My XP
0
Login
原作者: IOSG Ventures
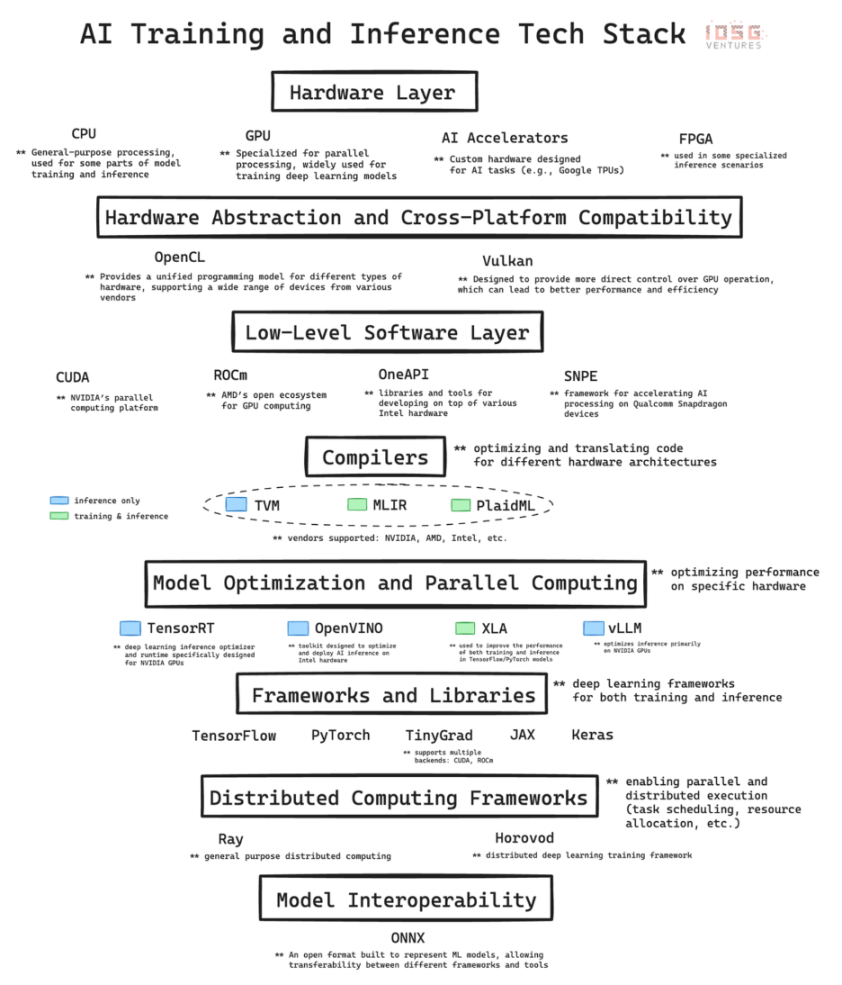
人工知能の急速な発展は、複雑なインフラストラクチャに基づいています。AI テクノロジー スタックは、ハードウェアとソフトウェアで構成される階層型アーキテクチャであり、現在の AI 革命のバックボーンです。ここでは、テクノロジー スタックの主なレイヤーを詳細に分析し、各レイヤーが AI の開発と実装にどのように貢献しているかを説明します。最後に、これらの基本を習得することの重要性について考察します。特に、GPU ネットワークなどの DePIN (分散型物理インフラストラクチャ) プロジェクトなど、暗号通貨と AI の交差点での機会を評価する場合に重要です。
最下層はハードウェアであり、人工知能に物理的な計算能力を提供します。
CPU (中央処理装置): コンピューティングの基本的なプロセッサです。連続タスクの処理に優れており、データの前処理、小規模な人工知能タスク、他のコンポーネントの調整など、一般的なコンピューティングに重要です。
GPU (グラフィックス プロセッシング ユニット): もともとグラフィックス レンダリング用に設計されたものですが、多数の単純な計算を同時に実行できるため、人工知能の重要なコンポーネントになっています。この並列処理機能により、GPU はディープラーニング モデルのトレーニングに最適であり、GPU の開発がなければ、最新の GPT モデルは実現できませんでした。
AI アクセラレータ: 一般的な AI 操作に最適化され、トレーニングと推論の両方のタスクで高いパフォーマンスとエネルギー効率を実現する AI ワークロード専用に設計されたチップ。
FPGA (フィールド プログラマブル アレイ ロジック): 再プログラム可能な性質により柔軟性を提供します。特に低レイテンシを必要とする推論シナリオでは、特定の AI タスクに合わせて最適化できます。
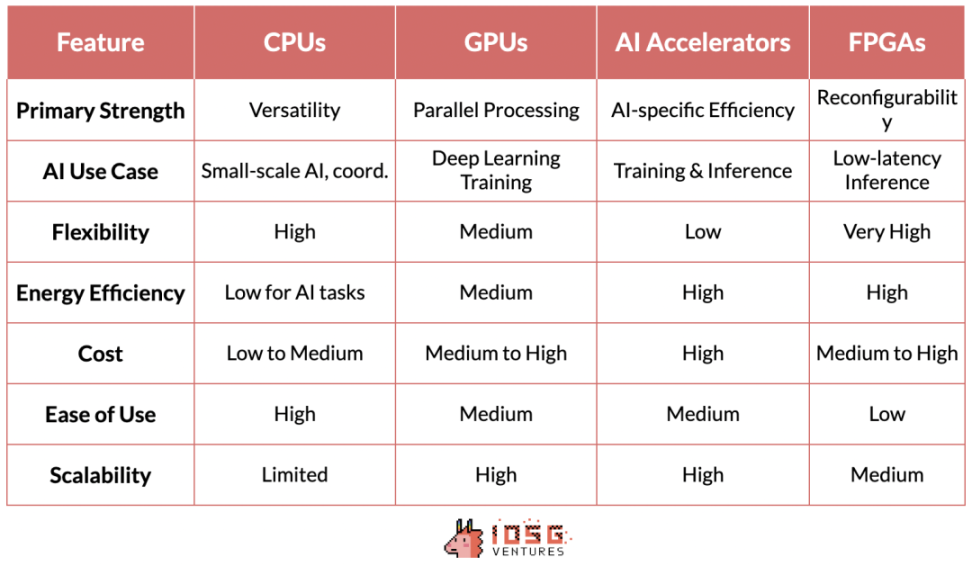
AI テクノロジー スタックのこのレイヤーは、高レベルの AI フレームワークと基盤となるハードウェアの間に橋渡しをするため、非常に重要です。CUDA、ROCm、OneAPI、SNPE などのテクノロジーは、高レベルのフレームワークと特定のハードウェア アーキテクチャ間の接続を強化し、パフォーマンスの最適化を実現します。
CUDA は NVIDIA 独自のソフトウェア レイヤーとして、AI ハードウェア市場における同社の台頭の礎となっています。NVIDIA のリーダーシップはハードウェアの優位性だけでなく、ソフトウェアとエコシステムの統合による強力なネットワーク効果も反映しています。
CUDA がこれほど大きな影響力を持つのは、AI テクノロジー スタックに深く統合され、この分野のデファクト スタンダードとなった最適化されたライブラリ セットを提供しているためです。このソフトウェア エコシステムは強力なネットワーク効果を生み出し、CUDA に精通した AI 研究者や開発者がトレーニング中に学界や産業界にその使用を広めています。
