Task
Ranking
已登录
Bee登录
Twitter 授权
TG 授权
Discord 授权
去签到
下一页
关闭
获取登录状态
My XP
0
登入
Recently, a face NFT minting project initiated by 普里瓦西 has become extremely popular!
At first glance, it seems simple. In the project, users can enter their own faces on the IMHUMAN (I am human) mobile app and mint their facial data into an NFT. Just the combination of facial data on-chain + NFT has enabled the project to mint more than 200,000+ NFTs since it went online at the end of April, which shows how popular it is.
I am also confused. Why? Can facial data be uploaded to the blockchain no matter how big it is? Will my facial information be stolen? What does Privasea do?
Wait, let us continue to study the project itself and the project owner Privasea to find out more.
Keywords: NFT, AI, FHE (Fully Homomorphic Encryption), DePIN
First of all, let us interpret the purpose of the face NFT minting project itself. If you think that this project is simply to mint facial data into NFT, you are wrong .
The App name of the project we mentioned above, IMHUMAN (I am human), has already explained this problem well: in fact, the project aims to determine whether you are a real person in front of the screen through facial recognition .
First of all, why do we need human-machine recognition?
According to the 2024 Q1 report provided by Akamai (see appendix), Bots (an automated program that can simulate human operations such as sending HTTP requests) account for an astonishing 42.1% of Internet traffic, of which malicious traffic accounts for 27.5% of the entire Internet traffic.
Malicious bots may cause catastrophic consequences such as delayed response or even downtime to centralized service providers, affecting the user experience of real users.
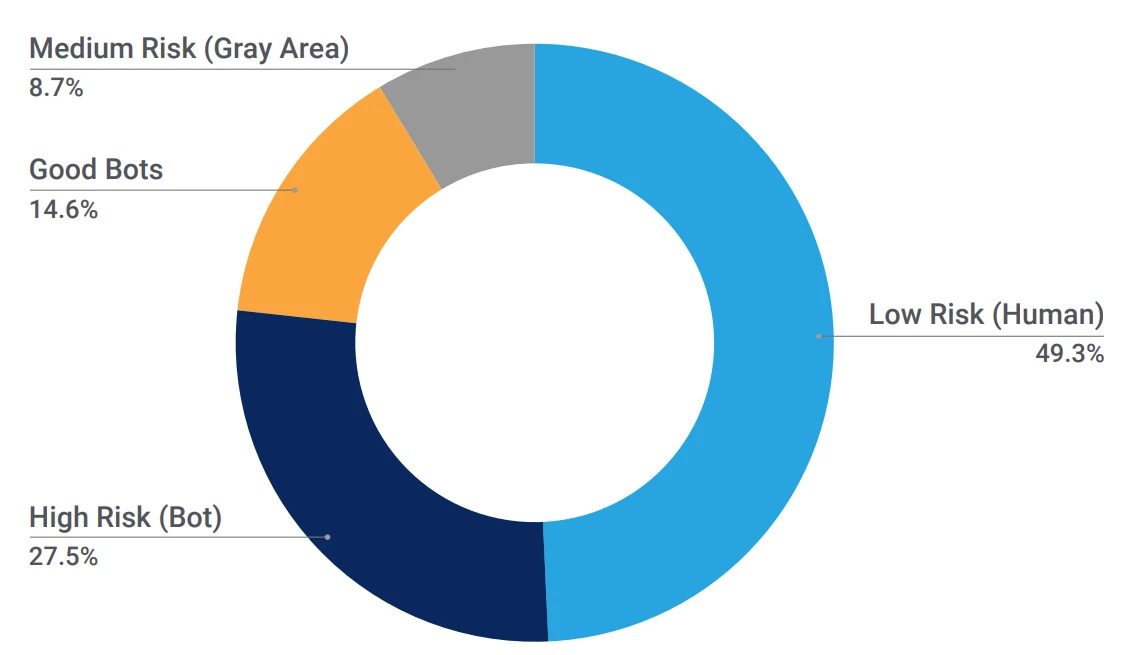
Let鈥檚 take the ticket grabbing scenario as an example. Cheaters can greatly increase the probability of successful ticket grabbing by creating multiple virtual accounts. What鈥檚 more, some even directly deploy automated programs next to the service provider鈥檚 computer room to achieve almost zero delay in ticket purchase.
Ordinary users have almost no chance of winning against these high-tech users.
