Large amounts of financing are frequently raised. A comprehensive comparison of the six major infrastructure projects in
In the past year, AI narratives have been developing rapidly in the Crypto market. Leading VCs such as a16z, Sequoia, Lightspeed, and Polychain have invested tens of millions of dollars. Many high-quality teams with research backgrounds and prestigious university backgrounds have also entered Web3, moving towards decentralized AI. In the next 12 months, we will witness the gradual implementation of these high-quality projects.
In October this year, OpenAI raised another $6.6 billion, and the arms race in the AI field has reached an unprecedented height. Retail investors rarely have the opportunity to make money outside of direct investment in Nvidia and hardware, and this enthusiasm is bound to continue to spread to Crypto, especially the recent nationwide dog-catching trend driven by AI Meme. It is foreseeable that Crypto x AI, whether it is existing listed tokens or new star projects, will continue to have strong momentum.
As the decentralized AI leader Hyperbolic recently received secondary investment from Polychain and Lightspeed, we started from the six projects that have recently received large-scale financing from leading institutions, sorted out the development context of Crypto x AI infrastructure projects, and looked forward to how decentralized technology can safeguard the future of AI for mankind.
-
Hyperbolic: Recently announced the completion of a US$12 million Series A financing round led by Variant and Polychain, with a total financing amount of more than US$20 million. Well-known VCs such as Bankless Ventures, Chapter One, Lightspeed Faction, IOSG, Blockchain Builders Fund, Alumni Ventures, and Samsung Next participated in the investment.
-
PIN AI: Completed a $10 million pre-seed round of financing, with investments from well-known VCs including a16z CSX, Hack VC, and Blockchain Builders Fund (Stanford blockchain accelerator).
-
Vana: Completed $18 million in Series A financing and $5 million in strategic financing, with investments from well-known VCs such as Paradigm, Polychain, and Coinbase.
-
Sahara: Completed USD 43 million Series A financing, with investments from well-known VCs such as Binance Labs, Pantera Capital, and Polychain.
-
Aethir: Completed a $9 million Pre-A round of financing with a valuation of $150 million in 2023, and completed approximately $120 million in node sales in 2024.
-
IO.NET: Completed US$30 million in Series A financing, with investments from well-known VCs such as Hack VC, Delphi Digital, and Foresight Ventures.

The three elements of AI: data, computing power, and algorithms
Marx told us in Capital that means of production, productivity and production relations are the key elements in social production. If we make an analogy, we will find that there are also these three key elements in the world of artificial intelligence.
In the AI era, computing power, data and algorithms are key.
In AI, data is the means of production. For example, every day you type and chat on your phone, take photos and send them to your friends circle. These words and pictures are data. They are like the ingredients of AI and the basis for AI to operate.
This data includes structured numerical information to unstructured images, audio, video and text. Without data, AI algorithms cannot learn and optimize. The quality, quantity, coverage and diversity of data directly affect the performance of AI models and determine whether it can efficiently complete specific tasks.
In AI, computing power is productivity. Computing power is the underlying computing resource required to execute AI algorithms. The stronger the computing power, the faster the data can be processed and the better the effect. The strength of computing power directly determines the efficiency and capability of the AI system.
Powerful computing power can not only shorten the training time of the model, but also support more complex model architectures, thereby improving the intelligence level of AI. Large language models like OpenAIs ChatGPT require months to train on powerful computing clusters.
In AI, algorithms are production relations. Algorithms are the core of AI. Their design determines how data and computing power work together and is the key to transforming data into intelligent decisions. With the support of powerful computing power, algorithms can better learn patterns in data and apply them to practical problems.
In this way, data is equivalent to the fuel of AI, computing power is the engine of AI, and algorithm is the soul of AI. AI = data + computing power + algorithm. Any startup that wants to stand out in the AI track must have all three elements, or show a unique leading advantage in one of them.
As AI moves toward multimodality (models based on multiple forms of information, able to process text, images, audio, etc. simultaneously), the demand for computing power and data will only grow exponentially.
In an era of scarce computing power, Crypto empowers AI
The emergence of ChatGPT not only set off a revolution in artificial intelligence, but also inadvertently pushed computing power and computing hardware to the forefront of technology hot searches.
