My XP
0
Login
اصل عنوان: ایتھریم پروٹوکول کے ممکنہ مستقبل، حصہ 5: دی پرج
Vitalik Buterin کا اصل مضمون
اصل ترجمہ: Odaily Planet Daily Husband How

اکتوبر 14 کے بعد سے، Ethereum کے بانی Vitalik Buterin نے یکے بعد دیگرے Ethereum کے ممکنہ مستقبل پر مباحث شائع کیے ہیں۔ سے انضمام , دی سرج , لعنت , کنارہ تازہ ترین ریلیز تک دی پرج ، وہ سب Ethereum مینیٹ کی مستقبل کی ترقی اور موجودہ مسائل کو حل کرنے کے طریقہ کار کے لئے Vitaliks کے وژن پر روشنی ڈالتے ہیں۔ حل۔
دی مرج: شرکت کو بڑھانے اور لین دین کی تصدیق کو تیز کرنے کے لیے PoS پر جانے کے بعد سنگل سلاٹ فائنل اور کم اسٹیکنگ تھریشولڈز کو بہتر بنانے کے لیے Ethereum کی ضرورت پر تبادلہ خیال کرتا ہے۔
The Surge: Ethereum کو اسکیل کرنے کے لیے مختلف حکمت عملیوں کی کھوج کرتا ہے، خاص طور پر Rollup-centric roadmap، اور اسکیل ایبلٹی، وکندریقرت، اور سیکورٹی کے لحاظ سے اس کے چیلنجز اور حل۔
لعنت: PoS میں منتقلی کے دوران Ethereum کو درپیش مرکزیت اور قدر کے اخراج کے خطرات کا پتہ لگاتا ہے، وکندریقرت اور انصاف پسندی کو بڑھانے کے لیے متعدد میکانزم تیار کرتا ہے، اور صارف کے مفادات کے تحفظ کے لیے داؤ پر لگی معیشت میں اصلاحات کرتا ہے۔
The Verge: Ethereum کی بے ریاست تصدیق کے چیلنجز اور حل تلاش کرتا ہے، اس بات پر توجہ مرکوز کرتا ہے کہ کس طرح Verkle Trees اور STARKs جیسی ٹیکنالوجیز بلاکچین کی وکندریقرت اور کارکردگی کو بڑھا سکتی ہیں۔
26 اکتوبر کو، Vitalik Buterin نے The Purge کے بارے میں ایک مضمون شائع کیا، جس میں Ethereum کو درپیش چیلنج پر بحث کی گئی تھی کہ سلسلہ کی پائیداری اور وکندریقرت کو برقرار رکھتے ہوئے طویل مدتی میں پیچیدگی اور اسٹوریج کی ضروریات کو کیسے کم کیا جائے۔ کلیدی اقدامات میں تاریخ کی میعاد ختم ہونے اور ریاست کی میعاد ختم ہونے کے ذریعے کلائنٹ کے ذخیرہ کرنے کے بوجھ کو کم کرنا، اور نیٹ ورک کی پائیداری اور توسیع پذیری کو یقینی بنانے کے لیے خصوصیت کی صفائی کے ذریعے پروٹوکول کو آسان بنانا شامل ہے۔
مندرجہ ذیل اصل مواد ہے جس کا ترجمہ Odaily Planet Daily نے کیا ہے۔
جسٹن ڈریک، ٹم بیکو، میٹ گارنیٹ، پائپر میریم، ماریئس وین ڈیر وجڈن، اور ٹوماس اسٹانزاک کا ان کے تاثرات اور جائزوں کے لیے خصوصی شکریہ۔
Ethereum کے ساتھ چیلنجوں میں سے ایک یہ ہے کہ، بطور ڈیفالٹ، کوئی بھی بلاکچین پروٹوکول وقت کے ساتھ ساتھ بلوٹ اور پیچیدگی میں بڑھے گا۔ یہ دو جگہوں پر ہوتا ہے:
تاریخی ڈیٹا: تاریخ کے کسی بھی موڑ پر کی گئی کوئی بھی ٹرانزیکشن اور کسی بھی اکاؤنٹ کو تمام کلائنٹس کے ذریعہ مستقل طور پر ذخیرہ کرنے اور کسی بھی نئے کلائنٹ کے ذریعہ ڈاؤن لوڈ کرنے کی ضرورت ہے تاکہ نیٹ ورک کے ساتھ مکمل طور پر مطابقت پذیر ہو۔ اس کی وجہ سے کلائنٹ کا بوجھ اور مطابقت پذیری کا وقت وقت کے ساتھ بڑھتا ہے، یہاں تک کہ اگر سلسلہ کی صلاحیت مستقل رہتی ہے۔
پروٹوکول کی خصوصیات: پرانی خصوصیات کو ہٹانے کے مقابلے میں نئی خصوصیات شامل کرنا بہت آسان ہے، جس کی وجہ سے وقت کے ساتھ ساتھ کوڈ کی پیچیدگی بڑھتی جاتی ہے۔
Ethereum کے طویل مدتی میں پائیدار ہونے کے لیے، ہمیں ان دونوں رجحانات کے لیے مضبوط انسداد دباؤ ڈالنے کی ضرورت ہے، جس سے وقت کے ساتھ پیچیدگی اور پھولنے میں کمی آتی ہے۔ لیکن ایک ہی وقت میں، ہمیں بلاکچینز کو زبردست بنانے والی کلیدی خصوصیات میں سے ایک کو محفوظ رکھنے کی ضرورت ہے: پائیداری۔ آپ لین دین کے کال ڈیٹا میں ایک NFT، محبت کا خط، یا $1 ملین کا سمارٹ کنٹریکٹ چین پر رکھ سکتے ہیں، دس سال کے لیے غار میں جا سکتے ہیں، اور باہر آ کر تلاش کر سکتے ہیں کہ یہ ابھی بھی آپ کے پڑھنے اور بات چیت کرنے کا انتظار کر رہا ہے۔ اس کے ساتھ DApps کو مکمل طور پر ڈی سینٹرلائز کرنے اور اپ گریڈ کیز کو ہٹانے میں آسانی محسوس کرنے کے لیے، انہیں یقین رکھنے کی ضرورت ہے کہ ان کے انحصار کو اس طرح اپ گریڈ نہیں کیا جائے گا جس سے وہ ٹوٹ جائیں – خاص طور پر خود L1۔
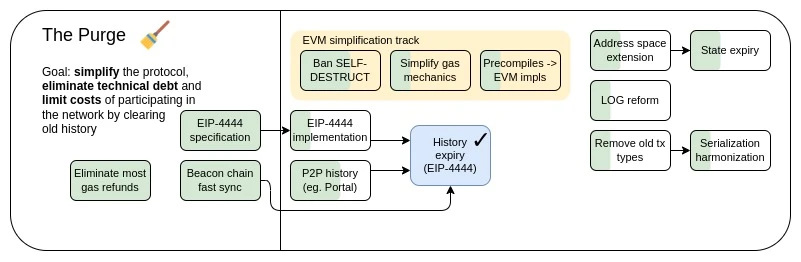
اگر ہم ایسا کرنے کا عزم رکھتے ہیں تو تسلسل کو برقرار رکھتے ہوئے ان دو ضروریات کے درمیان توازن قائم کرنا اور بلوٹ، پیچیدگی اور زوال کو کم کرنا یا ریورس کرنا بالکل ممکن ہے۔ حیاتیات یہ کر سکتے ہیں: جب کہ زیادہ تر حیاتیات وقت کے ساتھ ساتھ بوڑھے ہوتے ہیں، خوش قسمت چند ایسا نہیں کرتے . یہاں تک کہ سماجی نظام بھی کر سکتے ہیں۔ بہت طویل عمر ہے . Ethereum کچھ معاملات میں کامیاب ہوا ہے: کام کا ثبوت ختم ہو گیا ہے، SELFDESTRUCT opcode زیادہ تر ختم ہو چکا ہے، اور بیکن چین نوڈس چھ ماہ پرانے ڈیٹا کو محفوظ کر رہے ہیں۔ Ethereum کے لیے اس راستے کو زیادہ عمومی انداز میں تلاش کرنا، اور ایک طویل مدتی مستحکم حتمی نتیجہ کی طرف، Ethereums کی طویل مدتی اسکیل ایبلٹی، تکنیکی پائیداری، اور یہاں تک کہ سیکورٹی کے لیے حتمی چیلنج ہے۔
صاف کریں: بنیادی مقصد۔
کلائنٹ کی کم اسٹوریج کی ضروریات ہر نوڈ کی تمام تاریخ یا حتیٰ کہ حتمی حالت کو مستقل طور پر ذخیرہ کرنے کی ضرورت کو کم یا ختم کرکے۔
غیر ضروری فعالیت کو ختم کرکے پروٹوکول کی پیچیدگی کو کم کریں۔
آرٹیکل ڈائرکٹری:
اس تحریر کے مطابق، ایک مکمل مطابقت پذیر ایتھریم نوڈ کی ضرورت ہے۔ تقریباً 1.1 ٹی بی کے لیے ڈسک کی جگہ عملدرآمد کلائنٹ ، اور متفقہ کلائنٹ کے لیے سینکڑوں جی بی مزید۔ اس کی اکثریت تاریخ کی ہے: تاریخی بلاکس، لین دین، اور رسیدوں کے بارے میں ڈیٹا، جن میں سے زیادہ تر کئی سال پرانا ہے۔ اس کا مطلب یہ ہے کہ اگر گیس کی حد میں بالکل بھی اضافہ نہ ہوا تو بھی نوڈ کے سائز میں سالانہ سینکڑوں جی بی کا اضافہ ہوتا رہے گا۔
ہسٹری سٹوریج کے مسئلے کی ایک کلیدی آسان بنانے والی خصوصیت یہ ہے کہ کیونکہ ہر بلاک ہیش لنکس کے ذریعے پچھلے بلاک کی طرف اشارہ کرتا ہے (اور دوسرے ڈھانچے تاریخ پر اتفاق رائے تک پہنچنے کے لیے حال پر اتفاق ہی کافی ہے۔ جب تک نیٹ ورک تازہ ترین بلاک پر متفق ہے، کوئی بھی تاریخی بلاک یا ٹرانزیکشن یا اسٹیٹ (اکاؤنٹ بیلنس، بے ترتیب نمبر، کوڈ، اسٹوریج) مرکل ثبوت کے ساتھ کسی ایک شریک کے ذریعے فراہم کیا جا سکتا ہے، اور یہ ثبوت کسی اور کو بھی تصدیق کرنے کی اجازت دیتا ہے۔ اس کی درستگی. اتفاق رائے N/2-of-N ٹرسٹ ماڈل ہے، جبکہ تاریخ ہے۔ ایک N-of-N ٹرسٹ ماڈل .