Service providers have also made some efforts in this regard. For clients, in Web2 scenarios, they have introduced real-name authentication, behavior verification codes and other methods to distinguish between humans and machines. On the server side, they use WAF strategies and other means to perform feature filtering and interception.
So can this solve the problem?
Obviously not, because the rewards of cheating are huge.
At the same time, the confrontation between man and machine is continuous, and both cheaters and testers are constantly upgrading their arsenals.
Take cheaters as an example. Taking advantage of the rapid development of AI in recent years, the behavioral verification codes of clients have been almost dimensionalized by various visual models, and even AI has faster and more accurate recognition capabilities than humans. This has forced verifiers to passively upgrade from early user behavioral feature detection (image verification code) to simulated biological feature detection (perceptual verification: such as client environment monitoring, device fingerprints, etc.). Some high-risk operations may need to be upgraded to biological feature detection (fingerprint, face recognition).
For Web3, human-machine detection is also a strong demand.
For some project airdrops, cheaters can create multiple fake accounts to launch a Sybil attack. At this time, we need to identify the real person.
Due to the financial attributes of Web3, for some high-risk operations, such as account login, currency withdrawal, transaction, transfer, etc., it is necessary to verify that the user is not only a real person, but also the account owner, so facial recognition becomes the only choice.
The demand is certain, the question is how to achieve it?
As we all know, decentralization is the original intention of Web3. When we discuss how to implement face recognition on Web3, the deeper question is how Web3 should adapt to AI scenarios :
How should we build a decentralized machine learning computing network?
How to ensure the privacy of user data is not leaked?
How to maintain the operation of the network, etc.?
Privasea has provided a groundbreaking solution to the problem mentioned at the end of the previous chapter: Privasea built Privasea AI NetWork based on FHE (fully homomorphic encryption) to solve the privacy computing problem of AI scenarios on Web3.
In laymans terms, FHE is an encryption technology that ensures that the results of the same operation on plaintext and ciphertext are consistent .
Privasea optimizes and encapsulates the traditional THE, dividing it into application layer, optimization layer, arithmetic layer and original layer, forming the HESea library to adapt it to machine learning scenarios. The following are the specific functions of each layer:

Through a tiered structure, Privasea provides more specific and tailored solutions to meet the unique needs of each user.
Privaseas optimization encapsulation focuses on the application layer and optimization layer, and these customized calculations can provide more than a thousand times speedup compared to basic solutions in other homomorphic libraries.
From the architecture of Privasea AI NetWork:
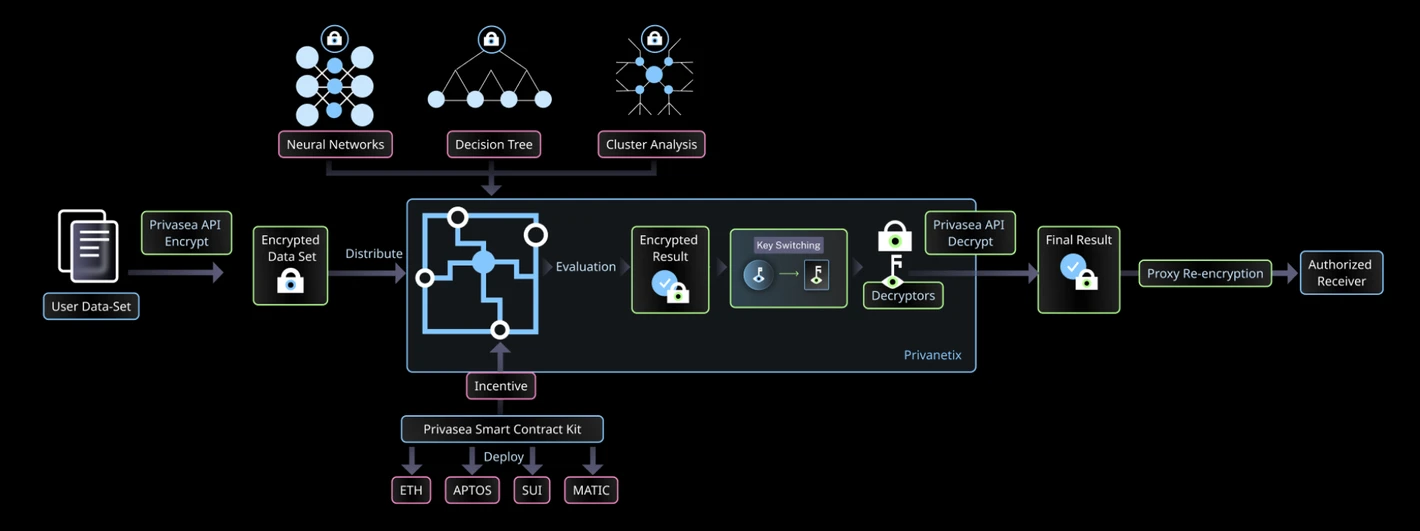
There are a total of 4 roles on its network: data owner, Privanetix node, decryptor, and result receiver.
