My XP
0
Login
اصل عنوان: گلو اور کاپروسیسر آرکیٹیکچرز
اصل مصنف: Vitalik Buterin، Ethereum کے بانی
اصل ترجمہ: ڈینگ ٹونگ، گولڈن فنانس
Justin Drake، Georgios Konstantopoulos، Andrej Karpathy، Michael Gao، Tarun Chitra، اور مختلف Flashbots کے تعاون کرنے والوں کا ان کے تاثرات اور تبصروں کے لیے خصوصی شکریہ۔
اگر آپ جدید دنیا میں کسی بھی وسائل پر مبنی کمپیوٹیشن کا بھی اعتدال سے تجزیہ کریں تو ایک چیز آپ کو بار بار ملے گی کہ کمپیوٹیشن کو دو حصوں میں تقسیم کیا جا سکتا ہے:
پیچیدہ لیکن کمپیوٹیشنل طور پر سستی کاروباری منطق کی نسبتاً کم مقدار
بہت زیادہ گہرا لیکن انتہائی منظم "مہنگا کام"۔
کمپیوٹنگ کی یہ دو شکلیں بہترین طریقے سے ہینڈل کی جاتی ہیں: سابقہ، جس کے فن تعمیرات کم کارگر ہو سکتے ہیں لیکن اسے بہت عام ہونا ضروری ہے۔ مؤخر الذکر، جس کے فن تعمیر کم عام ہوسکتے ہیں لیکن بہت موثر ہونے کی ضرورت ہے۔
سب سے پہلے، آئیے اس ماحول پر ایک نظر ڈالیں جس سے میں سب سے زیادہ واقف ہوں: ایتھریم ورچوئل مشین (EVM)۔ میں نے حالیہ Ethereum ٹرانزیکشن کا ایک گیتھ ڈیبگ ٹریس کیا ہے: ENS پر میرے بلاگ کے IPFS ہیش کو اپ ڈیٹ کرنا۔ اس لین دین میں مجموعی طور پر 46924 گیس استعمال کی گئی، جسے مندرجہ ذیل طور پر تقسیم کیا جا سکتا ہے:
بنیادی قیمت: 21,000
کال ڈیٹا: 1,556 EVM
عمل درآمد: 24,368 SLOAD
اوپکوڈ: 6,400 SSTORE
Opcode: 10, 100 LOG
اوپکوڈ: 2، 149
دیگر: 6,719
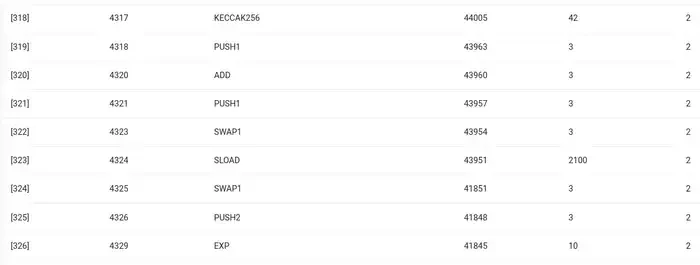
ENS ہیش اپ ڈیٹس کا EVM ٹریس۔ دوسرا سے آخری کالم گیس کی قیمت ہے۔
کہانی کا اخلاق یہ ہے: عمل درآمد کا بڑا حصہ (اگر آپ صرف EVM کو دیکھیں تو ~ 73%، ~85% اگر آپ بنیادی لاگت کے حصے کو کورنگ کمپیوٹ شامل کرتے ہیں) بہت کم تعداد میں ساختہ مہنگے آپریشنز پر مرکوز ہے: اسٹوریج پڑھتا ہے اور لکھنا، لاگنگ کرنا، اور خفیہ نگاری ادائیگی ہیشنگ کے لیے اضافی 272)۔ بقیہ عمل کاروباری منطق ہے: ریکارڈ کی ID نکالنے کے لیے کال ڈیٹا کے بٹس کو تبدیل کرنا میں سیٹ کرنے کی کوشش کر رہا ہوں اور ہیش میں اسے سیٹ کر رہا ہوں، وغیرہ۔ ٹوکن ٹرانسفر میں اس میں بیلنس کا اضافہ اور گھٹانا شامل ہو گا، مزید جدید ایپلی کیشنز میں اس میں لوپس وغیرہ شامل ہو سکتے ہیں۔