After the Thousand Model War in 2023, in 2024, as the markets understanding of AI big models continues to deepen, the global competition around big models is being divided into two paths: capability improvement and scenario development.
In terms of improving the capabilities of large models, the markets biggest expectation is GPT-5, which is rumored to be released by OpenAI this year. People are eagerly looking forward to its large model being pushed to a truly multimodal stage.
In terms of big model scenario development, AI giants are promoting the faster integration of big models into industry scenarios to generate application value. For example, attempts in the fields of AI Agent and AI search are constantly deepening the improvement of existing user experience by big models.
These two paths undoubtedly put forward higher demands on computing power. The improvement of large model capabilities is mainly based on training, which requires the use of huge high-performance computing power in a short period of time; large model scenario applications are mainly based on reasoning, which has relatively low requirements on computing power performance, but pays more attention to stability and low latency.
As OpenAI estimated in 2018, the computing power required to train large models has doubled every 3.5 months since 2012, with the annual computing power required increasing by as much as 10 times. At the same time, as large models and applications are increasingly deployed in actual business scenarios of enterprises, the demand for inference computing power is also rising.
The problem is that the demand for high-performance GPUs is growing rapidly worldwide, while supply has not kept up. Nvidias H100 chip, for example, experienced a severe supply shortage in 2023, with a supply gap of more than 430,000 chips. The upcoming B100 chip, which will have a 2.5-fold performance increase and a cost increase of only 25%, is likely to be in short supply again. This imbalance between supply and demand will lead to another increase in computing power costs, making it difficult for many small and medium-sized enterprises to afford the high computing costs, thereby limiting their development potential in the field of AI.
Large technology companies such as OpenAI, Google, and Meta have more powerful resource acquisition capabilities and have the money and resources to build their own computing infrastructure. But what about AI startups, let alone those that have not yet received funding?
Indeed, buying second-hand GPUs on platforms such as eBay and Amazon is also a feasible method. Although it reduces costs, there may be performance issues and long-term maintenance costs. In this era of scarce GPUs, building infrastructure will probably never be the best solution for startups.
Even though there are GPU cloud providers that can rent on demand, the high prices are still a big challenge for them. For example, an Nvidia A100 costs about $80 per day. If 50 of them are needed to run 25 days a month, the cost of computing power alone is as high as 80 x 50 x 25 = $100,000 per month.
This gives decentralized computing networks based on DePIN an opportunity to take advantage of the situation. As IO.NET, Aethir, and Hyperbolic have done, they transfer the computing infrastructure costs of AI startups to the network itself. And it allows anyone in the world to connect unused GPUs at home, greatly reducing computing costs.
Aethir: A global GPU sharing network that makes computing power accessible to everyone
Aethir completed a $9 million Pre-A round of financing at a valuation of $150 million in September 2023, and completed approximately $120 million in Checker Node sales from March to May this year. Aethir earned $60 million in revenue from the sale of Checker Node in just 30 minutes, which shows the markets recognition and expectations for the project.
The core of Aethir is to build a decentralized GPU network, so that everyone has the opportunity to contribute their idle GPU resources and gain benefits. This is like turning everyones computer into a small supercomputer, and everyone shares computing power together. The advantage of doing so is that it can greatly improve the utilization rate of GPUs and reduce resource waste. At the same time, it can also allow companies or individuals who need a lot of computing power to obtain the required resources at a lower cost.
Aethir has created a decentralized DePIN network, which is like a resource pool, encouraging data centers, game studios, technology companies, and gamers from all over the world to connect idle GPUs to it. These GPU providers can freely connect or exit the network, so they have higher utilization than idle. This enables Aethir to provide GPU resources from consumer, professional to data center levels to computing power demanders, and the price is more than 80% lower than that of Web2 cloud providers.
Aethirs DePIN architecture ensures the quality and stability of these scattered computing powers. The three core parts are:
Container is Aethirs computing unit, acting as a cloud server responsible for executing and rendering applications. Each task is encapsulated in an independent container, which serves as a relatively isolated environment to run the customers tasks, avoiding interference between tasks.
Indexer is mainly used to instantly match and schedule available computing resources according to task requirements. At the same time, the dynamic resource adjustment mechanism can dynamically allocate resources to different tasks according to the load of the entire network to achieve the best overall performance.
