原作者:jolestar(X: @jolestar )
看到好几个朋友在讨论 Based Rollup,大部分都是从安全的角度讲的,我想从 L1 与 L2 的关系,以及应用的构建的角度,谈谈我对 Based Booster Rollup 的看法。
Based Rollup 的思路其实很简单,就是用户直接将 L2 的交易提交给 L1,由 L1 进行排序和打包。但是 L1 并不验证交易的有效性,只保证交易的有序性和可用性。L2 是一个纯粹的执行者,负责执行在 L1 上打包好的 L2 交易。这个看上去是不是很眼熟?这不就是 Inscription 模式吗?没错,这里可以将 Inscription 的 Indexer 理解为 L2。我在《Inscription 是 Bug 还是 Feature》这篇文章中说过这个。
Booster Rollup 则从另一个角度入手,如何通过 L2 上的合约直接读取 L1 的状态?思路并不复杂,既然 Based Rollup 已经在 L1 上执行 L2 的交易,那为什么不把 L1 的交易也执行一遍呢?这样 L1 和 L2 的状态就在一颗大的状态树里,L2 合约就能直接读取 L1 的状态了。
所以也有将 Based Rollup 与 Booster Rollup 结合起来的项目,称为 Based Booster Rollup (BBR),例如 taiko。
BBR的背景
BBR从提出到受到市场关注,主要背景是以太坊目前主流的L2方案带来的分裂问题,L1与L2的分裂,L2与L3的分裂。目前的L2方案提供的功能,无论从开发者角度还是从用户角度,都和一个Alt-L1没太大区别,读取L1数据还是要靠Oracle,资产还是需要桥梁,钱包要切换网络。这种分裂还带来另一个问题,L1与L2之间的绑定并没有那么紧密,L2可以随时增加一套共识机制,成为Alt-L1,自成一体,让开发者和用户基本不知情。目前主要的绑定关系来自于EFs对正统性的约束:L2必须使用L1作为DA,但显然这种约束并不可靠。
那么如果我们把目前所有的 L2 方案都替换成 Based Rollup 方案,问题是不是就解决了呢?我估计 Optimism 和 Arbitrum 会跳出来表示,改用 Based Rollup 不是很容易吗?现在主流的 L2 方案都有 Force Inclusion 机制,L2 直接把 Sequencer 去掉,让用户通过 Force Inclusion 把交易发送到 L1,Based Rollup 不就实现了吗?
但这能解决碎片化问题吗?不能。虽然 Arb 和 Op 都实时向 L1 提交交易,L1 也对其进行了打包和排序,但由于各自只承认自己的交易,因此依然存在碎片化问题。说到这里,大家应该明白了,对于 Based Rollup 来说,解决碎片化问题的关键是要有可以在 L2 之间共享的交易或数据,而这种数据格式需要:
-
它必须是一种格式 定义L1 上的账本是独立于平台和实现的,不同的 L2 账户和虚拟机是不同的,其交易不能直接共享。
-
它需要 L2 之间的共识以及多个 L2 的支持。
所以一定是协议优先,先设计一个公共的协议和数据格式,链上只存储协议需要的数据,链下执行和验证,实现对不同L2的支持方案。但要做到这两点其实还是挺难的。首先以太坊生态里的开发者一般都是通过智能合约来设计协议的,并没有直接根据数据格式来设计协议的习惯。这个方向的主要尝试就是上次铭文火爆时的Ethscriptions。第二点就更难了,需要实践和时间来验证。
从 BBR 到 BBSR,可堆叠 L2
说完了数据共享的问题,再来说说用户体验。显然,如果所有的交易都是用户直接发送到 L1,无论是 Gas 还是确认时间,体验都和使用 L1 差不多。所以有人开始为 Based Rollup 设计预确认协议,但如果预确认协议真的能起作用,所有的交易都需要先经过预确认协议,那不就成了 Sequencer 吗?说这个是不是太浪费时间了?
这种矛盾的出现是因为人们混淆了几种类型的交易:
-
用户直接向 L1 提交,并由 L1 执行和验证的交易即为 L1 交易。
-
用户直接向L1提交,但L1并不直接验证和执行,L2之间共享协议的数据交易可以称为L1.5交易。
-
用户直接向L2 Sequencer提交交易,由Sequencer进行预先确认并执行,这是某个L2的专用交易。
Based Rollup 只和 1 和 2 相关,3 是 Sequencer Rollup 目前的工作方式,两者可以结合起来。
假设有这样的一个Rollup解决方案:
-
Sequencer 自动同步所有 L1(包括 L1.5)交易,并按照 L1 给出的顺序执行它们。
-
Sequencer 同时接收 L2 交易,并将其与 L1 交易一起排序并执行。
通过1实现了Based和Booster,通过2实现了在不牺牲用户体验的情况下快速确认L2交易。按照之前的命名方案,这个应该叫BBSR(Based Booster Sequencer Rollup),但是有点长,不好理解,所以我叫它Stackable L2。顾名思义,L2是堆叠在L1上的,L2包含了L1所有的交易和状态。这是 解决方案 @RoochNetwork .
