Task
Ranking
已登录
Bee登录
Twitter 授权
TG 授权
Discord 授权
去签到
下一页
关闭
获取登录状态
My XP
0
Original author: Vitalik
اصل ترجمہ: ڈینگ ٹونگ، گولڈن فنانس
I sit here writing this on the last day of the Kenya Ethereum Developer Interop, and we’ve made a lot of progress implementing and ironing out the technical details of important upcoming Ethereum improvements, most notably PeerDAS, Verkle tree transition, and a decentralized approach to storing history in the context of EIP 4444. From my own perspective, the pace of Ethereum development and our ability to deliver large and important features that can significantly improve the experience for both node operators and (L1 and L2) users continues to grow.

Ethereum client teams work together to deliver Pectra devnet
Given the increasing capabilities of the technology, an important question to ask is: are we heading towards the right goal? A recent series of disgruntled tweets from long-time Geth core developer Peter Szilagyi prompted us to ponder this question:
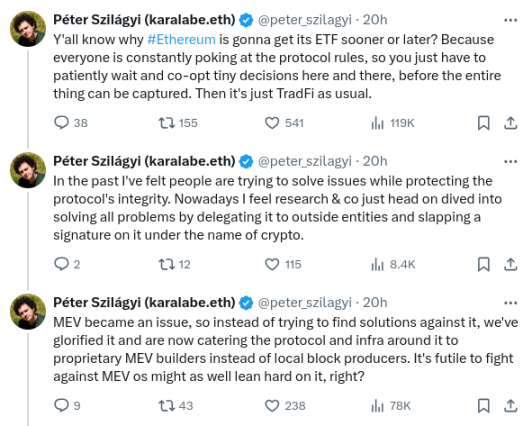
These concerns are all valid. They are concerns expressed by many in the Ethereum community. I have personally worried about these issues on many occasions. However, I also do not think the situation is as hopeless as Peter’s tweet suggests. On the contrary, many of the issues are already being addressed through ongoing protocol features, while many others can be addressed through very realistic adjustments to the current roadmap.
To understand what this means in practice, lets go through the three examples Peter provided. These issues are common concerns for many community members, and addressing them is important.
In the past, Ethereum blocks were created by miners, who used a relatively simple algorithm to create blocks. Users send transactions to a public p2p network, often called a mempool (or txpool). Miners listen to the memory pool, accept valid transactions and pay fees. They include transactions that can be carried out, and if there is not enough space, they are prioritized in order of highest fee first.
It’s a very simple system, and it’s friendly to decentralization: as a miner, you just run the default software, and you get the same level of fee income from a block as you would from a highly professional mining farm. However, around 2020, people started taking advantage of what’s called Miner Extractable Value (MEV): income that’s only available by executing complex strategies that understand the activities happening inside various DeFi protocols.
For example, consider a decentralized exchange like Uniswap. Suppose at time T, the USD/ETH rate on centralized exchanges and Uniswap is $3000. At time T+11, the USD/ETH rate on centralized exchanges rises to $3005. But Ethereum doesnt have the next block yet. By time T+12, it does. Whoever created the block, their first transaction could be a series of Uniswap buys, buying all the available ETH on Uniswap for prices ranging from $3000 to $3004. This is extra income, called MEV. Applications other than DEXs have similar problems. The Flash Boys 2.0 paper published in 2019 covers this in detail.

The chart in the Flash Boys 2.0 paper shows the amount of revenue that can be obtained using the various methods mentioned above.
The problem is that this defeats the very reason why mining (or block proposals after 2022) can be “fair”: now, large players with better ability to optimize such extraction algorithms can get better rewards in each block.
Since then, there has been an ongoing debate between two strategies, which I refer to as MEV minimization and MEV segregation. MEV minimization comes in two forms: (i) actively developing MEV-free alternatives to Uniswap (e.g., Cowswap), and (ii) building in-protocol techniques, such as encrypted mempools, that reduce the information available to block producers, and thus the revenue they can earn. In particular, encrypted mempools prevent strategies such as sandwich attacks, which place transactions before and after a user’s transactions in order to economically exploit them (“front-running”).