ای وی ایم میں، عمل درآمد کی ان دو شکلوں کو مختلف طریقے سے سنبھالا جاتا ہے۔ اعلیٰ سطحی کاروباری منطق ایک اعلیٰ سطحی زبان میں لکھی جاتی ہے، عام طور پر سولیڈیٹی، جو ای وی ایم کو مرتب کرتی ہے۔ مہنگا کام اب بھی EVM آپکوڈز (SLOAD، وغیرہ) کے ذریعے شروع کیا جاتا ہے، لیکن 99% سے زیادہ اصل کمپیوٹیشن براہ راست کلائنٹ کوڈ (یا یہاں تک کہ لائبریریوں) کے اندر لکھے گئے وقف شدہ ماڈیولز میں کی جاتی ہے۔
اس پیٹرن کے بارے میں ہماری سمجھ کو تقویت دینے کے لیے، آئیے اسے ایک اور تناظر میں دریافت کریں: ٹارچ کا استعمال کرتے ہوئے Python میں لکھا ہوا AI کوڈ۔

ٹرانسفارمر ماڈل کے ایک بلاک کا فارورڈ پاس
ہم یہاں کیا دیکھتے ہیں؟ ہم Python میں "بزنس لاجک" کی نسبتاً کم مقدار میں لکھا ہوا دیکھتے ہیں، جو انجام پانے والے آپریشنز کی ساخت کو بیان کرتا ہے۔ ایک حقیقی ایپلی کیشن میں، کاروباری منطق کی ایک اور قسم ہوگی جو تفصیلات کا تعین کرتی ہے جیسے کہ ان پٹ کیسے حاصل کیے جائیں اور آؤٹ پٹس پر کون سے آپریشن کیے جائیں۔ تاہم، اگر ہم ہر انفرادی آپریشن میں خود ڈرل کرتے ہیں (self.norm, torch.cat, +, *, self.attn، … کے اندر انفرادی مراحل)، تو ہم ویکٹرائزڈ کمپیوٹیشن دیکھتے ہیں: وہی آپریشن بڑی تعداد میں اقدار کی گنتی کرتا ہے۔ متوازی پہلی مثال کی طرح، حساب کا ایک چھوٹا سا حصہ کاروباری منطق کے لیے استعمال کیا جاتا ہے، اور کمپیوٹیشن کا زیادہ تر حصہ بڑے ساختی میٹرکس اور ویکٹر آپریشنز کو انجام دینے کے لیے استعمال کیا جاتا ہے - درحقیقت، ان میں سے زیادہ تر صرف میٹرکس ضربیں ہیں۔
بالکل اسی طرح جیسے ای وی ایم کی مثال میں، یہ دو قسم کے کام دو مختلف طریقوں سے سنبھالے جاتے ہیں۔ ہائی لیول بزنس لاجک کوڈ Python میں لکھا گیا ہے، جو کہ ایک انتہائی عام اور لچکدار زبان ہے، لیکن یہ بہت سست بھی ہے، اور ہم صرف اس ناکارہ کو قبول کرتے ہیں کیونکہ اس میں کل کمپیوٹیشنل لاگت کا صرف ایک چھوٹا حصہ شامل ہوتا ہے۔ ایک ہی وقت میں، شدید آپریشنز انتہائی بہتر بنائے گئے کوڈ میں لکھے جاتے ہیں، عام طور پر CUDA کوڈ جو GPUs پر چلتا ہے۔ تیزی سے، ہم یہاں تک کہ ASICs پر LLM کا نتیجہ دیکھنا شروع کر رہے ہیں۔