اس سے ہمارے پاس بہت سارے اختیارات ہیں کہ ہم تاریخ کو کیسے ذخیرہ کرتے ہیں۔ ایک قدرتی انتخاب ایک نیٹ ورک ہے جہاں ہر نوڈ ڈیٹا کا صرف ایک چھوٹا سا حصہ ذخیرہ کرتا ہے۔ سیڈ نیٹ ورک نے کئی دہائیوں سے اس طرح کام کیا ہے: جب کہ نیٹ ورک مجموعی طور پر لاکھوں فائلوں کو اسٹور اور تقسیم کرتا ہے، ہر شریک ان میں سے صرف چند کو اسٹور اور تقسیم کرتا ہے۔ شاید متضاد طور پر، یہ نقطہ نظر ضروری طور پر ڈیٹا کی مضبوطی کو بھی کم نہیں کرتا ہے۔ اگر، نوڈس کو چلانے کے لیے اسے زیادہ سستی بنا کر، ہم 100,000 نوڈس کے ساتھ ایک نیٹ ورک بنا سکتے ہیں، جہاں ہر نوڈ تاریخ کا ایک بے ترتیب 10% ذخیرہ کرتا ہے، تو ڈیٹا کے ہر ٹکڑے کو 10,000 بار نقل کیا جائے گا – بالکل وہی نقل کرنے والا عنصر جو 10,000 کے برابر ہے۔ -نوڈ نیٹ ورک، جہاں ہر نوڈ ہر چیز کو اسٹور کرتا ہے۔
آج، Ethereum ایک ایسے ماڈل سے دور ہونا شروع ہو گیا ہے جہاں تمام نوڈس تمام تاریخ کو مستقل طور پر محفوظ کرتے ہیں۔ اتفاق رائے کے بلاکس (یعنی ثبوت سے متعلق اتفاق رائے سے متعلق حصہ) صرف 6 ماہ کے لیے محفوظ کیے جاتے ہیں۔ بلاب صرف 18 دنوں کے لیے محفوظ کیے جاتے ہیں۔ EIP-4444 تاریخی بلاکس اور رسیدوں کے لیے ایک سال کی سٹوریج کی مدت متعارف کرانے کا مقصد۔ طویل مدتی مقصد ایک یکساں مدت (شاید تقریباً 18 دن) قائم کرنا ہے جس کے دوران ہر نوڈ ہر چیز کو ذخیرہ کرنے کے لیے ذمہ دار ہوتا ہے، اور پھر Ethereum نوڈس کا ایک پیر ٹو پیر نیٹ ورک قائم کرتا ہے جو پرانے ڈیٹا کو تقسیم شدہ نیٹ ورک کے انداز میں اسٹور کرتا ہے۔
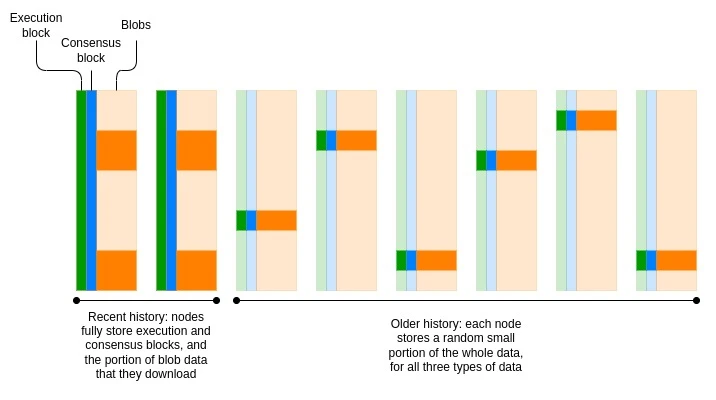
مٹانے والے کوڈز کو نقل کے عنصر کو یکساں رکھتے ہوئے مضبوطی کو بہتر بنانے کے لیے استعمال کیا جا سکتا ہے۔ درحقیقت، ڈیٹا کی دستیابی کے نمونے لینے میں مدد کے لیے بلاب پہلے سے ہی مٹانے والے کوڈ شدہ ہیں۔ سب سے آسان حل شاید یہ ہے کہ اس طرح کے مٹانے والے کوڈز کو دوبارہ استعمال کیا جائے اور عمل درآمد اور اتفاق رائے کے بلاک ڈیٹا کو بھی بلاب میں ڈال دیا جائے۔
EIP-4444 ;
باقی اہم کام میں تاریخ کو ذخیرہ کرنے کے لیے ایک ٹھوس تقسیم شدہ حل کی تعمیر اور انضمام شامل ہے – کم از کم عملدرآمد کی تاریخ، لیکن آخر کار اتفاق رائے اور بلاب بھی۔ سب سے آسان حل ہیں (i) صرف موجودہ ٹورینٹ لائبریریوں کو لانا، اور (ii) ایک ایتھریم مقامی حل پورٹل نیٹ ورکس . ان میں سے کسی ایک کے متعارف ہونے کے بعد، ہم EIP-4444 کو آن کر سکتے ہیں۔ EIP-4444 کو خود سخت کانٹے کی ضرورت نہیں ہے، لیکن اس کے لیے ایک نئے نیٹ ورک پروٹوکول ورژن کی ضرورت ہے۔ اس لیے، اسے تمام کلائنٹس کے لیے ایک ہی وقت میں فعال کرنا قابل قدر ہے، بصورت دیگر کلائنٹس کے ناکام ہونے کا خطرہ ہے کیونکہ وہ مکمل ہسٹری ڈاؤن لوڈ کرنے کی توقع کرتے ہوئے دوسرے نوڈس سے جڑ جاتے ہیں لیکن حقیقت میں اسے حاصل نہیں ہوتا ہے۔
اہم تجارت میں شامل ہے کہ ہم "قدیم" تاریخ کا ڈیٹا دستیاب کرنے کے لیے کتنی محنت کرتے ہیں۔ سب سے آسان حل یہ ہے کہ کل قدیم تاریخ کو ذخیرہ کرنا بند کر دیا جائے اور نقل کے لیے موجودہ آرکائیو نوڈس اور مختلف مرکزی فراہم کنندگان پر انحصار کریں۔ یہ آسان ہے، لیکن یہ Ethereum کو ریکارڈ کی مستقل جگہ کے طور پر کمزور کر دیتا ہے۔ زیادہ مشکل لیکن محفوظ راستہ یہ ہے کہ تاریخ کو تقسیم شدہ طریقے سے ذخیرہ کرنے کے لیے پہلے ٹورینٹ نیٹ ورک کی تعمیر اور انٹیگریٹ کیا جائے۔ یہاں، "ہم کتنی محنت کرتے ہیں" کی دو جہتیں ہیں:
ہم یہ کیسے یقینی بنانے کی کوشش کرتے ہیں کہ نوڈس کا سب سے بڑا سیٹ درحقیقت تمام ڈیٹا کو اسٹور کرتا ہے؟
ہم پروٹوکول میں تاریخ کے ذخیرہ کو کتنی گہرائی سے ضم کرتے ہیں؟
(1) کے لیے ایک انتہائی بے وقوفانہ نقطہ نظر شامل ہوگا۔ حراست کا ثبوت : مؤثر طریقے سے ہر ایک ثبوت کی تصدیق کرنے والے کو تاریخ کا ایک خاص فیصد ذخیرہ کرنے کی ضرورت ہوتی ہے، اور وقتاً فوقتاً کرپٹوگرافک طور پر جانچنا کہ وہ ایسا کر رہے ہیں۔ ایک زیادہ اعتدال پسند نقطہ نظر یہ ہوگا کہ ہر کلائنٹ کی تاریخ کے کتنے فیصد ذخیرہ کرنے کے لیے رضاکارانہ معیار مقرر کیا جائے۔
(2) کے لیے، بنیادی نفاذ میں صرف وہ کام شامل ہوتا ہے جو آج پہلے سے ہو چکا ہے: پورٹل پہلے سے ہی ایک ERA فائل کو اسٹور کرتا ہے جس میں Ethereum کی پوری تاریخ ہے۔ مزید مکمل عمل درآمد میں اصل میں اسے مطابقت پذیری کے عمل سے جوڑنا شامل ہوگا، تاکہ اگر کوئی مکمل ہسٹری اسٹوریج نوڈ یا آرکائیو نوڈ کو ہم آہنگ کرنا چاہتا ہے، تو وہ پورٹل نیٹ ورک سے براہ راست مطابقت پذیری کرکے ایسا کرسکتے ہیں، چاہے کوئی اور آرکائیو نوڈ آن لائن موجود نہ ہو۔ .