MEV Segregation works by accepting MEV but attempting to limit its impact on staking centralization by splitting the market into two types of participants: validators are responsible for attesting and proposing blocks, but the task of selecting block content is passed through an auction protocol. Individual stakers now no longer need to worry about optimizing DeFi arbitrage themselves; they simply join the auction protocol and accept the highest bid. This is called Proposer/Builder Separation (PBS). This approach has precedent in other industries: one of the main reasons restaurants have been able to remain so decentralized is that they tend to rely on fairly centralized suppliers for various operations that do have huge economies of scale. So far, PBS has been quite successful in ensuring that small and large validators are on a level playing field, at least as far as MEV is concerned. However, it brings another problem: the task of selecting which transactions to include becomes more centralized.
My take on this has always been that MEV minimization is good and we should pursue it (I personally use Cowswap a lot!) – while there are many challenges with crypto mempools, MEV minimization may not be enough; MEV is not going to drop to zero, or even close to zero. Therefore, we need some kind of MEV isolation as well. This creates an interesting task: how do we make the MEV isolation box as small as possible? How do we give builders as little power as possible while still allowing them to absorb the role of optimizing arbitrage and other forms of MEV collection?
If builders have the power to exclude transactions from blocks entirely, attacks can easily occur. Lets say you have a collateralized debt position (CDP) in a defi protocol, backed by an asset that is rapidly falling in price. You want to increase your collateral or exit your CDP. A malicious builder could try to collude to refuse to include your transaction, thereby delaying it until the price drops enough to force liquidate your CDP. If this happens, you will have to pay a large penalty, and the builder will get a large portion. So how do we prevent builders from excluding transactions and completing such attacks?
This is where include lists come in.
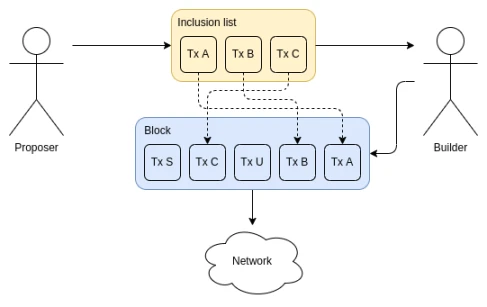
Source: ethresear.ch
Inclusion lists allow block proposers (i.e. stakeholders) to choose which transactions are required to go into a block. Builders can still reorder transactions or insert their own, but they must include the proposers transaction. Eventually, inclusion lists were modified to constrain the next block instead of the current block. In either case, they take away the ability of builders to push transactions out of a block entirely.
MEV is a complex problem; even the description above leaves out many important nuances. As it is said, “You may not be looking for MEV, but MEV is looking for you.” Ethereum researchers have been very consistent in their goal of “minimizing the isolated box”, minimizing the harm that builders can cause (e.g., by excluding or delaying transactions as a way to attack a particular application).
That said, I do think we can go further. Historically, inclusion lists have often been considered a “special case feature”: normally, you don’t think about them, but they give you a “second way out” in case a malicious builder starts doing crazy things. This attitude is reflected in current design decisions: in the current EIP, the gas limit for inclusion lists is around 2.1M. But we can make a philosophical shift in how we think about inclusion lists: think of the inclusion list as a block, and the role of the builder as a helper function that adds some transactions to collect MEV. What if the builder had a 2.1M gas limit?
I think the idea in this direction — really pushing the quarantine box to be as small as possible — is very interesting, and I am in favor of moving in this direction. This is a shift from the 2021 era philosophy: in the 2021 era philosophy, we are more enthusiastic about the idea that now that we have builders, we can overload their functionality and let them serve users in more complex ways, e.g. by supporting ERC-4337 fee markets. In this new philosophy, the transaction verification part of ERC-4337 must be incorporated into the protocol. Fortunately, the ERC-4337 team has become increasingly enthusiastic about this direction.