جدید پروگرام قابل خفیہ نگاری، جیسے SNARKs، دوبارہ دو سطحوں پر ایک ہی طرز کی پیروی کرتی ہے۔ سب سے پہلے، کہاوت کو ایک اعلیٰ سطحی زبان میں لکھا جا سکتا ہے جہاں اوپر دی گئی AI مثال کی طرح ہیوی لفٹنگ ویکٹرائزڈ آپریشنز کے ساتھ کی جاتی ہے۔ یہاں میرا سرکلر STARK کوڈ اس کو ظاہر کرتا ہے۔ دوسرا، خود خفیہ نگاری کے اندر عمل میں آنے والے پروگراموں کو اس طرح سے لکھا جا سکتا ہے جو عام کاروباری منطق اور انتہائی ساختہ مہنگے کام کے درمیان تقسیم ہو۔
یہ سمجھنے کے لیے کہ یہ کیسے کام کرتا ہے، ہم STARK ثبوتوں میں سے ایک تازہ ترین رجحان کو دیکھ سکتے ہیں۔ عام اور استعمال میں آسان ہونے کے لیے، ٹیمیں بڑے پیمانے پر اپنائی جانے والی کم سے کم ورچوئل مشینوں، جیسے RISC-V کے لیے تیزی سے STARK provers بنا رہی ہیں۔ کوئی بھی پروگرام جس کو اس کے عمل کو ثابت کرنے کی ضرورت ہے اسے RISC-V میں مرتب کیا جا سکتا ہے، اور پھر prover اس کوڈ کے RISC-V پر عمل درآمد کو ثابت کر سکتا ہے۔
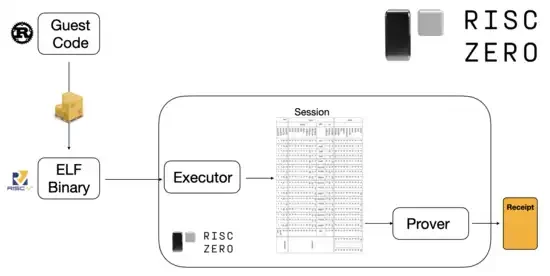
RiscZero دستاویزات سے خاکہ
یہ بہت آسان ہے: اس کا مطلب ہے کہ ہمیں صرف ایک بار ثبوت کی منطق لکھنی ہے، اور اس کے بعد سے کسی بھی پروگرام کو جس کے ثبوت کی ضرورت ہے، کسی بھی روایتی پروگرامنگ زبان میں لکھا جا سکتا ہے (مثال کے طور پر رسک زیرو Rust کو سپورٹ کرتا ہے)۔ تاہم، ایک مسئلہ ہے: اس نقطہ نظر پر بہت زیادہ بوجھ پڑتا ہے۔ قابل پروگرام کرپٹو پہلے ہی بہت مہنگا ہے۔ RISC-V ترجمان میں چلانے والے کوڈ کا اوور ہیڈ شامل کرنا بہت زیادہ ہے۔ لہذا، ڈویلپرز ایک چال کے ساتھ آئے: مخصوص مہنگے آپریشنز کی شناخت کریں جو زیادہ تر کمپیوٹیشن (عام طور پر ہیشنگ اور سائننگ) کو بناتے ہیں، اور پھر ان آپریشنز کو بہت موثر طریقے سے ثابت کرنے کے لیے خصوصی ماڈیولز بنائیں۔ اس کے بعد آپ صرف غیر موثر لیکن عام RISC-V پروف سسٹم کو موثر لیکن خصوصی پروف سسٹم کے ساتھ جوڑ دیتے ہیں، اور آپ کو دونوں جہانوں کا بہترین حاصل ہوتا ہے۔
ZK-SNARKs سے آگے قابل پروگرام کرپٹوگرافی، جیسے ملٹی پارٹی کمپیوٹیشن (MPC) اور مکمل طور پر ہومومورفک انکرپشن (FHE)، کو اسی طرح کے طریقوں کا استعمال کرتے ہوئے بہتر بنایا جا سکتا ہے۔
جدید کمپیوٹنگ تیزی سے اس کی پیروی کرتی ہے جسے میں گلو اور کاپروسیسر آرکیٹیکچر کہتا ہوں: آپ کے پاس کچھ مرکزی گلو جز ہے، جو کہ اعلی عمومی لیکن کم کارکردگی ہے، جو کہ ایک یا زیادہ کاپروسیسر کے اجزاء کے درمیان ڈیٹا منتقل کرنے کے لیے ذمہ دار ہے، جو کم عمومی لیکن اعلی کارکردگی کے حامل ہیں۔