Checker is responsible for real-time monitoring and evaluation of the performance of the Container. It can monitor and evaluate the status of the entire network in real time and respond promptly to possible security issues. If you need to respond to security incidents such as network attacks, after detecting abnormal behavior, you can issue warnings and initiate protective measures in a timely manner. Similarly, when there is a bottleneck in network performance, Checker can also issue reminders in a timely manner so that the problem can be solved in a timely manner, ensuring service quality and security.

The effective collaboration among Container, Indexer, and Checker provides customers with the freedom to customize computing power configuration, and a secure, stable, and relatively inexpensive cloud service experience. For fields such as AI and gaming, Aethir is a good commercial-grade solution.
In general, Aethir has reshaped the allocation and use of GPU resources through DePIN, making computing power more popular and economical. It has achieved some good results in the fields of AI and games, and is constantly expanding its partners and business lines, with unlimited potential for future development.
IO.NET: A distributed supercomputing network that breaks the computing bottleneck
IO.NET completed a $30 million Series A funding round in March this year, with investments from well-known VCs such as Hack VC, Delphi Digital, and Foresight Ventures.
Similar to Aethir, it aims to build an enterprise-level decentralized computing network that brings together idle computing resources (GPU, CPU) around the world to provide AI startups with lower-priced, more accessible, and more flexibly adaptable computing services.
Unlike Aethir, IO.NET uses the Ray framework (IO-SDK) to transform thousands of GPU clusters into a whole for machine learning (the Ray framework is also used by OpenAI to train GPT-3). When training large models on a single device, CPU/GPU memory limitations and sequential processing workflows present huge bottlenecks. Using the Ray framework for orchestration and batch processing enables parallelization of computing tasks.
To this end, IO.NET adopts a multi-layer architecture:
-
User interface layer: Provides a visual front-end interface for users, including the public website, customer area, and GPU vendor area, aiming to provide an intuitive and friendly user experience.
-
Security layer: ensures the integrity and security of the system, integrating network protection, user authentication, and activity logging mechanisms.
-
API layer: Serves as a communication hub for websites, suppliers, and internal management, facilitating data exchange and execution of various operations.
-
Backend layer: constitutes the core of the system and is responsible for managing clusters/GPUs, customer interactions, automatic expansion and other operational tasks.
-
Database layer: responsible for data storage and management, primary storage is responsible for structured data, and cache is used for temporary data processing.
-
Task layer: manages asynchronous communication and task execution to ensure efficient data processing and flow.
-
Infrastructure layer: It forms the foundation of the system, including GPU resource pool, orchestration tools, and execution/ML tasks, equipped with a powerful monitoring solution.

From a technical point of view, IO.NET has introduced the layered architecture of its core technology IO-SDK to solve the difficulties faced by distributed computing power, as well as reverse tunnel technology and mesh VPN architecture to solve the problems of secure connection and data privacy. It is popular in Web3 and is called the next Filecoin, with a bright future.
In general, the core mission of IO.NET is to build the worlds largest DePIN infrastructure, bringing together idle GPU resources around the world to provide support for AI and machine learning fields that require a lot of computing power.
Hyperbolic: Building an AI Rainforest to achieve a prosperous and mutually supportive distributed AI infrastructure ecosystem
Today, Hyperbolic announced that it has completed a round of A financing of more than $12 million, led by Variant and Polychain Capital, with a total financing amount of more than $20 million. Well-known VC institutions such as Bankless Ventures, Chapter One, Lightspeed Faction, IOSG, Blockchain Builders Fund, Alumni Ventures, and Samsung Next participated in the investment. Among them, the top Silicon Valley venture capital Polychain and LightSpeed Faction increased their investment after the seed round, which is enough to show Hyperbolics leading position in the Web3 AI track.
Hyperbolics core mission is to make AI accessible to everyone, affordable for developers and affordable for creators. Hyperbolic aims to build an AI rainforest where developers can find the necessary resources to innovate, collaborate, and grow. Just like a natural rainforest, the ecosystem is interconnected, vibrant, and renewable, allowing creators to explore without limits.