اگر ہم نوڈ کو چلانے یا گھمانے میں انتہائی آسان بنانا چاہتے ہیں، تو تاریخ کے ذخیرہ کی ضروریات کو کم کرنا بے وطنی سے زیادہ اہم ہے: 1.1 TB میں سے ایک نوڈ کی ضرورت ہوتی ہے، ~ 300 GB ریاست ہے، اور بقیہ ~ 800 GB تاریخ ہے۔ . صرف بے وطنی اور EIP-4444 کے ساتھ ہی ہم اسمارٹ واچ پر Ethereum نوڈ چلانے اور اسے صرف چند منٹوں میں ترتیب دینے کا وژن حاصل کر سکتے ہیں۔
تاریخی اسٹوریج کو محدود کرنا نئے Ethereum نوڈ کے نفاذ کے لیے صرف پروٹوکول کے تازہ ترین ورژن کو سپورٹ کرنا زیادہ ممکن بناتا ہے، جو انہیں بہت آسان بنا دیتا ہے۔ مثال کے طور پر، کوڈ کی بہت سی لائنوں کو اب محفوظ طریقے سے ہٹایا جا سکتا ہے کیونکہ 2016 کے DoS حملے کے دوران بنائے گئے خالی اسٹوریج سلاٹس حذف کر دیا گیا . اب چونکہ پروف آف اسٹیک کی طرف منتقل ہونا تاریخ ہے، کلائنٹ کام سے متعلق تمام کوڈ کو محفوظ طریقے سے ہٹا سکتے ہیں۔
یہاں تک کہ اگر ہم کلائنٹس کی تاریخ کو ذخیرہ کرنے کی ضرورت کو ختم کر دیتے ہیں، تب بھی کلائنٹ کی اسٹوریج کی ضروریات ہر سال تقریباً 50 GB تک بڑھتی رہیں گی، جیسا کہ ریاست بڑھ رہی ہے: اکاؤنٹ بیلنس اور نانس، کنٹریکٹ کوڈ، اور کنٹریکٹ اسٹوریج۔ صارفین ایک بار کی فیس ادا کر سکتے ہیں، اس طرح موجودہ اور مستقبل کے ایتھرئم کلائنٹس پر ہمیشہ کے لیے بوجھ پڑے گا۔
ریاست کی میعاد ختم ہونا تاریخ سے زیادہ مشکل ہے، کیونکہ ای وی ایم بنیادی طور پر اس مفروضے کے ارد گرد ڈیزائن کیا گیا ہے کہ ایک بار ریاستی چیز بن جانے کے بعد، یہ ہمیشہ موجود رہتی ہے اور کسی بھی وقت کسی بھی لین دین کے ذریعے پڑھی جا سکتی ہے۔ اگر ہم بے وطنی کو متعارف کراتے ہیں، تو کچھ لوگوں کا خیال ہے کہ یہ مسئلہ اتنا برا نہیں ہو سکتا: صرف خصوصی بلاک بلڈر کلاسوں کو ریاست کو اصل میں ذخیرہ کرنے کی ضرورت ہے، اور دیگر تمام نوڈس (یہاں تک کہ لسٹ جنریشن بھی!) بے وطنی سے چل سکتے ہیں۔ تاہم، ایک دلیل یہ ہے کہ ہم بے وطنی پر بہت زیادہ انحصار نہیں کرنا چاہتے، اور آخر کار ہم ایتھرئم کو وکندریقرت رکھنے کے لیے ریاست کو ختم کرنا چاہتے ہیں۔
آج، جب آپ ایک نیا اسٹیٹ آبجیکٹ بناتے ہیں (جو تین طریقوں میں سے کسی ایک میں ہو سکتا ہے: (i) ETH کو نئے اکاؤنٹ میں بھیجنا، (ii) کوڈ کا استعمال کرتے ہوئے ایک نیا اکاؤنٹ بنانا، (iii) پہلے سے اچھوتا اسٹوریج سلاٹ ترتیب دینا) ، وہ ریاستی چیز ہمیشہ کے لئے اسی حالت میں رہتی ہے۔ اس کے بجائے، ہم جو چاہتے ہیں وہ یہ ہے کہ اشیاء وقت کے ساتھ خود بخود ختم ہو جائیں۔ کلیدی چیلنج یہ ہے کہ اس طرح سے تین مقاصد حاصل کیے جائیں:
کارکردگی: میعاد ختم ہونے کے عمل کو چلانے کے لیے کسی خاص رقم کی اضافی گنتی کی ضرورت نہیں ہے۔
صارف دوستی: اگر کوئی پانچ سال کے لیے غار میں جاتا ہے اور واپس آتا ہے، تو اسے اپنی ETH، ERC 20، NFT، CDP پوزیشنز تک رسائی سے محروم نہیں ہونا چاہیے…
ڈویلپر دوستی: ڈویلپرز کو مکمل طور پر غیر مانوس ذہنی ماڈل پر سوئچ کرنے کی ضرورت نہیں ہے۔ نیز، فی الحال ossified اور unupdated ایپلی کیشنز کو ٹھیک کام کرنا جاری رکھنا چاہیے۔
ان مسائل کو حل کرنا آسان ہے جو ان مقاصد کو پورا نہیں کرتے ہیں۔ مثال کے طور پر، آپ ہر اسٹیٹ آبجیکٹ کے پاس ایک میعاد ختم ہونے کی تاریخ کا کاؤنٹر بھی رکھ سکتے ہیں (ختم ہونے کی تاریخ کو ETH جلا کر بڑھایا جا سکتا ہے، جو خود بخود کسی بھی وقت پڑھا یا لکھا جا سکتا ہے)، اور ایک ایسا عمل ہو سکتا ہے جو ریاست میں ختم ہونے والی میعاد ختم کرنے کے لیے گزر جائے۔ ریاستی اشیاء. تاہم، یہ اضافی حساب کتاب (اور یہاں تک کہ اسٹوریج کی ضروریات) کو بھی متعارف کراتا ہے، اور یہ یقینی طور پر صارف دوستی کی ضرورت کو پورا نہیں کرتا ہے۔ ڈویلپرز کے لیے ذخیرہ شدہ اقدار پر مشتمل کنارے کے معاملات کے بارے میں استدلال کرنا بھی مشکل ہے جو کبھی کبھی صفر پر دوبارہ سیٹ ہو جاتے ہیں۔ اگر آپ معاہدے کے دائرہ کار کے اندر ایکسپائری ٹائمرز سیٹ کرتے ہیں، تو اس سے ڈویلپرز کی زندگی تکنیکی طور پر آسان ہو جاتی ہے، لیکن اس سے معاشیات مزید مشکل ہو جاتی ہے: ڈویلپر کو یہ سوچنا پڑتا ہے کہ ذخیرہ کرنے کے جاری اخراجات صارف تک کیسے پہنچائے جائیں۔
یہ وہ مسائل ہیں جن پر ایتھرئم کور ڈویلپمنٹ کمیونٹی برسوں سے کام کر رہی ہے، بشمول تجاویز جیسے کہ " بلاکچین کرایہ "اور" تخلیق نو " بالآخر، ہم نے تجاویز کے بہترین حصوں کو یکجا کیا اور "کم سے کم بدترین معلوم حل" کی دو اقسام پر توجہ مرکوز کی:
جزوی حیثیت کی میعاد ختم ہونے کا حل
ایڈریس سائیکل پر مبنی ریاست کی میعاد ختم ہونے کی سفارشات۔
جزوی ریاست کی میعاد ختم ہونے کی تجاویز سبھی ایک ہی اصول پر عمل کرتی ہیں۔ ہم نے ریاست کو ٹکڑوں میں تقسیم کیا۔ ہر ایک مستقل طور پر ایک اعلی سطحی نقشہ ذخیرہ کرتا ہے جہاں حصہ یا تو خالی یا غیر خالی ہوتا ہے۔ ہر حصے میں موجود ڈیٹا کو صرف اس صورت میں محفوظ کیا جاتا ہے جب اس ڈیٹا تک حال ہی میں رسائی حاصل کی گئی ہو۔ ایک قیامت کا طریقہ کار ہے جو ٹکڑا کو دوبارہ زندہ کرتا ہے اگر اسے مزید ذخیرہ نہیں کیا جاتا ہے۔
