Task
Ranking
已登录
Bee登录
Twitter 授权
TG 授权
Discord 授权
去签到
下一页
关闭
获取登录状态
My XP
0
원제: Glue 및 코프로세서 아키텍처
원저자: 이더리움 창시자 비탈릭 부테린
원문 번역: Deng Tong, Golden Finance
Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra 및 Flashbots에 기여하신 여러 분께 피드백과 의견을 제공해 주셔서 특별히 감사드립니다.
현대 세계에서 진행되는 모든 리소스 집약적 계산을 적당히 세부적으로 분석해 보면, 계산이 두 부분으로 나뉜다는 사실을 계속 발견하게 됩니다.
비교적 복잡하지만 계산 비용이 저렴한 비즈니스 로직
많은 집중적이지만 고도로 구조화된 "비용이 많이 드는 작업".
이 두 가지 컴퓨팅 형태는 각기 다르게 처리하는 것이 가장 좋습니다. 첫 번째 컴퓨팅 형태는 아키텍처의 효율성은 낮지만 매우 일반적이어야 하며, 두 번째 컴퓨팅 형태는 아키텍처의 효율성은 낮지만 매우 효율적이어야 합니다.
먼저, 제가 가장 잘 알고 있는 환경인 Ethereum Virtual Machine(EVM)을 살펴보겠습니다. 제가 최근에 한 Ethereum 거래의 geth 디버그 추적입니다. ENS에서 제 블로그의 IPFS 해시를 업데이트하는 것입니다. 이 거래는 총 46924 가스를 소비했는데, 다음과 같이 나눌 수 있습니다.
기본 비용: 21,000
통화 데이터: 1,556 EVM
실행: 24,368 SLOAD
Opcode: 6,400 SSTORE
명령어: 10, 100 LOG
명령어: 2, 149
기타 : 6,719
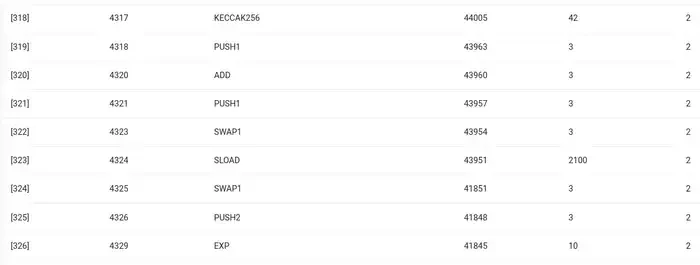
ENS 해시 업데이트의 EVM 추적. 마지막에서 두 번째 열은 가스 비용입니다.
이 이야기의 교훈은 이렇습니다. 실행의 대부분(EVM만 보면 ~73%, 컴퓨팅을 포함하는 기본 비용 부분을 포함하면 ~85%)은 매우 소수의 구조화된 값비싼 작업, 즉 저장소 읽기 및 쓰기, 로깅 및 암호화(기본 비용에는 지불 서명 검증을 위한 3000이 포함되고 EVM에는 지불 해싱을 위한 추가 272가 포함됨)에 집중되어 있습니다. 나머지 실행은 비즈니스 로직입니다. 즉, 호출 데이터 비트를 교환하여 설정하려는 레코드의 ID와 설정하는 해시를 추출하는 등입니다. 토큰 전송에서는 잔액을 더하고 빼는 작업이 포함되고, 보다 고급 애플리케이션에서는 루프 등이 포함될 수 있습니다.
EVM에서 이 두 가지 실행 형태는 다르게 처리됩니다. 상위 비즈니스 로직은 일반적으로 EVM으로 컴파일되는 Solidity와 같은 상위 레벨 언어로 작성됩니다. 여전히 EVM 명령어(SLOAD 등)에 의해 비용이 많이 드는 작업이 트리거되지만 실제 계산의 99% 이상은 클라이언트 코드(또는 라이브러리) 내부에 직접 작성된 전용 모듈에서 수행됩니다.
이 패턴에 대한 이해를 강화하기 위해, torch.py를 사용하여 Python으로 작성된 AI 코드라는 다른 맥락에서 이를 살펴보겠습니다.

Transformer 모델의 한 블록의 포워드 패스
여기서 무엇을 볼 수 있을까요? Python으로 작성된 비교적 적은 양의 "비즈니스 로직"을 볼 수 있는데, 이는 수행되는 작업의 구조를 설명합니다. 실제 애플리케이션에서는 입력을 얻는 방법과 출력에서 수행할 작업과 같은 세부 사항을 결정하는 또 다른 유형의 비즈니스 로직이 있을 것입니다. 그러나 각 개별 작업 자체(self.norm, torch.cat, +, *, self.attn, ... 내부의 개별 단계)를 자세히 살펴보면 벡터화된 계산을 볼 수 있습니다. 동일한 작업이 많은 수의 값을 병렬로 계산합니다. 첫 번째 예와 유사하게 계산의 일부는 비즈니스 로직에 사용되고 대부분의 계산은 대규모 구조화된 행렬 및 벡터 연산을 수행하는 데 사용됩니다. 사실 대부분은 행렬 곱셈에 불과합니다.