In the view of the two co-founders Jasper and Yuchen, although AI models can be open source, it is still not enough without open computing resources. Currently, many large data centers control GPU resources, which makes many people who want to use AI discouraged. Hyperbolic aims to break this situation. They integrate idle computing resources around the world to establish DePIN computing infrastructure, so that everyone can easily use AI.
Therefore, Hyperbolic introduced the concept of open AI cloud, which can connect to Hyperbolic to provide computing power, from personal computers to data centers. On this basis, Hyperbolic created a verifiable and privacy-guaranteed AI layer, allowing developers to build AI applications with reasoning capabilities, and the required computing power comes directly from the AI cloud.

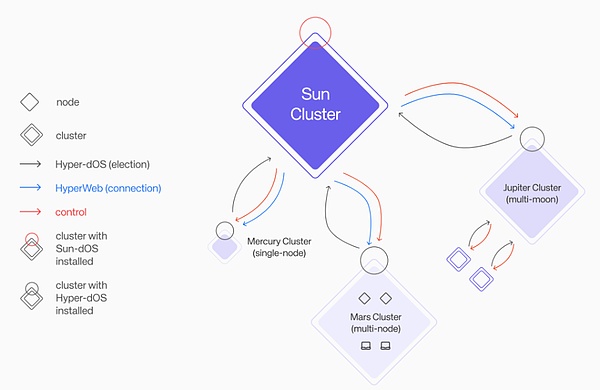
Similar to Aethir and IO.NET, Hyperbolics AI cloud has its own unique GPU cluster model, called the Solar System Cluster. As we all know, the solar system contains various independent planets such as Mercury and Mars. Hyperbolics Solar System Cluster manages the Mercury cluster, Mars cluster, and Jupiter cluster. These GPU clusters are widely used and of different sizes, but they are independent of each other and are scheduled by the Solar System.
This model ensures that the GPU cluster meets two characteristics, which is more flexible and more efficient than Aethir and IO.NET :
-
Adjust the state balance, the GPU cluster will automatically expand or shrink according to demand
-
If a cluster is interrupted, the Solar System cluster will automatically detect and repair it
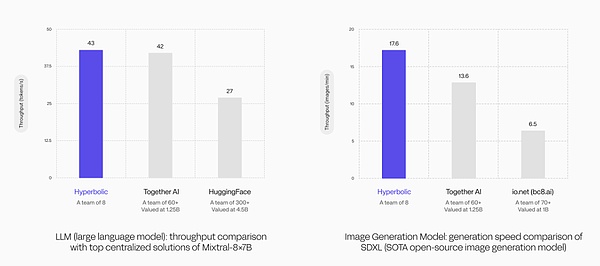
In the performance comparison experiment of the large language model (LLM), the throughput of the Hyperbolic GPU cluster reached 43 tokens/s, which not only exceeded the 42 tokens/s of the Together AI team consisting of 60 people, but was also significantly higher than the 27 tokens/s of HuggingFace, which has more than 300 team members.
In the generation speed comparison experiment of the image generation model, the Hyperbolic GPU cluster also demonstrated its technical strength. Using the same SOTA open source image generation model, Hyperbolic led with a generation speed of 17.6 images/min, which not only exceeded Together AIs 13.6 images/min, but was also much higher than IO.NETs 6.5 images/min.
These data strongly prove that Hyperbolics GPU cluster model has extremely high efficiency, and its excellent performance makes it stand out from its larger competitors. Combined with the advantage of low price, this makes Hyperbolic very suitable for complex AI applications that require high computing power to support, provide near real-time response, and ensure that AI models have higher accuracy and efficiency when processing complex tasks.
In addition, from the perspective of การเข้ารหัสลับgraphic innovation, we believe that Hyperbolics most noteworthy achievement is the development of the verification mechanism PoSP (Proof of Sampling), which uses a decentralized approach to solve one of the most difficult challenges in the field of AI – verifying whether the output comes from a specified model, thereby enabling the reasoning process to be decentralized cost-effectively.

Based on the PoSP principle, the Hyperbolic team developed the spML mechanism (sampling machine learning) for AI applications, which randomly samples transactions in the network, rewards honest people and punishes dishonest people to achieve a lightweight verification effect, reducing the computational burden of the network, allowing almost any AI startup to decentralize their AI services in a distributed verifiable paradigm.