یہ ایک سادگی ہے: عملی طور پر، کارکردگی اور عمومیت کے درمیان تجارت کا وکر تقریباً ہمیشہ دو سے زیادہ سطحوں پر ہوتا ہے۔ GPUs اور دیگر چپس، جنہیں صنعت میں اکثر "coprocessors" کہا جاتا ہے، CPUs سے کم عام ہیں، لیکن ASICs سے زیادہ عام ہیں۔ تخصیص کی ڈگری کے لحاظ سے تجارتی تعلقات پیچیدہ ہیں، اور یہ پیشین گوئیوں اور ادراک پر منحصر ہے کہ الگورتھم کے کون سے حصے پانچ سالوں میں ایک جیسے رہیں گے، اور کون سے حصے چھ ماہ میں بدل جائیں گے۔ ہم اکثر ZK پروف فن تعمیر میں اسی طرح کی متعدد سطحوں کی مہارت دیکھتے ہیں۔ لیکن ایک وسیع ذہنی ماڈل کے لیے، دو سطحوں پر غور کرنا کافی ہے۔ کمپیوٹنگ کے بہت سے شعبوں میں اسی طرح کے حالات ہیں:
مندرجہ بالا مثالوں سے، یہ یقینی طور پر ایک قدرتی قانون کی طرح لگتا ہے کہ کمپیوٹنگ کو اس طرح تقسیم کیا جا سکتا ہے. درحقیقت، آپ کو کمپیوٹنگ کی مہارت کی مثالیں مل سکتی ہیں جو دہائیوں پرانی ہیں۔ تاہم، میرے خیال میں یہ علیحدگی بڑھتی جا رہی ہے۔ میرے خیال میں اس کی وجوہات ہیں:
ہم حال ہی میں CPU گھڑی کی رفتار میں اضافے کی حد تک پہنچ چکے ہیں، اس لیے مزید فوائد صرف متوازی کے ذریعے حاصل کیے جا سکتے ہیں۔ تاہم، متوازی کے بارے میں استدلال کرنا مشکل ہے، اس لیے ڈویلپرز کے لیے یہ اکثر زیادہ عملی ہوتا ہے کہ وہ ترتیب وار اس کے بارے میں استدلال جاری رکھیں اور متوازی کو پس منظر میں ہونے دیں، جو مخصوص آپریشنز کے لیے بنائے گئے وقف شدہ ماڈیولز میں لپٹے ہوئے ہیں۔
حساب کتاب حال ہی میں اتنی تیز ہو گئی ہے کہ کاروباری منطق کی کمپیوٹیشنل لاگت واقعی نہ ہونے کے برابر ہو گئی ہے۔ اس دنیا میں، VM کو بہتر بنانا بھی سمجھ میں آتا ہے جہاں کاروباری منطق کمپیوٹیشنل کارکردگی کے علاوہ دیگر اہداف کے لیے چلتی ہے: ڈویلپر کی دوستی، واقفیت، سلامتی، اور اسی طرح کے دوسرے اہداف۔ اس دوران، وقف شدہ کاپروسیسر ماڈیولز کو کارکردگی کے لیے ڈیزائن کیا جانا جاری رکھا جا سکتا ہے اور ان کے نسبتاً آسان انٹرفیس سے بائنڈر تک اپنی حفاظت اور ڈویلپر دوستی حاصل کر سکتے ہیں۔