EVM 예에서와 마찬가지로, 이 두 가지 유형의 작업은 두 가지 다른 방식으로 처리됩니다. 고수준 비즈니스 로직 코드는 매우 일반적이고 유연한 언어인 Python으로 작성되지만, 매우 느리고, 전체 계산 비용의 작은 부분만 포함하기 때문에 비효율성을 그냥 받아들입니다. 동시에, 집약적인 작업은 일반적으로 GPU에서 실행되는 CUDA 코드인 고도로 최적화된 코드로 작성됩니다. 점점 더 LLM 추론이 ASIC에서 수행되는 것을 보게 되었습니다.
SNARK와 같은 최신 프로그래밍 가능 암호화는 두 가지 수준에서 유사한 패턴을 따릅니다. 첫째, 증명자는 위의 AI 예와 마찬가지로 벡터화된 연산으로 무거운 작업을 수행하는 고급 언어로 작성될 수 있습니다. 여기 있는 저의 원형 STARK 코드는 이를 보여줍니다. 둘째, 암호화 자체 내부에서 실행되는 프로그램은 일반적인 비즈니스 로직과 고도로 구조화된 값비싼 작업으로 구분된 방식으로 작성될 수 있습니다.
이것이 어떻게 작동하는지 이해하기 위해, 우리는 STARK 증명의 최신 트렌드 중 하나를 살펴볼 수 있습니다. 일반적이고 사용하기 쉬운 것을 위해, 팀들은 RISC-V와 같은 널리 채택된 최소 가상 머신을 위한 STARK 증명자를 점점 더 많이 구축하고 있습니다. 실행을 증명해야 하는 모든 프로그램은 RISC-V로 컴파일될 수 있으며, 그런 다음 증명자는 해당 코드의 RISC-V 실행을 증명할 수 있습니다.
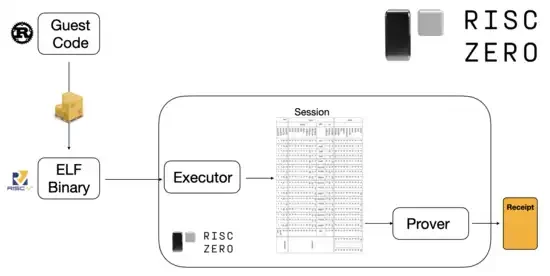
RiscZero 문서의 다이어그램
이것은 매우 편리합니다. 즉, 증명 논리를 한 번만 작성하면 되고, 그 이후로 증명이 필요한 모든 프로그램은 모든 기존 프로그래밍 언어로 작성할 수 있습니다(예: RiskZero는 Rust를 지원합니다). 그러나 한 가지 문제가 있습니다. 이 접근 방식은 많은 오버헤드를 발생시킵니다. 프로그래밍 가능한 암호화는 이미 매우 비쌉니다. RISC-V 인터프리터에서 코드를 실행하는 오버헤드를 추가하는 것은 너무 많습니다. 그래서 개발자들은 한 가지 요령을 생각해냈습니다. 계산의 대부분을 구성하는 특정 비싼 작업(일반적으로 해싱 및 서명)을 식별한 다음 이러한 작업을 매우 효율적으로 증명하는 특수 모듈을 만듭니다. 그런 다음 비효율적이지만 일반적인 RISC-V 증명 시스템과 효율적이지만 특수화된 증명 시스템을 결합하면 두 가지의 장점을 모두 얻을 수 있습니다.
ZK-SNARK를 넘어서는 다자간 계산(MPC) 및 완전 동형 암호화(FHE)와 같은 프로그래밍 가능 암호화는 유사한 접근 방식을 사용하여 최적화될 수 있습니다.
현대 컴퓨팅은 점점 더 제가 접착 및 보조 프로세서 아키텍처라고 부르는 것을 따릅니다. 즉, 중앙 접착 구성 요소가 있는데, 이 구성 요소는 일반성은 높지만 효율성이 낮고, 하나 이상의 보조 프로세서 구성 요소 간에 데이터를 전달해야 합니다. 이 보조 프로세서 구성 요소는 일반성은 낮지만 효율성이 높습니다.