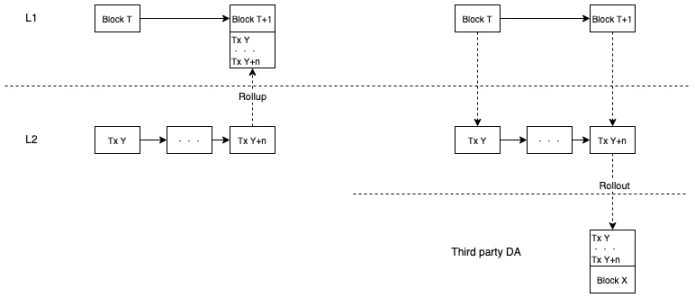
如何保证 L2 交易的 DA?Rollup 还是 Rollout?
如果采用上述方案,L2 再打包自己的交易重新提交给 L1 就有些奇怪了,因为 L2 会读取打包自己交易的 L1 交易重新执行,有点像自己的输出也变成了自己的输入。所以 Rooch 的解决方案是 Rollout,而不是 Rollup。因为从长远来看,L1 的区块空间非常宝贵,多个 L2 交易占用 L1 的空间是一种滚动模式。L1 的空间应该留给 L1 和 L1.5 交易,L2 应用层交易应该通过 Rollout 来寻求更便宜的区块空间并拓展新的区块空间,这也有利于整个行业生态的发展。
比特币生态系统中的 BBSR/Stackable L2 实践
前面的描述都是从以太坊的角度来讲的,由于Rooch是比特币第一个BBSR或者Stackable L2的实践,所以我们来聊一聊比特币生态中的不同点。
比特币 L2 上没有图灵完备的智能合约,这在 Based Rollup 模式中成为了优势。因为 Based Rollup 不需要 L1 来执行和验证交易,只需要保证 Permission Less 和 DA 即可。这也迫使比特币生态中的项目从很早以前就开始基于数据结构来设计协议。无论是 coloured coins,还是后来的 RGB、Taproot Assets、Ordinals Inscription、Atomicals、Runs 等,都是这一类的尝试,都可以纳入 CSV(Client-side Validation)协议这个广义的概念中。它们的交易都是典型的 L1.5 交易。如果以太坊生态中的项目想要实践 Based L2,设计一个多个 L2 之间共享的协议,那就和上面的协议大致相同了。
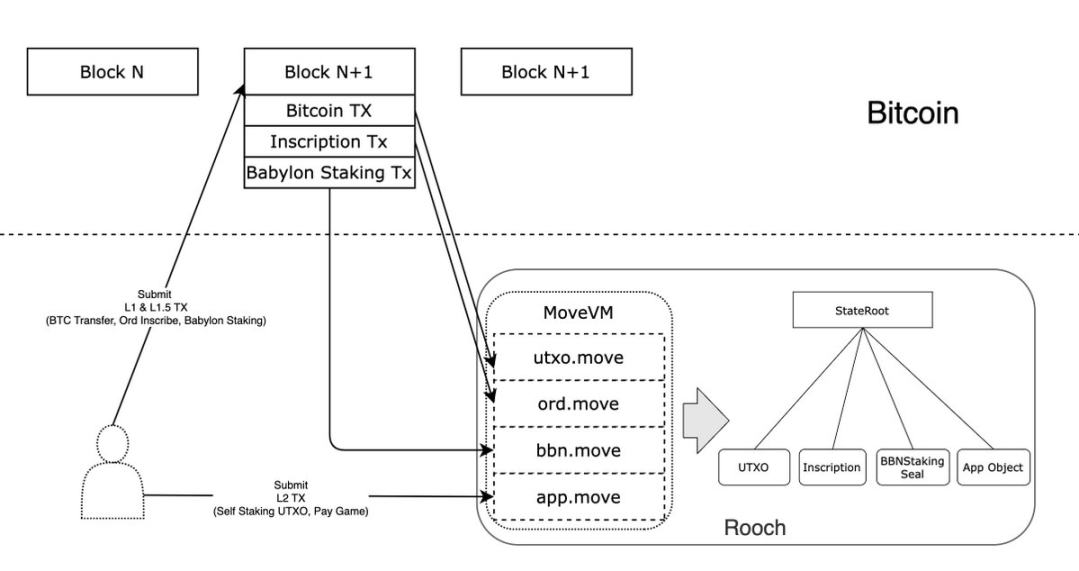
我们以Rooch为例,讲解一下比特币上BBSR的工作模式:
-
用户将直接向比特币提交 L1 和 L1.5 交易。由于协议是公开的,因此入口点可以是任何应用程序。
-
Rooch 会同步所有的 L1 交易,处理其中的 UTXO,并查找是否有额外的协议信息,然后使用相应的 Move 模块进行处理。例如,标识为 Inscription 的交易将由 ord 模块处理,而 Babylon Staking 交易将由 bbn 模块处理。
-
用户直接将L2交易提交给Roochs Sequencer节点进行处理,以上三笔交易的执行结果将生成完整的状态树,应用合约可以充分利用L1和L1.5交易生成的状态。
该模式下的应用可以设计两种类型的交易,一种是公共协议交易(Based部分,在L1上),一种是应用交易(通过Sequencer进行排序),两者可以通过Booster模式相互配合,保证Permission Less的同时也能保证用户体验。
如前所述,公共协议的设计需要时间和实践来验证并达成共识,而Rooch可以提供这样便捷的实验环境:如果你想在比特币上设计一个新的应用程序或资产协议,你只需要定义协议格式,然后部署一个相应的Move合约模块来处理它,然后就可以通过构造应用场景进行实验。
当然,比特币生态系统在这条道路上也面临一些挑战:
-
比特币在最初设计时,并没有为这种 DA 场景留下足够的扩展空间。因此,如何将数据写入比特币是各个协议尝试探索的方向之一,比如在 OP_RETURN 中嵌入数据,通过 Witness,甚至通过签名写入数据等。目前还缺乏标准化的解决方案。