The specific implementation process is as follows:
1) The node calculates the function and submits the result to the scheduler in an encrypted manner.
2) The scheduler then decides whether to trust the result, and if so, the node is rewarded for the computation.
3) If there is no trust, the scheduler will randomly select a validator in the network, challenge the node, and calculate the same function. Similarly, the validator submits the result to the scheduler in an encrypted manner.
4) Finally, the scheduler checks whether all the results are consistent. If they are consistent, both the node and the validator will be rewarded. If they are inconsistent, an arbitration procedure will be initiated to trace the calculation process of each result. Honest people will be rewarded for their accuracy, and dishonest people will be punished for deceiving the system.
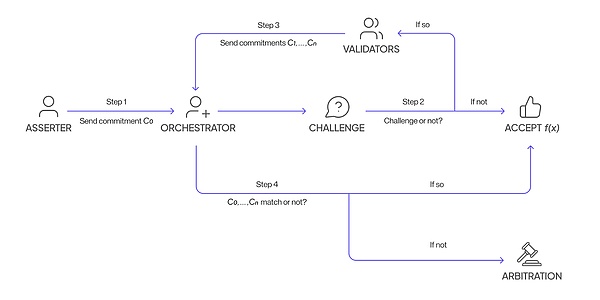
Nodes do not know whether the results they submit will be challenged, nor do they know which validator the scheduler will choose to challenge to ensure the fairness of the verification. The cost of cheating far exceeds the potential benefits.
If spML is verified in the future, it will be enough to change the rules of the game for AI applications and make trustless reasoning verification a reality. In addition, Hyperbolic has the unique ability in the industry to use the BF 16 algorithm in model reasoning (comparable companies are still at FP 8), which can effectively improve the accuracy of reasoning, making Hyperbolics decentralized reasoning service extremely cost-effective.
In addition, Hyperbolics innovation is also reflected in its integration of AI cloud computing power supply and AI applications. The demand for decentralized computing power market itself is relatively scarce. Hyperbolic attracts developers to build AI applications by building a verifiable AI infrastructure. The computing power can be directly and seamlessly integrated into AI applications without sacrificing performance and security. After expanding to a certain scale, it can be self-sufficient and achieve a balance between supply and demand.
Developers can build innovative AI applications around computing power, Web2 and Web3 on Hyperbolic, such as:
-
จีพียู แลกเปลี่ยน, a GPU trading platform built on the GPU network (orchestration layer), commoditizes GPU resources for free trading, making computing power more cost-effective.
-
IAO, or tokenizing AI Agent, allows contributors to earn tokens, and the revenue of AI Agent will be distributed to token holders.
-
AI-driven DAOs are DAOs that use artificial intelligence to help with governance decisions and financial management.
-
GPU Restaking allows users to connect their GPUs to Hyperbolic and then stake them to AI applications.
In general, Hyperbolic has built an open AI ecosystem that allows everyone to easily use AI. Through technological innovation, Hyperbolic is making AI more popular and accessible, making the future of AI full of interoperability and compatibility, and encouraging collaborative innovation.
Data returns to users, riding the AI wave together
Nowadays, data is a gold mine , and personal data is being grabbed and commercialized for free by technology giants.
Data is the food of AI. Without high-quality data, even the most advanced algorithms cannot perform their functions. The quantity, quality, and diversity of data directly affect the performance of AI models.
As we mentioned earlier, the industry is looking forward to the launch of GPT-5. However, it has not been released yet, probably because the amount of data is not enough. GPT-3 alone, which is in the stage of publishing papers, requires 2 trillion tokens of data. GPT-5 is expected to reach 200 trillion tokens of data. In addition to the existing text data, more multimodal data is needed, which can be used for training after cleaning.
In todays public Internet data, high-quality data samples are relatively rare. A reality is that large models perform very well in question-and-answer generation in any field, but perform poorly when faced with questions in professional fields, and there may even be an illusion that the model is talking nonsense in a serious manner.
To ensure the “freshness” of their data, AI giants often strike deals with owners of large data sources. For example, OpenAI signed a $60 million deal with Reddit.
Recently, some social software has begun to require users to sign an agreement to authorize the use of their content for the training of third-party AI models, but users do not receive any rewards. This predatory behavior has aroused public doubts about the right to use data.