CUDA ベースのツールとライブラリのエコシステムが AI 実践者にとってますます不可欠なものになるにつれ、結果として生じる好循環により NVIDIA の市場リーダーシップが強化されます。
このハードウェアとソフトウェアの共生は、AI コンピューティングの最前線における NVIDIA の地位を強固にするだけでなく、同社に大きな価格決定力も与えます。これは、一般的にコモディティ化されているハードウェア市場では珍しいことです。
CUDA の優位性と競合他社の相対的な無名さは、参入障壁を大きく高めたいくつかの要因に起因しています。NVIDIA は GPU アクセラレーション コンピューティングにおける先駆者としての優位性により、競合他社が足場を築く前に CUDA が強力なエコシステムを構築することができました。AMD や Intel などの競合他社は優れたハードウェアを備えていますが、ソフトウェア レイヤーには必要なライブラリやツールが不足しており、既存のテクノロジ スタックとシームレスに統合できません。そのため、NVIDIA/CUDA と他の競合他社の間には大きなギャップがあります。
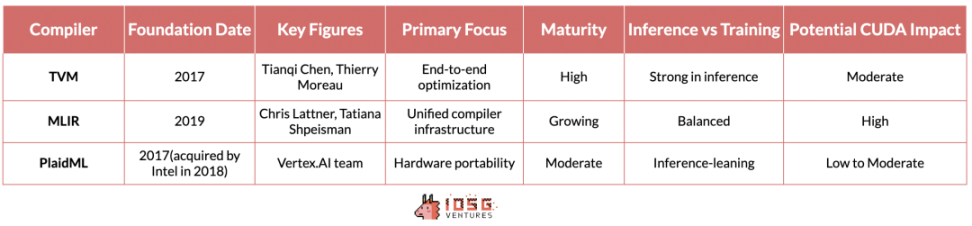
TVM (Tensor Virtual Machine)、MLIR (Multi-Layer Intermediate Representation)、PlaidML は、複数のハードウェア アーキテクチャにわたって AI ワークロードを最適化するという課題に対して、さまざまなソリューションを提供します。
TVM はワシントン大学の研究から生まれ、高性能 GPU からリソースが制限されたエッジ デバイスまで、さまざまなデバイス向けにディープラーニング モデルを最適化できることで急速に注目を集めています。その利点はエンドツーエンドの最適化プロセスにあり、これは推論シナリオで特に効果的です。基盤となるベンダーとハードウェアの違いを完全に抽象化するため、NVIDIA デバイス、AMD、Intel など、さまざまなハードウェア上で推論ワークロードをシームレスに実行できます。
しかし、推論を超えると、状況はより複雑になります。AI トレーニング用のハードウェア交換可能な計算という最終目標は未解決のままです。ただし、この点に関して言及する価値のある取り組みがいくつかあります。
Google のプロジェクトである MLIR は、より根本的なアプローチを採用しています。複数の抽象化レベルに統一された中間表現を提供することで、推論とトレーニングの両方のユースケースのコンパイラ インフラストラクチャ全体を簡素化することを目指しています。
現在インテルが率いる PlaidML は、この競争のダークホースとしての地位を確立しています。同社は、複数のハードウェア アーキテクチャ (従来の AI アクセラレータを超えるものを含む) にわたる移植性に重点を置き、さまざまなコンピューティング プラットフォームで AI ワークロードがシームレスに実行される未来を思い描いています。