이는 단순화한 것입니다. 실제로 효율성과 일반성 간의 트레이드오프 곡선은 거의 항상 두 개 이상의 수준을 갖습니다. 업계에서 종종 "코프로세서"라고 불리는 GPU 및 기타 칩은 CPU보다 덜 일반적이지만 ASIC보다 더 일반적입니다. 전문화 정도 측면에서의 트레이드오프는 복잡하며 알고리즘의 어떤 부분이 5년 후에 동일하게 유지되고 어떤 부분이 6개월 후에 변경될지에 대한 예측과 직관에 따라 달라집니다. 우리는 종종 ZK 증명 아키텍처에서 유사한 여러 수준의 전문화를 봅니다. 그러나 광범위한 정신 모델의 경우 두 수준을 고려하면 충분합니다. 컴퓨팅의 많은 영역에서 유사한 상황이 있습니다.
위의 예에서 컴퓨팅이 이런 식으로 분리될 수 있다는 것은 확실히 자연스러운 법칙처럼 보입니다. 사실, 수십 년 전으로 거슬러 올라가는 컴퓨팅 전문화의 예를 찾을 수 있습니다. 그러나 저는 이러한 분리가 증가하고 있다고 생각합니다. 저는 이에 대한 이유가 있다고 생각합니다.
우리는 최근에야 CPU 클럭 속도 증가의 한계에 도달했기 때문에, 더 많은 이득은 병렬화를 통해서만 얻을 수 있습니다. 그러나 병렬화는 추론하기 어렵기 때문에 개발자가 순차적으로 추론하고 병렬화가 백엔드에서 발생하도록 하는 것이 더 실용적입니다. 이는 특정 작업을 위해 빌드된 전용 모듈에 래핑됩니다.
계산이 최근에야 너무 빨라져서 비즈니스 로직의 계산 비용이 정말 무시할 수 있게 되었습니다. 이 세상에서는 계산 효율성이 아닌 다른 목표, 즉 개발자 친화성, 친숙성, 보안 및 이와 유사한 목표를 위해 비즈니스 로직이 실행되는 VM을 최적화하는 것도 합리적입니다. 그동안 전용 코프로세서 모듈은 효율성을 위해 계속 설계될 수 있으며 바인더에 대한 비교적 간단한 인터페이스에서 보안 및 개발자 친화성을 얻을 수 있습니다.
가장 중요한 비용이 많이 드는 작업이 무엇인지 점점 더 분명해지고 있습니다. 이는 암호화에서 가장 두드러지는데, 여기서는 특정 유형의 비용이 많이 드는 작업이 가장 많이 사용될 가능성이 높습니다. 모듈러 작업, 타원 곡선 선형 조합(일명 다중 스칼라 곱셈), 고속 푸리에 변환 등이 있습니다. 이는 AI에서도 점점 더 분명해지고 있는데, 20년 이상 대부분의 계산이 주로 행렬 곱셈(다양한 수준의 정밀도)이었습니다. 다른 분야에서도 비슷한 추세가 나타나고 있습니다. (계산 집약적) 계산에서 알려지지 않은 미지수는 20년 전보다 훨씬 적습니다.
핵심은 접착제가 좋은 접착제가 되도록 최적화되어야 하고, 코프로세서도 좋은 코프로세서가 되도록 최적화되어야 한다는 것입니다. 우리는 몇 가지 핵심 영역에서 이것의 의미를 탐구할 수 있습니다.
블록체인 가상 머신(예: EVM)은 효율적일 필요는 없고, 친숙하기만 하면 됩니다. 적절한 코프로세서(일명 사전 컴파일)를 추가하면 비효율적인 VM의 계산이 실제로 네이티브 효율적인 VM의 계산만큼 효율적일 수 있습니다. 예를 들어, EVM의 256비트 레지스터가 발생시키는 오버헤드는 비교적 작은 반면, EVM의 친숙성과 기존 개발자 생태계의 이점은 크고 지속적입니다. EVM을 최적화하는 개발팀은 병렬화 부족이 일반적으로 확장성에 대한 주요 장벽이 아니라는 것을 발견했습니다.
EVM을 개선하는 가장 좋은 방법은 (i) 더 나은 사전 컴파일 또는 특수화된 명령어를 추가하는 것, 예를 들어 EVM-MAX와 SIMD를 조합하는 것이 합리적일 수 있고, (ii) 저장소 레이아웃을 개선하는 것, 예를 들어 Verkle 트리를 변경하여 인접한 저장소 슬롯에 액세스하는 비용을 크게 줄이는 것일 수 있습니다. 이는 부작용입니다.