Data owner: Through the Privasea API, used to securely submit tasks and data.
Privanetix Node: It is the core of the entire network, equipped with the advanced HESea library and integrated with blockchain-based incentive mechanisms, which can perform secure and efficient calculations while protecting the privacy of the underlying data and ensuring the integrity and confidentiality of the calculations.
Decryptor: Get the decrypted result through Privasea API and verify the result.
Result recipient: The task result will be returned to the data owner and the person designated by the task issuer.
The following is a general workflow diagram of Privasea AI NetWork:

STEP 1: User Registration: The data owner initiates the registration process on the Privacy AI Network by providing the necessary authentication and authorization credentials. This step ensures that only authorized users can access the system and participate in network activities.
STEP 2: Task submission : Submit the computing task and input data. The data is encrypted by the HEsea library. The data owner also specifies the authorized decryptor and result recipient who can access the final result.
STEP 3: Task Allocation : The blockchain-based smart contract deployed on the network allocates computing tasks to suitable Privanetix nodes based on availability and capabilities. This dynamic allocation process ensures efficient resource allocation and distribution of computing tasks.
STEP 4: Encrypted Calculations : The designated Privanetix node receives the encrypted data and performs calculations using the HESea library. These calculations are performed without decrypting the sensitive data, thus maintaining its confidentiality. To further verify the integrity of the calculations, the Privanetix node generates zero-knowledge proofs for these steps.
STEP 5: Key Switching : After the computation is completed, the designated Privanetix node uses key switching technology to ensure that the final result is authorized and can only be accessed by the designated decryptor.
STEP 6: Result Verification : After completing the calculation, the Privanetix node transmits the encrypted result and the corresponding zero-knowledge proof back to the blockchain-based smart contract for future verification.
STEP 7: Incentive Mechanism : Track the contribution of Privanetix nodes and distribute rewards
STEP 8: Result Retrieval : Decryptors use the Privasea API to access the encrypted results. Their first task is to verify the integrity of the calculation, ensuring that the Privanetix node performed the calculation as intended by the data owner.
STEP 9: Result delivery : Share the decryption result with the designated result recipients pre-determined by the data owner.
In the core workflow of Privasea AI NetWork, open APIs are exposed to users, which allows users to focus on the input parameters and the corresponding results without having to understand the complex operations within the network, which does not put too much mental burden. At the same time, end-to-end encryption prevents data from being leaked without affecting data processing.
PoW PoS dual mechanism superposition
Privaseas recently launched WorkHeart NFT and StarFuel NFT use the dual mechanisms of PoW and PoS to manage network nodes and distribute rewards. Purchasing WorkHeart NFT will qualify you to become a Privanetix node to participate in network calculations and obtain token revenue based on the PoW mechanism. StarFuel NFT is a node enhancer (limited to 5,000) that can be combined with WorkHeart. Similar to PoS, the more tokens staked to it, the greater the revenue multiplier of the WorkHeart node.
So, why PoW and PoS?
In fact, this question is easier to answer.
The essence of PoW is to reduce the nodes malicious behavior rate and maintain the stability of the network through the time cost of calculation. Unlike the large amount of invalid calculations of BTCs random number verification, the actual work output (calculations) of the privacy computing network nodes can be directly linked to the workload mechanism, which is naturally suitable for PoW.
PoS makes it easier to balance economic resources.
In this way, WorkHeart NFT obtains income through the PoW mechanism, while StarFuel NFT increases the income ratio through the PoS mechanism, forming a multi-level and diversified incentive mechanism, allowing users to choose the appropriate participation method according to their own resources and strategies. The combination of the two mechanisms can optimize the income distribution structure and balance the importance of computing resources and economic resources in the network.
It can be seen that Privatosea AI NetWork has built an encrypted version of the machine learning system based on FHE. Thanks to the characteristics of FHE privacy computing, the computing tasks are subcontracted to various computing nodes (Privanetix) in a distributed environment, the results are verified through ZKP, and the nodes that provide computing results are rewarded or punished with the help of the dual mechanisms of PoW and PoS to maintain the operation of the network. It can be said that the design of Privasea AI NetWork is paving the way for privacy-preserving AI applications in various fields.