ان تجاویز کے درمیان بنیادی فرق یہ ہیں: (i) ہم کیسے؟ define "حال ہی میں"، اور (ii) ہم "بلاک" کی وضاحت کیسے کرتے ہیں؟ ایک مخصوص تجویز ہے۔ EIP-7736 ، جو "تنے اور پتی" کے ڈیزائن پر بنتا ہے۔ ورکل کے درختوں کے لیے متعارف کرایا گیا۔ (اگرچہ بے وطن ریاست کی کسی بھی شکل کے ساتھ مطابقت رکھتا ہے، جیسے بائنری درخت)۔ اس ڈیزائن میں، ہیڈر، کوڈ، اور اسٹوریج سلاٹ جو ایک دوسرے سے ملحق ہیں ایک ہی "ٹرنک" کے نیچے محفوظ کیے جاتے ہیں۔ ایک تنے کے نیچے ذخیرہ شدہ ڈیٹا 256*31 = 7,936 بائٹس تک ہو سکتا ہے۔ بہت سے معاملات میں، اکاؤنٹ کا پورا ہیڈر اور کوڈ، نیز بہت سے کلیدی سٹوریج سلاٹس، ایک ہی ٹرنک کے نیچے محفوظ کیے جائیں گے۔ اگر کسی دیے گئے ٹرنک کے نیچے کا ڈیٹا 6 مہینوں سے پڑھا یا لکھا نہیں گیا ہے، تو ڈیٹا کو مزید محفوظ نہیں کیا جاتا ہے، اور اس ڈیٹا کے لیے صرف 32 بائٹ کی کمٹمنٹ ("سٹب") محفوظ کی جاتی ہے۔ اس ڈیٹا تک رسائی حاصل کرنے والے مستقبل کے لین دین کو ڈیٹا کو "دوبارہ زندہ" کرنے اور اس بات کا ثبوت فراہم کرنے کی ضرورت ہوگی کہ یہ اسٹب کے خلاف چیک کرتا ہے۔
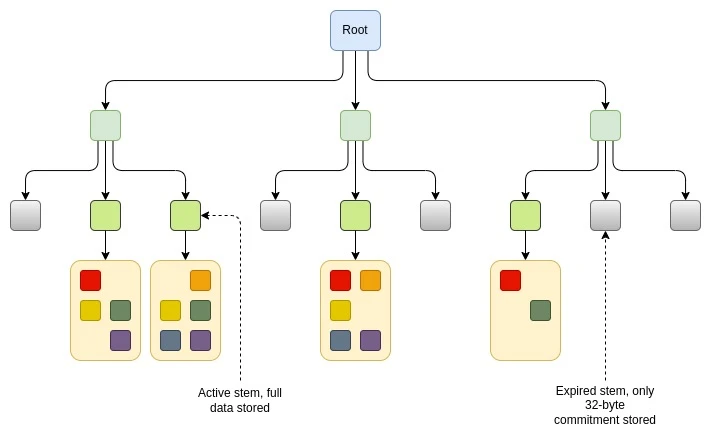
اسی طرح کے خیالات کو نافذ کرنے کے دوسرے طریقے بھی ہیں۔ مثال کے طور پر، اگر اکاؤنٹ کی سطح کی گرانولریٹی کافی نہیں ہے، تو ہم ایک اسکیم بنا سکتے ہیں جہاں درخت کے ہر 1/2 32 حصے کو اسی طرح کے تنے اور پتوں کے طریقہ کار سے کنٹرول کیا جاتا ہے۔
مراعات کی وجہ سے یہ مزید مشکل بنا دیا گیا ہے: ایک حملہ آور اپنے کلائنٹس کو ایک ہی ذیلی درخت میں بڑی مقدار میں ڈیٹا ڈال کر اور درخت کو اپ ڈیٹ کرنے کے لیے ہر سال ایک ہی ٹرانزیکشن بھیج کر مستقل طور پر ریاست کی بڑی مقدار کو ذخیرہ کرنے پر مجبور کر سکتا ہے۔ اگر آپ تجدید کی لاگت کو درخت کے سائز کے متناسب بناتے ہیں (یا تجدید کی مدت کے الٹا متناسب)، تو کوئی بھی دوسرے صارفین کو ان کی طرح کے سب ٹری میں بڑی مقدار میں ڈیٹا ڈال کر ممکنہ طور پر نقصان پہنچا سکتا ہے۔ ذیلی درخت کے سائز کے حوالے سے گرینولریٹی کو متحرک بنا کر ان دونوں مسائل کو محدود کرنے کی کوشش کی جا سکتی ہے: مثال کے طور پر، ہر ایک لگاتار 216 = 65536 ریاستی اشیاء کو ایک گروپ سمجھا جا سکتا ہے۔ تاہم، یہ خیالات زیادہ پیچیدہ ہیں۔ اسٹیم پر مبنی نقطہ نظر آسان ہیں، اور مراعات کو ہم آہنگ کیا جاسکتا ہے کیونکہ عام طور پر اسٹیم کے نیچے موجود تمام ڈیٹا کا تعلق ایک ہی ایپلیکیشن یا صارف سے ہوتا ہے۔
کیا ہوگا اگر ہم کسی بھی مستقل ریاست کی نمو سے بچنا چاہتے ہیں، یہاں تک کہ 32 بائٹ اسٹب؟ کی وجہ سے یہ ایک مشکل مسئلہ ہے۔ قیامت کے تنازعات : کیا ہوگا اگر کوئی اسٹیٹ آبجیکٹ حذف ہو جائے، اور بعد میں ای وی ایم پر عمل درآمد ایک اور ریاستی چیز کو بالکل اسی جگہ پر رکھتا ہے، لیکن پھر کوئی جو اصل ریاستی چیز کی پرواہ کرتا ہے واپس آکر اسے بحال کرنے کی کوشش کرتا ہے؟ جب ریاست کے حصے کی میعاد ختم ہو جاتی ہے، تو اسٹب نئے ڈیٹا کو بننے سے روکتا ہے۔ ریاست کی مکمل میعاد ختم ہونے کے بعد، ہم سٹب کو ذخیرہ بھی نہیں کر سکتے۔
ایڈریس سائیکل پر مبنی ڈیزائن اس مسئلے کو حل کرنے کے لیے سب سے مشہور خیال ہے۔ ایک ریاستی درخت پوری ریاست کو ذخیرہ کرنے کے بجائے، ہمارے پاس ریاستی درختوں کی ایک بڑھتی ہوئی فہرست ہے، اور کوئی بھی ریاست پڑھی یا لکھی گئی ہے اسے تازہ ترین ریاستی درخت میں محفوظ کیا جاتا ہے۔ ایک نیا خالی ریاستی درخت ہر دور میں ایک بار شامل کیا جاتا ہے (مثال کے طور پر: 1 سال)۔ پرانے درخت ٹھوس جمے ہوئے ہیں۔ مکمل نوڈس صرف دو تازہ ترین درختوں کو محفوظ کرتے ہیں۔ اگر کسی ریاستی چیز کو دو ادوار میں چھوا نہیں گیا ہے اور اس طرح وہ میعاد ختم ہونے والے درخت میں گر جاتا ہے، تو اسے اب بھی پڑھا یا لکھا جا سکتا ہے، لیکن لین دین کو اس کے مرکل ثبوت کو ثابت کرنے کی ضرورت ہے - ایک بار ثابت ہونے کے بعد، ایک کاپی تازہ ترین درخت میں دوبارہ محفوظ کی جاتی ہے۔

ایک اہم خیال جو اس صارف اور ڈویلپر کے لیے دوستانہ بناتا ہے وہ ایڈریس پیریڈز کا تصور ہے۔ ایڈریس کا دورانیہ ایک ایسا نمبر ہے جو ایڈریس کا حصہ ہے۔ کلیدی اصول یہ ہے کہ ایڈریس پیریڈ N والا ایڈریس صرف N دورانیے یا اس کے بعد پڑھا یا لکھا جا سکتا ہے (یعنی جب ریاستی درخت کی فہرست لمبائی N تک پہنچ جائے)۔ اگر آپ ایک نیا اسٹیٹ آبجیکٹ (مثلاً، ایک نیا معاہدہ، یا ایک نیا ERC 20 بیلنس) محفوظ کر رہے ہیں، اگر آپ اس بات کو یقینی بناتے ہیں کہ آپ نے ریاستی آبجیکٹ کو ایڈریس پیریڈ N یا N-1 کے ساتھ کسی معاہدے میں رکھا ہے، تو آپ اسے فوری طور پر محفوظ کر سکتے ہیں۔ بغیر ثبوت فراہم کیے کہ پہلے وہاں کچھ نہیں تھا۔ دوسری طرف، پرانے ایڈریس کی مدت کے دوران کیے گئے کسی بھی اضافے یا ترمیم کے لیے ثبوت کی ضرورت ہوگی۔