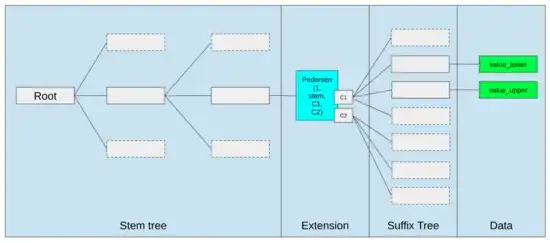
Ethereum의 Verkle 트리 제안의 스토리지 최적화는 인접한 스토리지 키를 함께 배치하고 이를 반영하기 위해 가스 비용을 조정합니다. 이와 같은 최적화는 더 나은 사전 컴파일과 결합하면 EVM 자체를 조정하는 것보다 더 중요할 수 있습니다.
하드웨어 수준에서 현대 컴퓨팅의 보안을 개선하는 데 있어 가장 큰 과제 중 하나는 지나치게 복잡하고 독점적인 특성입니다. 칩은 효율적이도록 설계되어 독점적인 최적화가 필요합니다. 백도어는 숨기기 쉽고 사이드 채널 취약성은 끊임없이 발견됩니다.
더욱 개방적이고 안전한 대안을 추진하려는 노력은 여러 각도에서 계속되고 있습니다. 일부 컴퓨팅은 사용자의 휴대전화를 포함하여 신뢰할 수 있는 실행 환경에서 점점 더 많이 수행되고 있으며, 이는 사용자의 보안을 개선했습니다. 더 많은 오픈 소스 소비자 하드웨어에 대한 추진은 계속되고 있으며, Ubuntu를 실행하는 RISC-V 노트북과 같은 최근의 승리도 있습니다.

Debian을 실행하는 RISC-V 노트북
그러나 효율성은 여전히 문제로 남아 있습니다. 위에 링크된 기사의 저자는 다음과 같이 썼습니다.
RISC-V와 같은 최신 오픈소스 칩 설계는 수십 년 동안 존재하고 개선된 프로세서 기술과 경쟁할 수 없습니다. 진보는 항상 어딘가에서 시작해야 합니다.
FPGA에 RISC-V 컴퓨터를 구축하는 이 설계와 같은 더욱 편집증적인 아이디어는 훨씬 더 큰 오버헤드에 직면합니다. 하지만 글루와 코프로세서 아키텍처가 이 오버헤드가 실제로 중요하지 않다는 것을 의미한다면 어떨까요? 개방적이고 안전한 칩이 독점 칩보다 느리다는 것을 받아들이고 필요한 경우 추측 실행 및 분기 예측과 같은 일반적인 최적화를 포기하지만 가장 집약적인 특정 유형의 계산에 사용되는 (필요한 경우 독점적인) ASIC 모듈을 추가하여 이를 보완하려고 시도한다면 어떨까요? 민감한 계산은 보안, 오픈 소스 설계 및 사이드 채널 저항에 최적화된 "메인 칩"에서 수행할 수 있습니다. 보다 집약적인 계산(예: ZK 증명, AI)은 수행되는 계산에 대한 정보가 적은 ASIC 모듈에서 수행됩니다(잠재적으로 암호화 블라인딩을 통해 또는 어떤 경우에는 정보가 전혀 없음).
또 다른 핵심 요점은 이 모든 것이 암호화, 특히 프로그래밍 가능 암호화가 주류가 되는 것에 대해 매우 낙관적이라는 것입니다. 우리는 이미 SNARK, MPC 및 기타 설정에서 특정 고도로 구조화된 계산의 매우 최적화된 구현을 보았습니다. 일부 해시 함수는 계산을 직접 실행하는 것보다 몇 백 배 더 비쌀 뿐이며 AI(주로 행렬 곱셈)도 오버헤드가 매우 낮습니다. GKR과 같은 추가 개선 사항은 이를 더욱 줄일 수 있습니다. 특히 RISC-V 인터프리터에서 실행되는 경우 완전히 일반적인 VM 실행은 아마도 약 10,000배의 오버헤드를 계속 가질 것이지만 이 논문에서 설명한 이유로 이는 중요하지 않습니다. 계산의 가장 집약적인 부분이 효율적이고 전문적인 기술을 사용하여 별도로 처리되는 한 전체 오버헤드는 관리 가능합니다.
AI 모델 추론에서 가장 큰 구성 요소인 행렬 곱셈을 위한 전용 MPC의 단순화된 다이어그램. 모델과 입력이 비공개로 유지되는 방법을 포함하여 자세한 내용은 이 문서를 참조하세요.