یہ تیزی سے واضح ہوتا جا رہا ہے کہ سب سے اہم مہنگے آپریشن کیا ہیں۔ یہ کرپٹوگرافی میں سب سے زیادہ واضح ہے، جہاں خاص قسم کے مہنگے آپریشنز استعمال کیے جانے کا زیادہ امکان ہوتا ہے: ماڈیولر آپریشنز، بیضوی وکر لکیری امتزاج (عرف ملٹی اسکیلر ضرب)، فاسٹ فوئیر ٹرانسفارمز، وغیرہ۔ یہ AI میں بھی تیزی سے واضح ہوتا جا رہا ہے، جہاں دو دہائیوں سے زیادہ عرصے سے زیادہ تر حساب کتاب زیادہ تر میٹرکس ضرب (حالانکہ درستگی کی مختلف سطحوں پر) رہا ہے۔ اسی طرح کے رجحانات دوسرے شعبوں میں ابھر رہے ہیں۔ 20 سال پہلے کے مقابلے (کمپیوٹ-انٹینسیو) کمپیوٹیشنز میں بہت کم نامعلوم نامعلوم ہیں۔
ایک اہم نکتہ یہ ہے کہ گلو کو ایک اچھا گلو بننے کے لیے بہتر بنایا جانا چاہیے، اور کاپروسیسر کو ایک اچھا کاپروسیسر بننے کے لیے بہتر بنایا جانا چاہیے۔ ہم اس کے مضمرات کو چند اہم شعبوں میں تلاش کر سکتے ہیں۔
بلاکچین ورچوئل مشینوں (جیسے ای وی ایم) کو موثر ہونے کی ضرورت نہیں ہے، صرف واقف ہیں۔ صحیح کوپروسیسر (عرف پری کمپائلیشن) کے اضافے کے ساتھ، ایک غیر موثر VM میں کمپیوٹیشن درحقیقت اتنی ہی کارآمد ہو سکتی ہے جتنی کہ ایک مقامی، موثر VM میں کمپیوٹیشن۔ مثال کے طور پر، EVMs 256-bit رجسٹروں سے خرچ ہونے والا اوور ہیڈ نسبتاً کم ہے، جب کہ EVMs سے واقفیت اور موجودہ ڈویلپر ماحولیاتی نظام کے فوائد بڑے اور دیرپا ہیں۔ ای وی ایم کو بہتر بنانے والی ترقیاتی ٹیموں نے یہاں تک پایا ہے کہ ہم آہنگی کی کمی عام طور پر اسکیل ایبلٹی میں بڑی رکاوٹ نہیں ہے۔
ای وی ایم کو بہتر بنانے کے بہترین طریقے صرف یہ ہو سکتے ہیں کہ (i) بہتر پہلے سے مرتب شدہ یا خصوصی آپ کوڈز شامل کرنا، جیسے EVM-MAX اور SIMD کا کچھ امتزاج معقول ہو سکتا ہے، اور (ii) اسٹوریج کی ترتیب کو بہتر بنانا، جیسے Verkle کے درختوں میں تبدیلی لاگت کو بہت کم کرتی ہے۔ ضمنی اثر کے طور پر ایک دوسرے سے متصل اسٹوریج سلاٹس تک رسائی حاصل کرنے کا۔
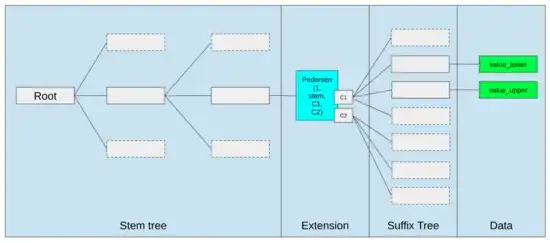
Ethereum کے Verkle Tree کی تجویز میں سٹوریج کی اصلاح ملحقہ سٹوریج کیز کو ایک ساتھ رکھتی ہے اور اس کی عکاسی کرنے کے لیے گیس کے اخراجات کو ایڈجسٹ کرتی ہے۔ اس طرح کی اصلاحیں، بہتر پری کمپائلز کے ساتھ مل کر، خود EVM کو درست کرنے سے زیادہ اہم ہو سکتی ہیں۔
ہارڈ ویئر کی سطح پر جدید کمپیوٹنگ کی سیکیورٹی کو بہتر بنانے میں ایک بڑا چیلنج اس کی حد سے زیادہ پیچیدہ اور ملکیتی نوعیت ہے: چپس کو موثر بنانے کے لیے ڈیزائن کیا گیا ہے، جس کے لیے ملکیتی اصلاح کی ضرورت ہے۔ پچھلے دروازوں کو چھپانا آسان ہے، اور سائیڈ چینل کی کمزوریاں مسلسل دریافت کی جا رہی ہیں۔