یہ ڈیزائن Ethereums کی زیادہ تر موجودہ خصوصیات کو برقرار رکھتا ہے، اضافی حساب کتاب کی ضرورت نہیں ہے، ایپلی کیشنز کو تقریباً اسی طرح لکھنے کی اجازت دیتا ہے جیسا کہ وہ اب ہیں (ERC 20 کو دوبارہ لکھنے کی ضرورت ہے تاکہ اس بات کو یقینی بنایا جا سکے کہ ایڈریس سائیکل N کے ساتھ ایڈریس بیلنس ذیلی کنٹریکٹس میں محفوظ ہیں، جن کا خود ایڈریس ہے۔ cycle N)، اور غاروں میں موجود صارفین کو پانچ سال کا مسئلہ حل کرتا ہے۔ تاہم، اس میں ایک بڑا مسئلہ ہے: ایڈریس سائیکل کو ایڈجسٹ کرنے کے لیے پتوں کو 20 سے زیادہ بائٹس تک پھیلانے کی ضرورت ہے۔
ایک تجویز یہ ہے کہ ایک نیا 32 بائٹ ایڈریس فارمیٹ متعارف کرایا جائے جس میں ورژن نمبر، ایڈریس سائیکل نمبر، اور توسیعی ہیش شامل ہو۔
0x 01 (سرخ) 0000 (نارنجی) 000001 (سبز) 57 aE 408398 ڈی ایف 7 ای 5 f 4552091 اے 69125 d5 ایف ڈبلیو ایف 7 بی 8 سی 2659029395 bdF (نیلا)۔
سرخ ورژن نمبر ہے۔ یہاں چار نارنجی زیرو کا مقصد خالی جگہیں ہیں جو مستقبل میں شارڈ نمبرز کو ایڈجسٹ کر سکتی ہیں۔ سبز ایک پتہ سائیکل نمبر ہے۔ نیلی ایک 26 بائٹ ہیش ویلیو ہے۔
یہاں اہم چیلنج پسماندہ مطابقت ہے۔ موجودہ معاہدوں کو 20-بائٹ پتوں کے ارد گرد ڈیزائن کیا گیا ہے، اور اکثر سخت بائٹ پیکنگ تکنیک استعمال کرتے ہیں جو واضح طور پر فرض کرتے ہیں کہ پتے بالکل 20 بائٹس لمبے ہیں۔ اس سے نمٹنے کے لیے ایک خیال ایک کنورژن میپنگ شامل ہے، جہاں نئے طرز کے پتوں کے ساتھ تعامل کرنے والے میراثی معاہدے نئے طرز کے پتے کی 20 بائٹ ہیش دیکھیں گے۔ تاہم، اس کے محفوظ ہونے کو یقینی بنانے میں اہم پیچیدگیاں ہیں۔
ایک اور نقطہ نظر مخالف سمت میں جاتا ہے: ہم فوری طور پر سائز 2 128 کے کچھ ذیلی رینج پر پابندی لگاتے ہیں (مثال کے طور پر، تمام پتے 0x ffffffff سے شروع ہوتے ہیں)، اور پھر اس رینج کو ایڈریس سائیکل اور 14 بائٹ ہیش ویلیوز والے ایڈریس متعارف کرانے کے لیے استعمال کرتے ہیں۔
0x ffffffff 000169125 d5 ایف ڈبلیو ایف 7 بی 8 C2659029395bdF
اس نقطہ نظر کی طرف سے کی گئی اہم قربانی ہے جعلی پتے متعارف کروانے کا سیکیورٹی خطرہ : وہ پتے جن میں اثاثے یا اجازتیں ہیں لیکن جن کا کوڈ ابھی تک سلسلہ میں شائع نہیں ہوا ہے۔ خطرے میں کوئی ایسا ایڈریس بنانا شامل ہے جو دعویٰ کرتا ہے کہ وہ (ابھی تک غیر مطبوعہ) کوڈ کے ایک ٹکڑے کا مالک ہے، لیکن اس کے پاس کوڈ کا ایک اور درست ٹکڑا بھی ہے جو اسی پتے پر ہیش کرتا ہے۔ آج اس طرح کے تصادم کا حساب لگانے کے لیے 2 80 ہیشز کی ضرورت ہے۔ ایڈریس اسپیس سکڑنا اس نمبر کو آسانی سے قابل رسائی 2 56 ہیشز تک کم کر دے گا۔
کلیدی رسک ایریا، بٹوے کے لیے متضاد پتے جو کسی ایک مالک کے پاس نہیں ہیں، آج نسبتاً نایاب ہے، لیکن جب ہم ملٹی L2 دنیا میں جائیں گے تو یہ زیادہ عام ہو جائے گا۔ اس کا واحد حل صرف یہ ہے کہ اس خطرے کو قبول کیا جائے، لیکن عام استعمال کے تمام معاملات کی نشاندہی کی جائے جہاں یہ غلط ہو سکتا ہے، اور مؤثر حل کے ساتھ سامنے آئیں۔
ابتدائی تجاویز
تخلیق نو ;
جزوی حیثیت ختم ہونے کی تجویز
EIP-7736 ;
ایڈریس اسپیس ایکسٹینشن دستاویزات
میں آگے کے چار ممکنہ راستے دیکھ رہا ہوں:
ہم اسے بے وطن بناتے ہیں، اور کبھی بھی ریاست کی میعاد ختم نہیں کرتے۔ ریاست بڑھ رہی ہے (اگرچہ آہستہ آہستہ: ہم شاید اسے کئی دہائیوں تک 8 ٹی بی سے زیادہ نہیں دیکھیں گے)، لیکن صرف صارفین کے نسبتاً خاص طبقے کے ذریعہ: یہاں تک کہ پی او ایس کی تصدیق کرنے والوں کو بھی ریاست کی ضرورت نہیں ہے۔
ایک خصوصیت جس کے لیے ریاست کے حصے تک رسائی کی ضرورت ہوتی ہے وہ ہے شمولیت کی فہرست تیار کرنا، لیکن ہم اسے وکندریقرت طریقے سے کر سکتے ہیں: ہر صارف ریاستی کوشش کے اس حصے کو برقرار رکھنے کا ذمہ دار ہے جس میں ان کا اپنا اکاؤنٹ ہے۔ جب وہ کسی لین دین کو نشر کرتے ہیں، تو وہ اسے تصدیقی مرحلے کے دوران ریاستی اشیاء کے ثبوتوں کے ساتھ نشر کرتے ہیں (یہ EOA اور ERC-4337 اکاؤنٹس دونوں کے لیے کام کرتا ہے)۔ ریاست کے بغیر تصدیق کنندہ پھر ان ثبوتوں کو مکمل شمولیت کی فہرست کے ثبوت میں جوڑ سکتا ہے۔
ہم جزوی حالت کی میعاد ختم کرتے ہیں اور بہت کم لیکن پھر بھی غیر صفر مستقل ریاست کے سائز کی شرح نمو قبول کرتے ہیں۔ یہ نتیجہ معقول طور پر اس سے ملتا جلتا ہے کہ کس طرح تاریخ کی میعاد ختم ہونے کی تجاویز جس میں پیئر ٹو پیئر نیٹ ورک شامل ہیں بہت کم لیکن پھر بھی غیر صفر مستقل ہسٹری اسٹوریج گروتھ ریٹ کو قبول کرتے ہیں جہاں ہر کلائنٹ کو تاریخ کے ڈیٹا کا کم لیکن مقررہ فیصد ذخیرہ کرنا ہوتا ہے۔