-
比特币生态系统尚未就链上嵌入数据的价值达成广泛共识。这是我从上一次铭文热潮以来一直在呼吁的。比特币生态系统应该重视比特币作为全球公共数据总线的价值。
L1 作为全局公共数据总线的价值
自 DeFi 之夏以来,整个 Crypto 领域都在探索 DeFi 之外的新应用。无论是比特币的铭文热潮,还是最近的 Based Rollup 热议,都可以理解为对 L1 作为数据总线价值的重新发现。从分布式系统的角度看,通过数据总线可以实现系统间的解耦,而系统间的解耦是实现无权限化的关键前提之一。例如 Crypto 生态中的去中心化交易所就充分利用了区块链作为数据总线实现了去中心化的对接,而这在传统金融体系中很难直接实现。如果想要支持更复杂的应用,只需要将简单的转账交易升级为应用协议交易即可实现应用级的无权限化,而且这种方式对现有应用的侵入性最小。
本文主要从生态和应用的角度来探讨一下BBR,BBR模式的安全性以及BBR模式下L1、L1.5、L2状态的互操作性问题将在后续文章中详细讨论。最后附上一些相关链接,包括我的历史文章和推特小伙伴们对Based Rollup从不同角度的讲解。
相关链接:
1. Stackable L2 — 区块链新扩容方案 https://rooch.network/zh-CN/blog/stackable-l2
2.比特币Layer2该怎么做? https://x.com/jolestar/status/1717358817992995120 我根据L2如何使用比特币L1上的状态和数据设计了最初的方案,有朋友在评论中提到了Booster方案,最终在实践中采用了Booster方案。
3. 铭文是 Bug 还是功能? https://x.com/jolestar/status/1732711942563959185 本文从L2的构造方式角度解释铭文的价值,包括L1和L2之间的激励相容问题。
4. 从减法理论角度探讨Based Rollup@kerne l1 983 https://web3caff.com/zh/archives/108241
5. @jason_chen 998 的关于 Based Rollup 的文章 https://x.com/jason_chen998/status/1799692331635048697
6. 基于 Rollup Track 的研究报告 https://research.web3caff.com/zh/archives/22719
本文来源于网络:深入解析Based Booster Rollup:背景、实践与展望
本文哈希(SHA 1):8656ff83d95af1de9dab2b925597cf72c6f63c66 编号:连源安全知识第032期 随着区块链技术的不断发展,金融行业正在经历一场前所未有的变革。在此背景下,一个新兴概念逐渐兴起:PayFi(支付金融)。该术语最早由 Solana 基金会主席 Lily Liu 在 2024 年 EthCC 会议上提出,旨在探索一种创新的支付金融模式。PayFi 的愿景不仅仅是基于区块链的支付系统 加密货币PayFi 不仅仅是一个支付工具,更希望通过去中心化技术结合货币的时间价值,为用户提供更安全、更快捷、更低成本的金融服务。 1、PayFi 的核心理念:货币的时间价值与去中心化金融 什么是 PayFi Lily Liu 提到,PayFi 的核心动机,是实现比特币最初的愿景……