In the previous section, we can see that the security of Privatosea AI NetWork relies on its underlying FHE. With the continuous technological breakthroughs of ZAMA, the leader in the FHE field, FHE has even been dubbed the new holy grail of cryptography by investors. Let us compare it with ZKP and related solutions.
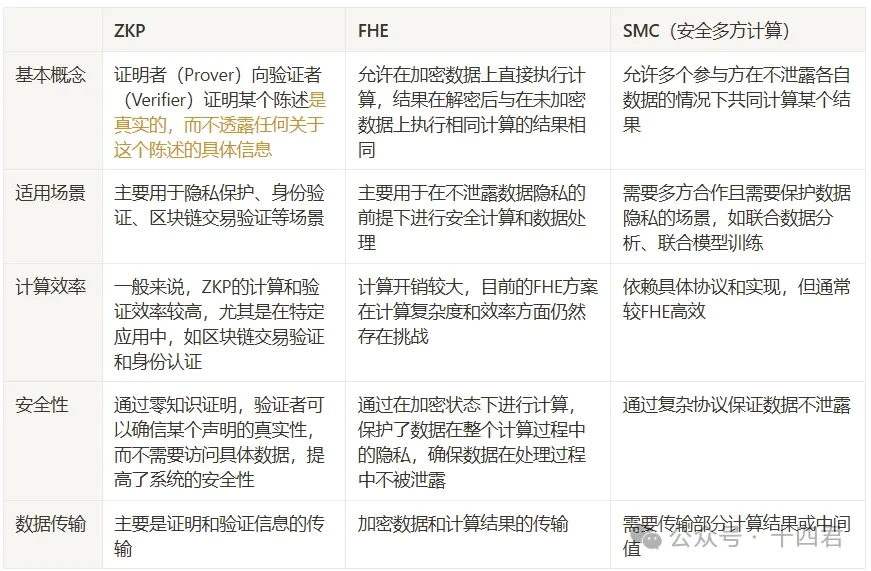
By comparison, we can see that the applicable scenarios of ZKP and FHE are quite different. FHE focuses on privacy computing, while ZKP focuses on privacy verification.
SMC seems to have a greater overlap with FHE. The concept of SMC is secure joint computing, which solves the data privacy problem of individual computers that perform joint computing.
FHE achieves the separation of data processing rights and data ownership , thereby preventing data leakage without affecting computing. But at the same time, it sacrifices computing speed.
Encryption is like a double-edged sword. While it improves security, it also significantly reduces computing speed.
In recent years, various types of FHE performance improvement solutions have been proposed, some based on algorithm optimization and some relying on hardware acceleration.
In terms of algorithm optimization, new FHE schemes such as CKKS and optimized bootstrap methods significantly reduce noise growth and computational overhead;
In terms of hardware acceleration, customized GPU, FPGA and other hardware have significantly improved the performance of polynomial operations.
In addition, the application of hybrid encryption schemes is also being explored. By combining partial homomorphic encryption (PHE) and search encryption (SE), efficiency can be improved in specific scenarios.
Despite this, FHE still has a large performance gap compared to plaintext computing.
Through its unique architecture and relatively efficient privacy computing technology, Privasea not only provides users with a highly secure data processing environment, but also opens a new chapter in the deep integration of Web3 and AI. Although the FHE underlying reliance has a natural computing speed disadvantage, Privasea has recently reached a cooperation with ZAMA to jointly tackle the problem of privacy computing. In the future, with continuous technological breakthroughs, Privasea is expected to realize its potential in more fields and become an explorer of privacy computing and AI applications.
This article is sourced from the internet: In-depth analysis of Privasea: Can facial data be used to create NFTs?
Headlines Blast announces the points distribution details for the second phase of airdrops, and will distribute 10 billion BLAST Blast published a post announcing the points distribution details for the second phase of the airdrop. In the second phase, Blast will distribute 10 billion BLAST airdrops, of which 50% will be allocated to ordinary points (Points). Users can earn Points by holding ETH, WETH, USDB and BLAST, and the Point accumulation rate of each asset is the same; 50% will be allocated to gold points (Gold). Dapps can earn Gold (and then distribute it to users) based on their comprehensive appeal on the Blast mainnet and in future Big Bang competitions. Gold will be distributed in the first week of each month, and the first phase will be announced on…