Summary: MEV thinking has moved back in the direction of empowering block producers, including giving block producers the power to directly ensure user transaction inclusion. Account abstraction proposals have moved back in the direction of removing reliance on centralized relayers and even bundlers. However, there is a good argument that we haven’t gone far enough, and I think pressure to push development further in this direction is very welcome.
Today, individual stakers account for a relatively small percentage of all Ethereum staked, and most staking is done by a variety of providers — some centralized operators and other DAOs such as Lido and RocketPool.
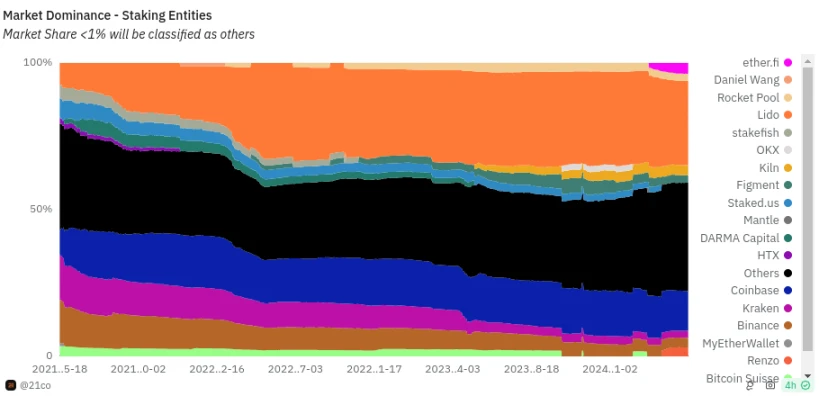
I did my own research — various polls, surveys, in-person conversations, asking the question “Why are you — specifically you — not staking solo today?” For me, a strong solo staking ecosystem is by far my preferred outcome for Ethereum staking, and one of the best things about Ethereum is that we actually try to support a strong solo staking ecosystem instead of just giving in to delegation. However, we are still far from that outcome. Across my polls and surveys, there are a few consistent trends:
The vast majority of those who do not stake solo cite the 32 ETH minimum as their primary reason.
Of those who cited other reasons, the biggest was the technical challenges of running and maintaining a validator node.
The loss of immediate availability of ETH, the security risks of “hot” private keys, and the loss of the ability to simultaneously participate in DeFi protocols are all significant but smaller issues.
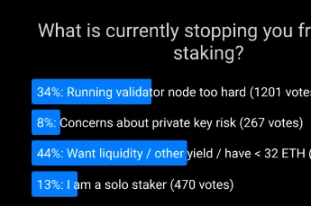
The Farcaster poll revealed the main reasons people don’t solo stake.
Staking research needs to address two key issues:
How do we address these concerns?
If most people still don’t want to stake individually despite having efficient solutions to most problems, then how do we keep the protocol stable and robust against attacks despite this?
Many ongoing research and development projects are aimed at addressing these issues:
Verkle trees coupled with EIP-4444 allow staked nodes to run with very low hard disk requirements. In addition, they allow staked nodes to sync almost instantly, greatly simplifying the setup process and operations such as switching from one implementation to another. They also make Ethereum light clients more feasible by reducing the data bandwidth required to provide proofs for each state access.
Research (such as these proposals) on ways to allow for larger validator sets (enabling smaller stake minimums) while reducing consensus node overhead. These ideas could be implemented as part of single-slot finality. Doing so would also make light clients more secure, as they would be able to verify the full set of signatures rather than relying on a sync committee).
Despite this growing history, ongoing Ethereum client optimizations continue to reduce the cost and difficulty of running a validator node.
Research into penalty caps could potentially alleviate concerns about private key risk and enable stakers to simultaneously stake their ETH in DeFi protocols if they so choose.