접착 레이어가 효율적이 아니라 친숙하기만 하면 된다는 생각에 대한 한 가지 예외는 지연 시간과 그보다 덜한 데이터 대역폭입니다. 계산에 동일한 데이터에 대한 무거운 작업이 수십 번 이상 포함되는 경우(암호화 및 AI에서처럼) 비효율적인 접착 레이어로 인해 발생하는 지연 시간은 런타임에서 주요 병목 현상이 될 수 있습니다. 따라서 접착 레이어에도 효율성 요구 사항이 있지만 이는 더 구체적입니다.
전반적으로, 저는 위에 설명된 추세가 여러 관점에서 매우 긍정적인 발전이라고 생각합니다. 첫째, 개발자 친화적인 상태를 유지하면서 계산 효율성을 극대화하는 합리적인 접근 방식이며, 두 가지 모두를 더 많이 얻을 수 있다는 것은 모든 사람에게 좋습니다. 특히, 효율성을 개선하기 위해 클라이언트 측에서 특수화를 활성화함으로써 사용자 하드웨어에서 로컬로 민감하고 성능이 요구되는 계산(예: ZK 증명, LLM 추론)을 실행하는 능력이 향상됩니다. 둘째, 효율성 추구가 다른 가치, 특히 보안, 개방성 및 단순성을 손상시키지 않도록 보장할 수 있는 엄청난 기회의 창을 만듭니다. 컴퓨터 하드웨어의 사이드 채널 보안 및 개방성, ZK-SNARK의 회로 복잡성 감소, 가상 머신의 복잡성 감소입니다. 역사적으로 효율성 추구는 이러한 다른 요인을 뒤로 미루었습니다. 글루 및 코프로세서 아키텍처를 사용하면 더 이상 그럴 필요가 없습니다. 머신의 한 부분은 효율성을 최적화하고 다른 부분은 일반성과 다른 값을 최적화하며 두 가지는 함께 작동합니다.
이러한 추세는 암호화에도 매우 좋습니다. 암호화 자체가 값비싼 구조화된 계산의 대표적인 예이며, 이러한 추세가 암호화를 가속화하기 때문입니다. 이는 보안을 개선할 수 있는 또 다른 기회를 제공합니다. 블록체인 세계에서도 보안을 개선할 수 있습니다. 가상 머신을 최적화하는 것에 대해 덜 걱정하고 가상 머신과 공존하는 사전 컴파일 및 기타 기능을 최적화하는 데 더 집중할 수 있습니다.
셋째, 이러한 추세는 규모가 작고 새로운 참여자에게 참여할 수 있는 기회를 열어줍니다. 연산이 덜 모놀리식이고 더 모듈화되면 진입 장벽이 크게 낮아집니다. 한 가지 유형의 연산을 사용하는 ASIC조차도 차이를 만들 수 있는 잠재력이 있습니다. 이는 ZK 증명 및 EVM 최적화 분야에서도 마찬가지입니다. 최첨단 효율성으로 코드를 작성하는 것이 더 쉽고 접근하기 쉬워집니다. 이러한 코드를 감사하고 공식적으로 검증하는 것이 더 쉽고 접근하기 쉬워집니다. 마지막으로, 이러한 매우 다른 연산 영역이 몇 가지 공통 패턴으로 수렴되기 때문에 이들 간의 협업과 학습의 여지가 더 커집니다.
이 기사는 인터넷에서 발췌한 것입니다: Vitalik의 새로운 기사: 효율성과 보안을 개선하는 새로운 아이디어인 Glue 및 공동 프로세서 아키텍처
관련: 기술 혁신인가, 과장된 이야기인가? 프랙탈 비트코인의 초기 생태계 살펴보기
원저자: shaofaye 123, Foresight News UniSat 팀이 다시 조치를 취했습니다. Fractal Bitcoin이 시장 붐을 일으켰고 테스트 네트워크의 지갑 주소 수가 1,000만 개를 넘었습니다. Pizza와 Sats가 잇따라 상승했습니다. Bitcoin 생태계의 다음 폭발점일까요 아니면 BSV 2.0일까요? FUD와 FOMO가 공존하며 메인넷이 출시되려고 합니다. 이 글에서는 Fractal Bitcoin의 초기 생태계에 대한 개요를 소개합니다. Fractal Bitcoin 소개 Fractal Bitcoin은 UniSat 팀이 개발한 또 다른 Bitcoin 확장 솔루션입니다. BTC 코어 코드를 사용하여 메인 체인에 무한 확장 계층을 혁신하여 거래 처리 기능과 속도를 개선하는 동시에 기존 Bitcoin 생태계와 완벽하게 호환됩니다. 그…