مزید کھلے، زیادہ محفوظ متبادل کے لیے کوششیں متعدد زاویوں سے جاری ہیں۔ کچھ کمپیوٹنگ تیزی سے قابل اعتماد عملدرآمد کے ماحول میں کی جاتی ہے، بشمول صارفین کے فون پر، جس نے صارفین کے لیے سیکیورٹی کو بہتر بنایا ہے۔ مزید اوپن سورس کنزیومر ہارڈویئر کے لیے پش جاری ہے، کچھ حالیہ جیتوں کے ساتھ، جیسے کہ اوبنٹو چلانے والے RISC-V لیپ ٹاپس۔

RISC-V لیپ ٹاپ Debian چلا رہا ہے۔
تاہم، کارکردگی ایک مسئلہ رہتا ہے. مذکورہ بالا مضمون کے مصنف لکھتے ہیں:
RISC-V جیسے نئے اوپن سورس چپ ڈیزائن ممکنہ طور پر پروسیسر ٹکنالوجی کا مقابلہ نہیں کر سکتے جو کئی دہائیوں میں آس پاس ہے اور بہتر ہے۔ ترقی ہمیشہ کہیں سے شروع کرنی ہوتی ہے۔
FPGA پر RISC-V کمپیوٹر بنانے کے اس ڈیزائن کی طرح مزید بے وقوفانہ خیالات، اس سے بھی زیادہ اوور ہیڈ کا سامنا کرتے ہیں۔ لیکن کیا ہوگا اگر گلو اور کوپروسیسر فن تعمیر کا مطلب یہ ہے کہ اس اوور ہیڈ سے کوئی فرق نہیں پڑتا؟ کیا ہوگا اگر ہم یہ قبول کرلیں کہ کھلی اور محفوظ چپس ملکیتی چپس کے مقابلے سست ہوں گی، یہاں تک کہ اگر ضروری ہو تو قیاس آرائی پر عمل درآمد اور برانچ کی پیشن گوئی جیسی عام اصلاح کو بھی ترک کردیں، لیکن ASIC ماڈیولز (اگر ضروری ہو تو ملکیتی) شامل کرکے اس کو پورا کرنے کی کوشش کریں جو حساب کی مخصوص اقسام جو سب سے زیادہ گہری ہیں؟ حساس کمپیوٹیشن "مین چپ" میں کیے جا سکتے ہیں، جو سیکورٹی، اوپن سورس ڈیزائن، اور سائیڈ چینل ریزسٹنس کے لیے بہتر بنائے جائیں گے۔ ASIC ماڈیولز میں زیادہ گہرائی سے کمپیوٹنگ (مثلاً ZK ثبوت، AI) کی جائیں گی، جس سے انجام دی جانے والی کمپیوٹیشنز کے بارے میں کم معلومات ہوں گی (ممکنہ طور پر، کرپٹوگرافک بلائنڈنگ کے ذریعے، یا کچھ معاملات میں صفر کی معلومات بھی)۔
ایک اور اہم نکتہ یہ ہے کہ یہ سب خفیہ نگاری، اور خاص طور پر قابل پروگرام کرپٹوگرافی، مرکزی دھارے میں جانے کے بارے میں بہت پر امید ہے۔ ہم نے پہلے ہی SNARK، MPC، اور دیگر ترتیبات میں کچھ مخصوص انتہائی ساختی کمپیوٹیشنز کے انتہائی بہتر نفاذ کو دیکھا ہے: کچھ ہیش فنکشنز براہ راست کمپیوٹیشن چلانے سے چند سو گنا زیادہ مہنگے ہوتے ہیں، اور AI (بنیادی طور پر میٹرکس ضرب) کم سر کے ساتھ ساتھ. مزید بہتری جیسے GKR اس کو مزید کم کر سکتی ہے۔ مکمل طور پر عام VM پر عمل درآمد، خاص طور پر جب RISC-V ترجمان میں عمل میں لایا جاتا ہے، ممکنہ طور پر تقریباً دس ہزار گنا زیادہ ہوتا رہے گا، لیکن اس مقالے میں بیان کردہ وجوہات کی بناء پر اس سے کوئی فرق نہیں پڑتا: جب تک کہ اس کے انتہائی گہرے حصے گنتی کو الگ سے موثر، خصوصی تکنیکوں کا استعمال کرتے ہوئے سنبھالا جاتا ہے، کل اوور ہیڈ قابل انتظام ہے۔