0x 01 Withdrawal voucher allows stakers to set their ETH address as a withdrawal address. This makes decentralized staking pools more feasible, giving them an advantage over centralized staking pools.
However, we can still do more. It is theoretically possible to allow validators to withdraw faster: Casper FFG would still be safe even if the validator set changes by a few percentage points every time finalization occurs (i.e. once per epoch). So we can significantly shorten the cycle if we try hard enough. If we want to significantly reduce the minimum deposit size, we can make hard decisions and trade off in other directions. For example, if we increase the finalization time by 4x, then the minimum deposit size will decrease by 4x. Single-slot finality will later solve this problem by moving beyond the every staker participates in every epoch model entirely.
Another important part of the whole question is the economics of staking. A key question is: do we want staking to be a relatively niche activity, or do we want everyone or almost everyone to stake all of their ETH? If everyone is staking, then what responsibilities do we want everyone to have? If people end up simply delegating responsibilities because they are lazy, then it can end up being centralization. There are important and deep philosophical questions here. The wrong answer could lead Ethereum down a path of centralization and recreate the traditional financial system with extra steps; the right answer could create a shining example of a successful ecosystem with a broad and diverse range of independent stakers and highly decentralized staking pools. These questions go to the core economics and values of Ethereum, so we need more diverse participation.
Many of the key issues surrounding Ethereum’s decentralization ultimately come down to a question that has defined a decade of blockchain: How conveniently do we want to run nodes, and how can we make it happen?
Today, running a node is hard. Most people don’t do it. On the laptop I’m using to write this post, I have a reth node that takes up 2.1 TB — already the result of heroic software engineering and optimization. I need to buy an additional 4 TB hard drive to put in my laptop to store this node. We all want running a node to be easier. In my ideal world, people will be able to run a node on their phones.
As I wrote above, EIP-4444 and Verkle trees are two key technologies that get us closer to this ideal. If both are implemented, the hardware requirements for a node could eventually be reduced to less than a hundred gigabytes, and could be close to zero if we completely eliminate the history storage responsibility (perhaps only for non-staking nodes). Type 1 ZK-EVM would eliminate the need to run EVM computations yourself, as you can simply verify proofs that the execution was correct. In my ideal world, we would have all of these technologies stacked together, and even Ethereum browser extension wallets (e.g. Metamask, Rabby) would have a built-in node to verify these proofs, do data availability sampling, and ensure the chain is correct.

The above vision is often referred to as The Verge.
This is all well known and understood, even by those who raise concerns about Ethereum node size. However, there is an important concern: if we remove the responsibility of maintaining state and providing proofs, isn’t this a centralization vector? Even if they can’t cheat by providing invalid data, isn’t it against the principles of Ethereum to rely too heavily on them?
A more recent version of this concern is the discomfort many have with EIP-4444: if regular Ethereum nodes no longer need to store old history, then who needs to? A common answer is: there are certainly enough large actors (e.g., block explorers, exchanges, Layer 2) who have an incentive to hold this data, and the Ethereum chain is small compared to the 100PB stored by the Wayback Machine. Therefore, the idea that any history can actually be lost is ridiculous.
However, this argument relies on a small number of large actors. In my taxonomy of trust models, this is a 1 in N assumption, but N is very small. This has its tail risks. One thing we could do is store old history in a peer-to-peer network, where each node only stores a small fraction of the data. Such a network would still have enough replication to ensure robustness: there would be thousands of copies of each piece of data, and in the future we could use erasure coding (in fact, by putting the history into EIP-4844-style blobs, which already have erasure coding built in) to further improve stability.

Blobs have erasure coding within and between blobs. The simplest way to provide ultra-stable storage for all of Ethereum’s history is likely to be to put beacons and execution blocks into blobs. Image source: codex.storage
For too long, this work has been on the back burner. The portal network exists, but it has not actually received the level of attention commensurate with its importance to Ethereum’s future. Fortunately, there is now momentum to put more resources into a minimal version of the portal focused on distributed storage and accessibility of history. We should build on this and work together to implement EIP-4444 as soon as possible, paired with a strong decentralized peer-to-peer network for storing and retrieving old history.