ہم ایڈریس اسپیس ایکسٹینشن کے ذریعے اسٹیٹ ایکسپائریشن کر رہے ہیں۔ اس میں ایک کثیر سالہ عمل شامل ہو گا تاکہ یہ یقینی بنایا جا سکے کہ ایڈریس فارمیٹ کی تبدیلی کا طریقہ موثر اور محفوظ ہے، بشمول موجودہ ایپلی کیشنز کے لیے۔
ہم ایڈریس اسپیس کو سکڑ کر ریاست کی میعاد ختم کرتے ہیں۔ اس میں ایک کثیر سالہ عمل شامل ہو گا تاکہ اس بات کو یقینی بنایا جا سکے کہ ایڈریس کے تنازعات (بشمول کراس چین حالات) کے تمام حفاظتی خطرات سے نمٹا جائے۔
اہم نکتہ یہ ہے کہ ریاستی میعاد ختم ہونے کی اسکیم جو ایڈریس فارمیٹ کی تبدیلیوں پر انحصار کرتی ہے لاگو ہو یا نہ ہو، پتہ کی جگہ کی توسیع اور سکڑاؤ کا مشکل مسئلہ بالآخر حل ہونا چاہیے۔ آج، ایڈریس تصادم پیدا کرنے کے لیے تقریباً 2 80 ہیشز کی ضرورت ہوتی ہے، اور یہ کمپیوٹیشنل لوڈ انتہائی وسائل والے اداکاروں کے لیے پہلے سے ہی قابل عمل ہے: ایک GPU تقریباً 2 27 ہیشز انجام دے سکتا ہے، اس لیے یہ ایک سال میں 2 52 کا حساب لگا سکتا ہے، لہذا تمام دنیا میں تقریباً 230 GPUs ایک سال کے تقریباً 1/4 میں تصادم کا حساب لگا سکتا ہے، اور FPGAs اور ASICs اس عمل کو مزید تیز کر سکتے ہیں۔ مستقبل میں اس طرح کے حملے زیادہ سے زیادہ لوگوں کے لیے کھلے رہیں گے۔ لہٰذا، مکمل ریاستی میعاد کے نفاذ کی اصل لاگت اتنی زیادہ نہیں ہو سکتی جتنی کہ لگتا ہے، کیونکہ ہمیں اس انتہائی مشکل ایڈریس کے مسئلے کو بہرحال حل کرنا ہے۔
ریاست کی میعاد ختم ہونے سے ایک ریاستی ٹرائی فارمیٹ سے دوسرے میں منتقلی آسان ہو سکتی ہے، کیونکہ کسی تبدیلی کے عمل کی ضرورت نہیں ہے: آپ آسانی سے نئے فارمیٹ کے ساتھ ایک نیا درخت بنانا شروع کر سکتے ہیں، اور پھر پرانے درخت کو تبدیل کرنے کے لیے سخت کانٹا لگا سکتے ہیں۔ لہٰذا جب کہ ریاست کی میعاد ختم کرنا پیچیدہ ہے، اس کے لیے روڈ میپ کے دیگر پہلوؤں کو آسان بنانے کا فائدہ ہے۔
کے لیے کلیدی شرائط میں سے ایک سیکورٹی، رسائی، اور قابل اعتماد غیر جانبداری سادگی ہے. اگر پروٹوکول خوبصورت اور سادہ ہے تو اس میں کیڑے ہونے کا امکان کم ہوتا ہے۔ اس سے یہ امکانات بڑھ جاتے ہیں کہ نئے ڈویلپرز اس کے کسی بھی حصے میں حصہ لے سکیں گے۔ خاص مفادات کے خلاف دفاع کے لیے اس کے منصفانہ اور آسان ہونے کا زیادہ امکان ہے۔ بدقسمتی سے، پروٹوکول، کسی بھی سماجی نظام کی طرح، وقت کے ساتھ ساتھ پہلے سے زیادہ پیچیدہ ہو جائیں گے۔ اگر ہم نہیں چاہتے ہیں کہ Ethereum بڑھتی ہوئی پیچیدگی کے بلیک ہول میں گرے، تو ہمیں دو چیزوں میں سے ایک کرنے کی ضرورت ہے: (i) تبدیلیاں کرنا اور پروٹوکول کو ossify کرنا، یا (ii) فیچرز کو ہٹانے اور پیچیدگی کو کم کرنے کے قابل ہونا۔ . ایک درمیانی راستہ بھی ممکن ہے، پروٹوکول میں کم تبدیلیاں کرنا اور وقت کے ساتھ ساتھ کم از کم تھوڑی سی پیچیدگی کو دور کرنا۔ اس حصے میں پیچیدگی کو کم کرنے یا ختم کرنے کے طریقے پر بحث کی گئی ہے۔
کوئی بڑا واحد حل نہیں ہے جو پروٹوکول کی پیچیدگی کو کم کرے گا۔ مسئلے کی نوعیت یہ ہے کہ بہت سی چھوٹی چھوٹی اصلاحات ہیں۔
ایک مثال جو زیادہ تر مکمل ہو چکی ہے، اور دوسری مثالوں سے رجوع کرنے کا طریقہ ایک بلیو پرنٹ کے طور پر کام کر سکتی ہے۔ SELFDESTRUCT opcode کو ہٹانا . SELFDESTRUCT opcode وہ واحد آپکوڈ تھا جو ایک بلاک کے اندر لامحدود تعداد میں سٹوریج سلاٹس میں ترمیم کر سکتا تھا، جس کے لیے کلائنٹس کو DoS حملوں سے بچنے کے لیے نمایاں طور پر زیادہ پیچیدگی کو لاگو کرنے کی ضرورت ہوتی ہے۔ اوپکوڈ کا اصل مقصد رضاکارانہ ریاستی لیکویڈیشن کو فعال کرنا تھا، جس سے ریاست کا سائز وقت کے ساتھ کم ہوتا جا رہا تھا۔ عملی طور پر، بہت کم لوگوں نے اسے استعمال کیا۔ opcode nerfed کیا گیا تھا صرف ڈینکون ہارڈ فورک جیسے لین دین میں بنائے گئے خود کو تباہ کرنے والے اکاؤنٹس کی اجازت دینے کے لیے۔ یہ DoS کا مسئلہ حل کرتا ہے اور کلائنٹ کوڈ کو نمایاں طور پر آسان بنا سکتا ہے۔ مستقبل میں، آخرکار اوپکوڈ کو مکمل طور پر ہٹانا سمجھ میں آ سکتا ہے۔
پروٹوکول کو آسان بنانے کے مواقع کی آج تک شناخت کی گئی چند اہم مثالیں درج ذیل ہیں۔ سب سے پہلے، ای وی ایم سے باہر کی کچھ مثالیں؛ یہ نسبتاً غیر جارحانہ ہیں اور اس لیے کم وقت میں اتفاق رائے تک پہنچنا اور اس پر عمل درآمد کرنا آسان ہے۔
RLP → SSZ کی تبدیلی: اصل میں، Ethereum اشیاء کو ایک انکوڈنگ کا استعمال کرتے ہوئے سیریلائز کیا گیا تھا آر ایل پی . RLP غیر ٹائپ شدہ اور غیر ضروری طور پر پیچیدہ ہے۔ آج، بیکن چین استعمال کرتا ہے SSZ جو کہ کئی طریقوں سے نمایاں طور پر بہتر ہے، بشمول نہ صرف سیریلائزیشن کی حمایت کرنا بلکہ ہیشنگ بھی۔ آخر کار، ہم امید کرتے ہیں کہ RLP سے مکمل طور پر چھٹکارا حاصل کر لیں گے اور تمام ڈیٹا کی اقسام کو SSZ ڈھانچے میں منتقل کر دیں گے، جس کے نتیجے میں اپ گریڈ کرنا بہت آسان ہو جائے گا۔ موجودہ EIPs میں شامل ہیں۔ [1] [2] [3] .