Obviously, the decentralized and traceable potential of blockchain is naturally suitable for improving the acquisition of data and resources, while providing more control and transparency for user data, and also allowing users to earn benefits by participating in the training and optimization of AI models. This new way of creating data value will greatly increase user participation and promote the overall prosperity of the ecosystem.
Web3 already has some companies targeting AI data, such as:
-
Data acquisition: Ocean Protocol, Vana, PIN AI, Sahara, etc.
-
Data processing: Public AI, Lightworks, etc.
Among them, Vana, PIN AI, and Saraha are more interesting, which happened to have received large amounts of financing recently, with a luxurious lineup of investors. Both projects have gone beyond the sub-fields, combining data acquisition with AI development to promote the implementation of AI applications.
Vana: Users control data, DAO and contribution mechanism reshape AI data economy
Vana completed a round of financing of US$18 million in December 2022 and completed a strategic financing of US$5 million in September this year. Well-known VCs such as Paradigm, Polychain, and Coinbase have invested in it.
The core concept of Vana is user-owned data, user-owned AI. In this era where data is king, Vana wants to break the monopoly of large companies on data, allowing users to control their own data and benefit from their own data.
Vana is a decentralized data network that focuses on protecting private data and enabling users data to be used flexibly like financial assets. Vana attempts to reshape the data economy and transform users from passive data providers to active participants and co-benefiting ecosystem builders.
To achieve this vision, Vana allows users to collect and upload data through the Data DAO, and then verify the value of the data while protecting privacy through the contribution proof mechanism. This data can be used for AI training, and users are incentivized based on the quality of the uploaded data.
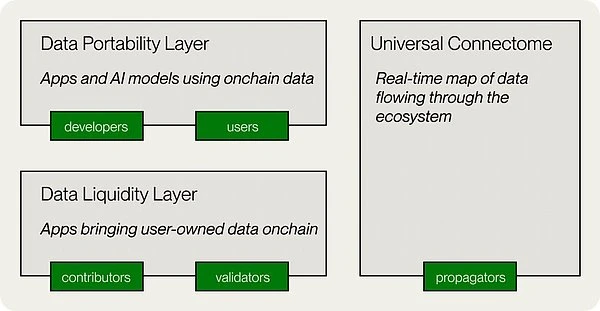
In terms of implementation, Vanas technical architecture includes five key components: data liquidity layer, data portability layer, universal connection group, non-custodial data storage, and decentralized application layer.
Data Liquidity Layer : This is the core of the Vana Network, which incentivizes, aggregates, and verifies valuable data through Data Liquidity Pools (DLP). DLP is like a data version of a liquidity pool. Each DLP is a smart contract that is specifically used to aggregate a specific type of data asset, such as social media data such as Reddit and Twitter.
Data Portability Layer : This component provides portability to user data, ensuring that users can easily transfer and use their data between different applications and AI models.
Data Ecosystem Map : This is a map that tracks the real-time data flow of the entire ecosystem, ensuring transparency.
Non-custodial data storage : Vana’s innovation lies in its unique data management method, which allows users to always maintain full control over their data. The user’s original data will not be uploaded to the chain, but the user can choose the storage location by themselves, such as a cloud server or a personal server.
Decentralized application layer : Based on data, Vana has built an open application ecosystem where developers can use the data accumulated by DLP to build various innovative applications, including AI applications, and data contributors can receive dividend rewards from these applications.
Currently, Vana has built DLPs around social media platforms such as ChatGPT, Reddit, LinkedIn, and Twitter, as well as those focusing on AI and browsing data. As more DLPs are added and more innovative applications are built on the platform, Vana has the potential to become the next generation of decentralized AI and data economy infrastructure.
This reminds us of a recent news story. In order to improve the diversity of LLM, Meta is collecting data from Facebook and Instagram UK users, but it has been criticized for forcing users to choose opt out instead of agree. Perhaps it would be a better choice for Meta to build a DLP for Facebook and Instagram on Vana, which not only ensures data privacy, but also encourages more users to actively contribute data.
