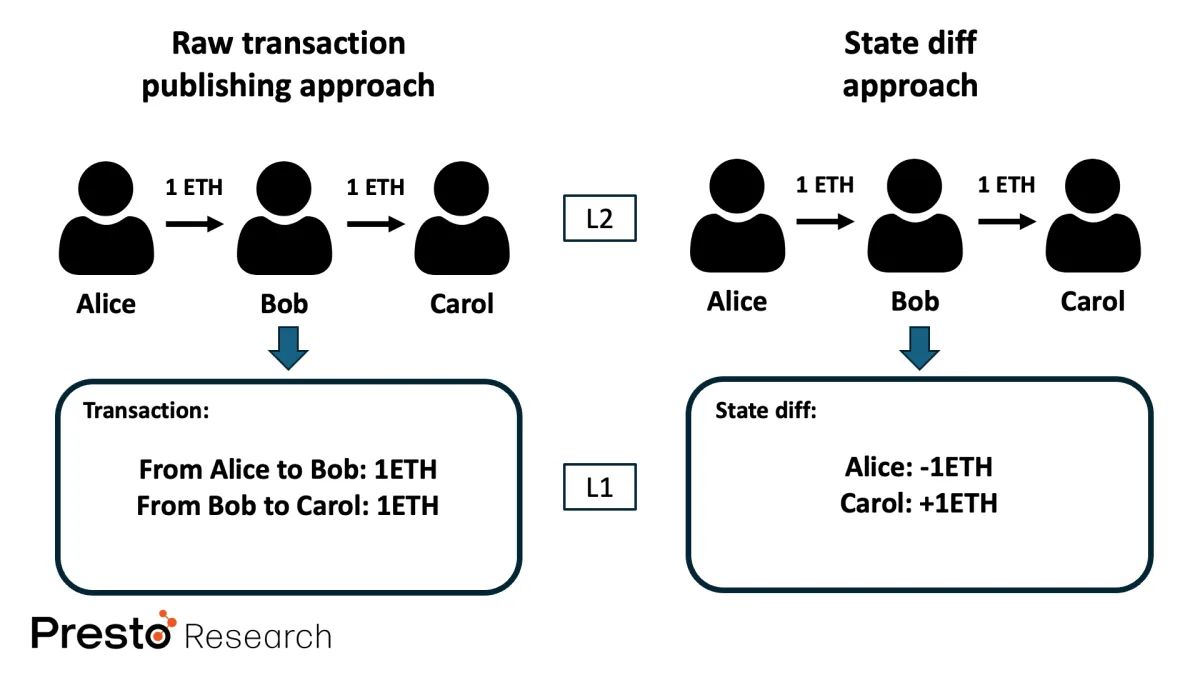
Figure 6: Original transaction release and status difference release
Source: Presto Research
This state difference method is undoubtedly cost-effective compared to the original transaction data publishing method, because it can save the step of storing intermediate transactions, thereby reducing the storage cost of L1. Although this is usually not a problem, there is a potential flaw here: this method does not allow the recovery of the complete L2 transaction history, which may be a problem for some DApps.
Take Compound, a DeFi lending protocol, for example, and assume that it is built on top of a state-differential based ZK Rollup stack. These protocols require a complete transaction history to calculate supply and lending rates every second. However, if the ZK Rollup sequencer fails, what happens when other Rollup nodes try to restore the latest state? It may restore the state, but the interest rate will be restored inaccurately because it can only track snapshots between batches instead of every intermediate transaction.
The main assertion of this article is that there is no “ZK” in most of today’s ZK Rollups, and there are many places in DApps where using ZKPs and ZK procedures may not be the best choice. ZK technology may feel innocent of being accused because there is nothing wrong with it itself, but it may bring potential performance degradation to DApps in the process of utilizing its technological advancement. However, this is not to say that ZK technology is useless to the industry. When ZKPs and ZK rollups eventually mature, they can definitely provide better solutions to the blockchain trilemma. In fact, there are already ZK-based projects that maintain ZK privacy, and there are many types of DApps that effectively take advantage of ZKPs and ZK convolutions.
This article is sourced from the internet: ZK Rollups: The Elephant in the Room
On April 24, according to official news, China Asset Management (Hong Kong) announced today that China Asset Managements Bitcoin ETF and China Asset Managements Ethereum ETF have been approved by the Securities and Futures Commission (SFC) of Hong Kong and are scheduled to be issued on April 29, 2024 and listed on the Hong Kong trading platform on April 30, 2024. This is the first time such products have been launched in the Asian market. These two types of products are designed to provide investment returns anchored to the spot prices of Bitcoin and Ethereum. This major move has once again attracted attention to the Hong Kong concept. At the beginning of this year, CFX, the leader of the Hong Kong concept, rose from US$0.19 to US$0.52 in two months.…