With state and ZK-EVM, this distributed approach is harder. To build an efficient block, you just need to have the full state. In this case, I personally prefer a pragmatic approach: we define and stick to some level of hardware requirements needed to have a node that does everything, which is higher than the (ideally ever-decreasing) cost chain of simple validating nodes, but still low enough that hobbyists can afford it. We rely on the 1 in N assumption, ensuring that N is fairly large.
ZK-EVM proofs are probably the trickiest part, and a live ZK-EVM prover will probably require more powerful hardware than an archive node, even with advances like Binius, and worst-case bounds on multidimensional gas. We could work on a distributed proof network where each node takes on the responsibility of proving, say, one percent of block execution, and then the block producer only needs to aggregate a hundred proofs at the end. Proof aggregation trees could help more. But if that doesnt work well, then another compromise would be to allow the hardware requirements for proofs to get higher, but ensure that the node that does everything can directly verify Ethereum blocks (without proving) fast enough to effectively participate in the network.
I think the Ethereum mindset in 2021 is really used to shifting responsibility to a few large players, as long as there is some market mechanism or zero-knowledge proof system to force the centralized players to act honestly. Such systems usually work well in the average case, but fail catastrophically in the worst case.

At the same time, I think it’s important to emphasize that current Ethereum protocol proposals have moved significantly away from this model and are taking the need for a truly decentralized network much more seriously. Ideas around stateless nodes, MEV mitigation, single-slot finality, and similar concepts have gone further in this direction. A year ago, the idea of data availability sampling via relays as semi-centralized nodes was seriously considered. This year, we’ve moved away from the need to do any of that, and PeerDAS has made surprisingly strong progress.
However, there is a lot we can do to go further in this direction on all three of the central issues I talked about above, as well as many other important issues. Helios has made great progress in providing a “true light client” for Ethereum. Now we need to include it by default in Ethereum wallets, and have RPC providers provide proofs and their results so that they can be verified, and extend light client technology to layer 2 protocols. If Ethereum scales via a Rollup-centric roadmap, layer 2 needs to get the same security and decentralization guarantees as layer 1. There are many other things we should take more seriously in a Rollup-centric world; decentralized and efficient cross-L2 bridges are one of many examples. Many dapps get their logs through centralized protocols because Ethereum’s native log scanning has become too slow. We can improve this with dedicated decentralized sub-protocols; here is one suggestion I have on how to do this.
There are a nearly infinite number of blockchain projects targeting the “we can be super fast, we’ll think about decentralization later” market. I don’t think Ethereum should join the party. Ethereum L1 can and certainly should be a strong base layer for layer 2 projects that take a hyperscale approach, using Ethereum as a backbone for decentralization and security. Even a layer 2-centric approach requires that layer 1 itself be scalable enough to handle a large number of operations. But we should deeply respect the features that make Ethereum unique, and continue to work to maintain and improve those features as Ethereum scales.
This article is sourced from the internet: Vitalik: Short-term and mid-term plans to improve Ethereum’s permissionlessness and decentralization
Original author | @DistilledCrypto Compilation | Golem Since the popularity of large language models such as ChatGPT, running similar machine learning models on decentralized networks has become one of the main narratives of blockchain + AI. However, we cannot trust decentralized networks to use specific ML models for reasoning like we trust reputable companies like OpenAI, so we need to verify it. Considering the privacy of data, zero-knowledge machine learning (zkML) is generally optimistic, so will it be the future of on-chain AI? In this article, Odaily Planet Daily will briefly introduce the basic knowledge about zkML, the zkML projects worthy of attention, and finally briefly explain the limitations of zkML and alternative solutions. Basic knowledge about zkML Zero-knowledge machine learning (zkML) is similar to a confidentiality approach in computing.…