PIN AI: Decentralized AI assistant, mobile AI connects data and daily life
PIN AI completed a $10 million pre-seed round of financing in September this year. A number of well-known VCs and angel investors including a16z CSX, Hack VC, and Blockchain Builders Fund (Stanford Blockchain Accelerator) participated in this investment.
PIN AI is an open AI network powered by a distributed data storage network based on the DePIN architecture. Users can connect their devices to the network, provide personal data/user preferences, and receive token incentives. This enables users to regain control and monetize their data. Developers can use the data to build useful AI Agents in it.
Its vision is to become a decentralized alternative to Apple Intelligence, dedicated to providing user groups with applications that are useful for daily life and realizing the intentions proposed by users, such as purchasing goods online, planning travel, and planning investment behaviors.
PIN AI consists of two types of AI, personal AI assistant and external AI service.
Personal AI assistants can access user data, collect user needs, and provide corresponding data to external service AI when they need data. The underlying layer of PIN AI is composed of DePIN distributed data storage network, which provides rich user data for the reasoning of external AI services, while being unable to access the users personal privacy.

With PIN AI, users will no longer need to open thousands of mobile apps to complete different tasks. When users express their intentions to their personal AI assistants, such as I want to buy a new dress, What kind of takeaway should I order, or Find the best investment opportunities in this article, the AI not only understands the users preferences, but can also perform all these tasks efficiently – it will find the most relevant applications and service providers to achieve the users intentions in the form of bidding.
Most importantly, PIN AI realizes the necessity of introducing a decentralized service that can provide more value under the current dilemma that users are accustomed to interacting directly with centralized service providers to obtain services. Personal AI assistants can legitimately obtain high-value data generated when users interact with Web2 applications in the name of users, and store and call them in a decentralized manner, so that the same data can play a greater role and benefit both data owners and callers.
Although the PIN AI mainnet has not yet been officially launched, the team has demonstrated the prototype of the product to users to a small extent through Telegram to facilitate their perception of the vision.
Hi PIN Bot consists of three sections: Play, Data Connectors, and AI Agent.
Play is an AI virtual companion powered by big models like PIN AI-1.5 b, Gemma, Llama, etc. This is equivalent to PIN AIs personal AI assistant .
In Data Connectors, users can connect to Google, Facebook, X, and Telegram accounts to earn points to upgrade their virtual companions. In the future, users will also be able to connect to Amazon, Ebay, Uber and other accounts. This is equivalent to the DePIN data network of PIN AI.
You use your own data for your own use. After connecting the data, users can make requests to their virtual partners (Coming soon), and the virtual partners will provide the users data to the AI Agent that meets the task requirements for processing.
The official has developed some AI Agent prototypes, which are still in the testing phase. These are equivalent to PIN AIs external AI services . For example, X Insight, input a Twitter account, and it can analyze the operation of the account. When Data Connectors support e-commerce, food delivery and other platform accounts, AI Agents such as Shopping and Order Food will also be able to play a role and autonomously process orders placed by users.
In general, through the form of DePIN+AI, PIN AI has established an open AI network, allowing developers to build truly useful AI applications, making users lives more convenient and intelligent. As more developers join, PIN AI will bring more innovative applications, allowing AI to truly integrate into daily life.
Sahara: Multi-layer architecture แนะนำs AI data rights confirmation, privacy, and fair trade
Sahara completed a $43 million Series A financing round in August this year, with investments from well-known VCs such as Binance Labs, Pantera Capital, and Polychain.
Sahara AI is a multi-layered AI blockchain application platform that focuses on establishing a more fair and transparent AI development model in the AI era that can attribute the value of data and distribute profits to users, and solve the pain points of privacy, security, data acquisition and transparency in traditional AI systems.
In laymans terms, Sahara AI wants to build a decentralized AI network that allows users to control their own data and receive rewards based on the quality of the data they contribute. In this way, users are no longer passive data providers, but become ecosystem builders who can participate and share the benefits.
Users can upload data to their decentralized data market , and then use a special mechanism to prove the ownership of the data (confirmation). The data can be used to train AI, and users are rewarded based on the quality of the data.
Sahara AI consists of four layers of architecture: application, transaction, data, and execution, providing a strong foundation for the development of the AI ecosystem.