میٹرکس ضرب کے لیے وقف شدہ MPC کا آسان خاکہ، AI ماڈل کے تخمینہ کا سب سے بڑا جزو۔ مزید تفصیلات کے لیے یہ مضمون دیکھیں، بشمول ماڈلز اور ان پٹس کو نجی کیسے رکھا جاتا ہے۔
اس خیال کی ایک رعایت کہ گلو پرت کو صرف واقف ہونے کی ضرورت ہے، موثر نہیں، تاخیر ہے، اور کچھ حد تک ڈیٹا بینڈوتھ۔ اگر کمپیوٹیشن میں ایک ہی ڈیٹا پر درجنوں بار بھاری کارروائیاں شامل ہوتی ہیں (جیسا کہ کرپٹوگرافی اور اے آئی میں)، تو پھر ناکارہ گلو لیئر کی وجہ سے کوئی بھی تاخیر رن ٹائم میں ایک بڑی رکاوٹ بن سکتی ہے۔ لہذا، گلو پرت میں کارکردگی کی ضروریات بھی ہیں، حالانکہ یہ زیادہ مخصوص ہیں۔
مجموعی طور پر، میرے خیال میں اوپر بیان کردہ رجحانات متعدد نقطہ نظر سے بہت مثبت پیش رفت ہیں۔ سب سے پہلے، ڈویلپر کے موافق رہتے ہوئے کمپیوٹیشنل کارکردگی کو زیادہ سے زیادہ کرنے کے لیے یہ ایک معقول طریقہ ہے، اور دونوں میں سے زیادہ حاصل کرنے کے قابل ہونا ہر ایک کے لیے اچھا ہے۔ خاص طور پر، کارکردگی کو بہتر بنانے کے لیے کلائنٹ کی جانب سے تخصص کو فعال کرنے سے، یہ صارف کے ہارڈویئر پر مقامی طور پر حساس اور کارکردگی کا مطالبہ کرنے والے کمپیوٹیشنز (مثلاً ZK ثبوت، LLM استدلال) چلانے کی ہماری صلاحیت کو بہتر بناتا ہے۔ دوسرا، یہ اس بات کو یقینی بنانے کے لیے مواقع کی ایک بڑی کھڑکی پیدا کرتا ہے کہ کارکردگی کا حصول دیگر اقدار سے سمجھوتہ نہیں کرتا ہے، خاص طور پر سیکورٹی، کشادگی، اور سادگی: سائڈ چینل سیکیورٹی اور کمپیوٹر ہارڈویئر میں کشادگی، ZK-SNARKs میں سرکٹ کی پیچیدگی میں کمی، اور ورچوئل مشینوں میں کم پیچیدگی۔ تاریخی طور پر، کارکردگی کے حصول نے ان دیگر عوامل کو پیچھے چھوڑ دیا ہے۔ گلو اور کوپروسیسر آرکیٹیکچرز کے ساتھ، اب اس کی ضرورت نہیں ہے۔ مشین کا ایک حصہ کارکردگی کے لیے بہتر بناتا ہے، اور دوسرا حصہ عمومیت اور دیگر اقدار کے لیے بہتر بناتا ہے، اور دونوں مل کر کام کرتے ہیں۔