میراثی لین دین کی اقسام کو ہٹانا: آج لین دین کی بہت سی اقسام ہیں، اور ان میں سے بہت سے ممکنہ طور پر ہٹائے جا سکتے ہیں۔ مکمل ہٹانے کا ایک زیادہ معمولی متبادل اکاؤنٹ کی تجریدی خصوصیت ہے، جس کے تحت سمارٹ اکاؤنٹس اگر چاہیں تو میراثی لین دین کو سنبھالنے اور ان کی توثیق کرنے کے لیے کوڈ پر مشتمل ہو سکتے ہیں۔
LOG ریفارم: لاگ تخلیق کے بلوم فلٹرز اور دیگر منطق پروٹوکول میں پیچیدگی کا اضافہ کرتے ہیں، لیکن اصل میں کلائنٹ استعمال نہیں کرتے کیونکہ یہ بہت سست ہے۔ ہم کر سکتے ہیں۔ ان خصوصیات کو ہٹا دیں اور متبادلات پر کام کریں، جیسے کہ SNARKs جیسی جدید ٹیکنالوجیز کا استعمال کرتے ہوئے پروٹوکول سے باہر وکندریقرت لاگ ریڈنگ ٹولز۔
آخرکار بیکن چین سنک کمیٹی میکانزم کو ہٹا دیں: مطابقت پذیری کمیٹی کا طریقہ کار اصل میں Ethereum کے لیے لائٹ کلائنٹ کی تصدیق کو فعال کرنے کے لیے متعارف کرایا گیا تھا۔ تاہم، یہ پروٹوکول کی پیچیدگی کو نمایاں طور پر بڑھاتا ہے۔ آخر کار، ہم کر سکیں گے۔ براہ راست SNARKs کا استعمال کرتے ہوئے Ethereum اتفاق رائے کی پرت کی تصدیق کریں۔ ، جو ایک وقف شدہ لائٹ کلائنٹ تصدیقی پروٹوکول کی ضرورت کو ختم کردے گا۔ ممکنہ طور پر، اتفاق رائے کی تبدیلی ہمیں ایک زیادہ مقامی لائٹ کلائنٹ پروٹوکول بنا کر Sync کمیٹی کو پہلے ہٹانے کے قابل بنا سکتی ہے جس میں Ethereum اتفاق رائے کی تصدیق کرنے والوں کے بے ترتیب ذیلی سیٹ سے دستخطوں کی تصدیق کرنا شامل ہے۔
ڈیٹا فارمیٹ یونیفیکیشن: آج، مرکل پیٹریسیا کے درختوں میں عمل درآمد کی حالت محفوظ ہے، اتفاق رائے کی حالت میں محفوظ ہے SSZ درخت ، اور blobs کے ذریعے پرعزم ہیں۔ KZG وعدے . مستقبل میں، یہ سمجھ میں آئے گا کہ بلاک ڈیٹا کے لیے ایک واحد متحد فارمیٹ اور ریاست کے لیے واحد متحد فارمیٹ ہو۔ یہ فارمیٹس تمام اہم تقاضوں کو پورا کریں گے: (i) سٹیٹ لیس کلائنٹس کے لیے سادہ ثبوت، (ii) ڈیٹا کی سیریلائزیشن اور ایریزور کوڈنگ، اور (iii) معیاری ڈیٹا ڈھانچہ۔
بیکن چین کمیٹی کو ہٹانا: یہ طریقہ کار اصل میں مدد کے لیے متعارف کرایا گیا تھا۔ ایگزیکیوشن شارڈنگ کا ایک مخصوص ورژن . اس کے بجائے، ہم نے شارڈنگ ختم کی۔ L2 اور بلابز کے ذریعے . جیسا کہ کمیٹی غیر ضروری ہے، لہذا اسے ختم کرنے کے لیے اقدامات کیے جا رہے ہیں۔ .
مخلوط اینڈیننس کو ہٹا دیں: ای وی ایم بڑی اینڈین ہے، اتفاق کی پرت تھوڑی اینڈین ہے۔ یہ سمجھ میں آسکتا ہے کہ ہر چیز کو ایک یا دوسرے طریقے سے ملایا جائے (شاید بڑا اینڈین، کیونکہ ای وی ایم کو تبدیل کرنا مشکل ہے)
اب، ای وی ایم میں کچھ مثالیں:
گیس کے طریقہ کار کو آسان بنانا: موجودہ گیس کے قواعد کسی بلاک کی توثیق کے لیے درکار وسائل کی مقدار پر واضح حدیں دینے کے لیے اچھی طرح سے بہتر نہیں ہیں۔ اس کی اہم مثالوں میں شامل ہیں (i) سٹوریج پڑھنے/لکھنے کے اخراجات، جن کا مقصد بلاک میں پڑھنے/لکھنے کی تعداد کو محدود کرنا ہے لیکن فی الحال کافی صوابدیدی ہیں، اور (ii) میموری پیڈنگ کے اصول، جہاں فی الحال اندازہ لگانا مشکل ہے۔ ای وی ایم کی زیادہ سے زیادہ میموری کی کھپت۔ مجوزہ اصلاحات میں شامل ہیں۔ بے ریاست گیس کی قیمت میں تبدیلی (جو سٹوریج سے متعلقہ تمام اخراجات کو ایک سادہ فارمولے میں یکجا کرتا ہے) اور میموری کی قیمتوں کا تعین کرنے کی تجویز .
پری کمپائلز کو ہٹانا: Ethereum کے اس وقت موجود بہت سے پری کمپائلز غیر ضروری طور پر پیچیدہ اور نسبتاً غیر استعمال شدہ ہیں، اور کسی بھی ایپلی کیشنز کے بمشکل استعمال ہونے پر اتفاق رائے کی ناکامیوں کا ایک بڑا حصہ ہوتا ہے۔ اس سے نمٹنے کے دو طریقے ہیں (i) صرف پری کمپائل کو ہٹانا، اور (ii) اسے (لامحالہ زیادہ مہنگا) EVM کوڈ کے ٹکڑے سے تبدیل کرنا جو اسی منطق کو لاگو کرتا ہے۔ یہ مسودہ EIP تجویز کرتا ہے۔ پہلے قدم کے طور پر شناخت کی تیاری کے لیے ایسا کرنا؛ بعد میں، RIPEMD 160، MODEXP، اور BLAKE ہٹانے کے امیدوار بن سکتے ہیں۔
گیس کے مشاہدے کو ہٹا دیں: اسے اس طرح بنائیں کہ EVM پر عمل درآمد مزید یہ نہ دیکھ سکے کہ اس میں کتنی گیس رہ گئی ہے۔ اس سے کچھ ایپلیکیشنز ٹوٹ جائیں گی (خاص طور پر سپانسر شدہ لین دین)، لیکن مستقبل میں اپ گریڈ کرنا آسان بنا دے گا (مثلاً مزید جدید ورژن کے ساتھ کثیر جہتی گیس ). EOF کی تفصیلات پہلے سے ہی گیس کو ناقابل مشاہدہ بناتا ہے، لیکن پروٹوکول کو آسان بنانے کے لیے، EOF کو لازمی کرنے کی ضرورت ہے۔
جامد تجزیہ میں بہتری: آج کل EVM کوڈ کا جامد تجزیہ کرنا مشکل ہے، خاص طور پر اس لیے کہ چھلانگیں متحرک ہو سکتی ہیں۔ یہ ای وی ایم کے نفاذ کو بہتر بنانا بھی مشکل بناتا ہے (ای وی ایم کوڈ کو دوسری زبانوں میں پہلے سے مرتب کریں)۔ ہم اسے ٹھیک کر سکتے ہیں۔ متحرک چھلانگوں کو ہٹانا (یا ان کو زیادہ مہنگا بنانا، جیسے، معاہدے میں JUMPDESTs کی کل تعداد کی گیس کی قیمت میں لکیری)۔ EOF صرف اتنا ہی کرتا ہے، حالانکہ EOF کو نافذ کرنا اس سے پروٹوکول کو آسان بنانے کے فوائد حاصل کرنے کی ضرورت ہے۔
اضافی قابل تصدیق حساب کا استعمال کرتے ہوئے آف چین محفوظ لاگ بازیافت کا ایک طریقہ (پڑھیں: تکراری اسٹارکس)؛