-
ชั้นแอปพลิเคชัน : Provides tools such as secure vaults, decentralized AI data markets, no-code toolkits, and Sahara ID. These tools can ensure data privacy and promote fair compensation for users, and further simplify the process of creating and deploying AI applications.
Simply put, the vault uses advanced encryption technology to ensure the security of AI data; the decentralized AI data market can be used for data collection, labeling and transformation to promote innovation and fair trading; the no-code toolkit makes the development of AI applications easier; Sahara ID is responsible for managing user reputation and ensuring trust.
-
Transaction layer : Sahara blockchain uses a proof-of-stake (PoS) consensus mechanism to ensure network efficiency and stability, allowing consensus to be reached even in the presence of malicious nodes. In addition, Saharas native pre-compilation function is designed specifically for optimizing AI processing, and can perform efficient calculations directly in the blockchain environment to improve system performance.
-
Data layer : manages data on and off the chain. On-chain data processes untraceable operations and attribute records to ensure credibility and transparency; off-chain data processes large data sets and uses Merkle Tree and zero-knowledge proof technology to ensure data integrity and security to prevent data duplication and tampering.
-
เลเยอร์การดำเนินการ : abstracts the operations of vaults, AI models, and AI applications, and supports various AI training, reasoning, and service paradigms.
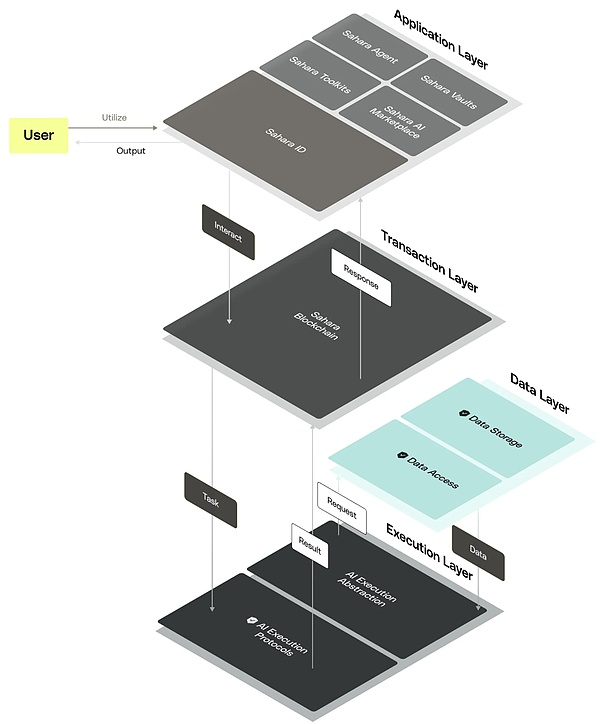
The entire four-layer architecture not only ensures the security and scalability of the system, but also reflects Sahara AI’s grand vision of promoting collaborative economy and AI development, aiming to completely change the application model of AI technology and bring more innovative and fair solutions to users.
บทสรุป
With the continuous advancement of AI technology and the rise of the crypto market, we are standing on the threshold of a new era.
As AI big models and applications continue to emerge, the demand for computing power is also growing exponentially. However, the scarcity of computing power and the rising costs are a huge challenge for many small and medium-sized enterprises. Fortunately, decentralized solutions, especially Hyperbolic, Aethir, and IO.NET, provide AI startups with new ways to obtain computing power, reduce costs, and improve efficiency.
At the same time, we also see the importance of data in the development of AI. Data is not only the food of AI, but also the key to promoting the implementation of AI applications. Projects such as PIN AI and Sahara encourage users to participate in data collection and sharing through incentive networks, providing strong data support for the development of AI.
Computing power and data are not just for training. For AI applications, from data intake to production reasoning, each link requires the use of different tools to process massive data, and this is a repetitive process.
In this world where AI and Crypto are intertwined, we have reason to believe that we will witness more innovative AI projects in the future. These projects will not only change our work and lifestyle, but will also drive the entire society towards a more intelligent and decentralized direction. With the continuous advancement of technology and the continuous maturity of the market, we look forward to the arrival of a more open, fair and efficient AI era.
This article is sourced from the internet: Large amounts of financing are frequently raised. A comprehensive comparison of the six major infrastructure projects in the Crypto x AI track shows which one will come out on top?








สวัสดี