یہ رجحان کرپٹوگرافی کے لیے بھی بہت اچھا ہے، کیونکہ کرپٹوگرافی خود مہنگی ساختی کمپیوٹیشن کی ایک بہترین مثال ہے، اور یہ رجحان اسے تیز کرتا ہے۔ یہ بہتر سیکورٹی کے لیے ایک اور موقع کا اضافہ کرتا ہے۔ بلاک چین کی دنیا میں، بہتر سیکورٹی بھی ممکن ہے: ہم ورچوئل مشین کو بہتر بنانے کے بارے میں کم فکر کر سکتے ہیں اور پہلے سے کمپائلیشن اور دیگر خصوصیات کو بہتر بنانے پر زیادہ توجہ مرکوز کر سکتے ہیں جو ورچوئل مشین کے ساتھ ساتھ موجود ہیں۔
تیسرا، یہ رجحان چھوٹے، نئے کھلاڑیوں کے لیے شرکت کے مواقع فراہم کرتا ہے۔ اگر حساب کم یک سنگی اور زیادہ ماڈیولر ہو جاتا ہے، تو یہ داخلے کی رکاوٹ کو بہت کم کر دیتا ہے۔ یہاں تک کہ ASICs جو ایک قسم کے حساب کا استعمال کرتے ہیں ان میں بھی فرق کرنے کی صلاحیت ہوتی ہے۔ یہ ZK ثبوتوں اور ای وی ایم کی اصلاح کے شعبے میں بھی درست ہے۔ کوڈ لکھنا آسان اور قابل رسائی ہو جاتا ہے جس میں قریب ترین کارکردگی کا مظاہرہ ہوتا ہے۔ ایسے کوڈ کا آڈٹ اور باضابطہ تصدیق کرنا آسان اور قابل رسائی ہو جاتا ہے۔ آخر میں، چونکہ حساب کے یہ بہت مختلف شعبے کچھ عام نمونوں پر اکٹھے ہو رہے ہیں، اس لیے ان کے درمیان تعاون اور سیکھنے کی زیادہ گنجائش ہے۔
یہ مضمون انٹرنیٹ سے لیا گیا ہے: Vitaliks کا نیا مضمون: Glue and co-processor architecture، کارکردگی اور سیکیورٹی کو بہتر بنانے کے لیے ایک نیا خیال
متعلقہ: تکنیکی جدت یا ہائپ بیانیہ؟ فریکٹل بٹ کوائن کے ابتدائی ماحولیاتی نظام پر ایک نظر
اصل مصنف: shaofaye 123، Foresight News یونی سیٹ کی ٹیم نے ایک بار پھر کارروائی کی ہے۔ فریکٹل بٹ کوائن نے مارکیٹ میں تیزی پیدا کی ہے، اور ٹیسٹ نیٹ ورک پر والیٹ پتوں کی تعداد 10 ملین سے تجاوز کر گئی ہے۔ پیزا اور سیٹس ایک کے بعد ایک عروج پر ہیں۔ کیا یہ Bitcoin ماحولیاتی نظام یا BSV 2.0 کا اگلا دھماکہ نقطہ ہے؟ FUD اور FOMO ایک ساتھ رہتے ہیں، اور مین نیٹ ریلیز ہونے والا ہے۔ یہ مضمون آپ کو فریکٹل بٹ کوائن کی ابتدائی ماحولیات کے جائزہ پر لے جائے گا۔ فریکٹل بٹ کوائن کے بارے میں فریکٹل بٹ کوائن ایک اور بٹ کوائن توسیعی حل ہے جسے UniSat ٹیم نے تیار کیا ہے۔ BTC کور کوڈ کا استعمال کرتے ہوئے، یہ موجودہ Bitcoin ایکو سسٹم کے ساتھ مکمل طور پر ہم آہنگ ہونے کے ساتھ ساتھ، ٹرانزیکشن پروسیسنگ کی صلاحیتوں اور رفتار کو بہتر بنانے کے لیے مین چین پر ایک لامحدود توسیعی تہہ کو اختراع کرتا ہے۔ اس کے…