اس قسم کی خصوصیت کو آسان بنانے میں اہم تجارتی نقصانات ہیں (i) ہم کتنی اور کتنی تیزی سے آسان بناتے ہیں بمقابلہ (ii) پیچھے کی طرف مطابقت۔ Ethereum کی زنجیر کے طور پر قدر اس کے ایک پلیٹ فارم کی وجہ سے آتی ہے جہاں آپ ایک ایپلیکیشن کو تعینات کر سکتے ہیں اور یقین رکھ سکتے ہیں کہ یہ برسوں بعد بھی کام کرے گا۔ ایک ہی وقت میں، اس مثالی کو بھی بہت دور لے جایا جا سکتا ہے اور، ولیم جیننگز برائن کے الفاظ میں , "پیچھے کی طرف مطابقت کے کراس پر Ethereum کیل لگائیں"۔ اگر تمام ایتھریم میں صرف دو ایپلی کیشنز ہیں جو ایک دی گئی خصوصیت کو استعمال کرتی ہیں، اور ایک ایپلی کیشن کے صارفین برسوں سے صفر ہیں، جب کہ دوسری ایپلیکیشن تقریباً مکمل طور پر غیر استعمال شدہ ہے اور اس نے مجموعی طور پر $57 کی قیمت حاصل کی ہے، تو ہمیں فیچر کو ہٹا دینا چاہیے۔ اور اگر ضرورت ہو تو متاثرہ کو جیب سے $57 ادا کریں۔
وسیع تر سماجی مسئلہ غیر فوری، پیچھے کی طرف مطابقت کو توڑنے والی تبدیلیاں کرنے کے لیے ایک معیاری پائپ لائن بنا رہا ہے۔ اس سے نمٹنے کا ایک طریقہ یہ ہے کہ موجودہ نظیروں کی جانچ پڑتال اور توسیع کی جائے، جیسے خود کو تباہ کرنے کا عمل۔ پائپ لائن کچھ اس طرح نظر آئے گی:
خصوصیت X کو ہٹانے کے بارے میں بات کرنا شروع کریں۔
درخواست پر X کو ہٹانے کے اثرات کا تعین کرنے کے لیے ایک تجزیہ کریں، اور نتائج پر منحصر ہے: (i) خیال کو ترک کریں، (ii) منصوبہ بندی کے مطابق آگے بڑھیں، یا (iii) X کو ہٹانے کے لیے ایک نظر ثانی شدہ "کم سے کم خلل ڈالنے والا" طریقہ طے کریں اور کارروائی
X کو فرسودہ کرنے کے لیے ایک رسمی EIP بنائیں۔ اس بات کو یقینی بنائیں کہ مقبول اعلیٰ سطحی انفراسٹرکچر (مثلاً پروگرامنگ زبانیں، بٹوے) اس کا احترام کریں اور خصوصیت کا استعمال بند کریں۔ ;
آخر میں، اصل میں X کو حذف کریں؛
مراحل 1 اور 4 کے درمیان ایک کثیر سالہ پائپ لائن ہونی چاہیے، جس میں یہ واضح ہو کہ کون سے منصوبے کس مرحلے میں ہیں۔ اس مقام پر، زیادہ قدامت پسند ہونے اور پروٹوکول کی ترقی کے دیگر شعبوں میں زیادہ وسائل کی سرمایہ کاری کے مقابلے میں خصوصیت کو ہٹانے کے عمل کی جوش اور رفتار کے درمیان تجارت ہے، لیکن ہم پیریٹو فرنٹیئر سے بہت دور ہیں۔
ای وی ایم میں تجویز کردہ تبدیلیوں کا اہم مجموعہ ہے۔ ای وی ایم آبجیکٹ فارمیٹ (EOF) . EOF نے بہت سی تبدیلیاں متعارف کرائی ہیں، جیسے کہ گیس کے مشاہدے کو غیر فعال کرنا، کوڈ آبزرویبلٹی (یعنی کوئی کوڈکوپی نہیں)، اور صرف جامد چھلانگ کی اجازت دینا۔ مقصد یہ ہے کہ EVM کو اس طریقے سے مزید اپ گریڈ کرنے کی اجازت دی جائے جس میں پسماندہ مطابقت کو برقرار رکھتے ہوئے مضبوط خصوصیات ہوں (کیونکہ EOF سے پہلے EVM اب بھی موجود ہے)۔
اس کا فائدہ یہ ہے کہ یہ نئی ای وی ایم خصوصیات کو شامل کرنے کے لیے ایک قدرتی راستہ بناتا ہے اور مضبوط ضمانتوں کے ساتھ سخت ای وی ایم میں منتقلی کی حوصلہ افزائی کرتا ہے۔ نقصان یہ ہے کہ یہ پروٹوکول کی پیچیدگی کو نمایاں طور پر بڑھاتا ہے جب تک کہ ہم آخرکار پرانی ای وی ایم کو فرسودہ اور ہٹانے کا راستہ تلاش نہ کر لیں۔ ایک اہم سوال یہ ہے کہ: EVM کو آسان بنانے کی تجویز میں EOF کیا کردار ادا کرتی ہے، خاص طور پر اگر مقصد پوری EVM کی پیچیدگی کو کم کرنا ہے؟
بقیہ روڈ میپ میں بہتری کی بہت سی تجاویز پرانی خصوصیات کو آسان بنانے کے مواقع بھی ہیں۔ مندرجہ بالا کچھ مثالوں کو دہرانے کے لیے:
سنگل سلاٹ فائنل پر جانے سے ہمیں کمیٹیوں کو ہٹانے، معاشیات کو دوبارہ ڈیزائن کرنے، اور اسٹیک سے متعلق دیگر آسانیاں بنانے کا موقع ملتا ہے۔
اکاؤنٹ کے خلاصے کو مکمل طور پر لاگو کرنے سے ہمیں بہت ساری موجودہ ٹرانزیکشن پروسیسنگ منطق کو ہٹانے اور اسے "ڈیفالٹ اکاؤنٹ ای وی ایم کوڈ" میں منتقل کرنے کی اجازت ملے گی جسے تمام EOAs تبدیل کر سکتے ہیں۔
اگر ہم ایتھرئم کی حالت کو بائنری ہیش ٹری میں منتقل کرتے ہیں، تو اسے SSZ کے نئے ورژن کے ساتھ ملایا جا سکتا ہے تاکہ تمام Ethereum ڈیٹا ڈھانچے کو اسی طرح ہیش کیا جا سکے۔
Ethereum کو آسان بنانے کے لیے ایک زیادہ بنیادی حکمت عملی یہ ہوگی کہ پروٹوکول کو برقرار رکھا جائے لیکن اس کا زیادہ تر حصہ پروٹوکول کی فعالیت سے دور اور کنٹریکٹ کوڈ میں منتقل کیا جائے۔
سب سے انتہائی ورژن Ethereum L1 "تکنیکی طور پر" صرف بیکن چین کا ہو گا، اور ایک کم سے کم ورچوئل مشین متعارف کرائے گا (جیسے RISC-V , قاہرہ ، یا کچھ اور بھی کم سے کم خاص طور پر پروف سسٹمز کے لیے) جو دوسروں کو اپنے رول اپ بنانے کی اجازت دیتا ہے۔ پھر ای وی ایم ان رول اپ میں سے پہلی بن جائے گی۔ ستم ظریفی یہ ہے کہ یہ بالکل ویسا ہی نتیجہ ہے۔ 2019-20 پر عملدرآمد کے ماحول کی تجویز ، اگرچہ SNARKs اسے حقیقت میں لاگو کرنا زیادہ ممکن بناتے ہیں۔
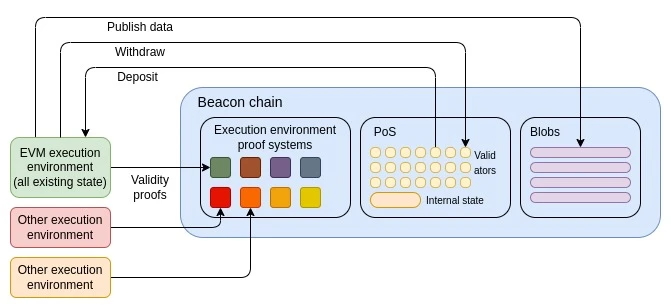
بیکن چین اور موجودہ ایتھرئم ایگزیکیوشن ماحول کے درمیان تعلق کو برقرار رکھنا ایک زیادہ معمولی طریقہ ہے، لیکن ای وی ایم کو اپنی جگہ پر تبدیل کرنا ہے۔ ہم RISC-V، قاہرہ، یا کسی اور VM کو نئے سرکاری Ethereum VM کے طور پر منتخب کر سکتے ہیں، اور پھر تمام EVM معاہدوں کو نئے VM کوڈ میں تبدیل کرنے پر مجبور کر سکتے ہیں جو اصل کوڈ کی منطق کی ترجمانی کرتا ہے (یا تو تالیف یا تشریح کے ذریعے)۔ نظریہ میں، یہ ہدف مجازی مشین کے ساتھ بھی کیا جا سکتا ہے جو EOF کا ایک ورژن ہے۔
یہ مضمون انٹرنیٹ سے لیا گیا ہے: Vitalik کا نیا مضمون: Ethereum کا ممکنہ مستقبل (V) - The Purge