これらのコンパイラのいずれかが、モデルのパフォーマンスに影響を与えず、開発者が追加の変更を加える必要もなく、テクノロジー スタックに適切に統合できれば、CUDA の優位性が脅かされる可能性があります。ただし、MLIR と PlaidML はまだ十分に成熟しておらず、AI テクノロジー スタックに適切に統合されていないため、現時点では CUDA のリーダーシップに明確な脅威を与えるものではありません。
Ray と Horovod は、AI 分野における分散コンピューティングに対する 2 つの異なるアプローチを表しており、それぞれが大規模な AI アプリケーションにおけるスケーラブルな処理の主要なニーズに対処しています。
カリフォルニア大学バークレー校の RISELab が開発した Ray は、汎用分散コンピューティング フレームワークです。柔軟性に優れ、機械学習以外にもさまざまなタイプのワークロードを分散できます。Ray のアクター ベース モデルは、Python コードの並列化プロセスを大幅に簡素化するため、強化学習や複雑で多様なワークフローを必要とするその他の人工知能タスクに特に適しています。
Horovod は元々 Uber によって設計され、ディープラーニングの分散実装に重点を置いています。複数の GPU とサーバー ノードにわたってディープラーニングのトレーニング プロセスをスケーリングするための簡潔で効率的なソリューションを提供します。Horovod のハイライトは、そのユーザー フレンドリさと、ニューラル ネットワークのデータ並列トレーニングの最適化です。これにより、TensorFlow や PyTorch などの主流のディープラーニング フレームワークと完全に統合できるため、開発者はコードを大幅に変更することなく、既存のトレーニング コードを簡単にスケーリングできます。
分散コンピューティング システムの構築を目指す DePin プロジェクトにとって、既存の AI スタックとの統合は非常に重要です。この統合により、現在の AI ワークフローおよびツールとの互換性が確保され、導入の障壁が低くなります。
暗号通貨の分野では、現在のGPUネットワークは本質的には分散型GPUレンタルプラットフォームであり、より洗練された分散型AIインフラストラクチャへの第一歩を踏み出したことを示しています。これらのプラットフォームは、Airbnbスタイルのようなものです。 市場分散クラウドとして運用するのではなく、分散コンピューティング プラットフォームとして運用します。一部のアプリケーションには便利ですが、これらのプラットフォームは、大規模な AI 開発を進めるための重要な要件である真の分散トレーニングをサポートするにはまだ不十分です。
Ray や Horovod などの現在の分散コンピューティング標準は、グローバル分散ネットワーク向けに設計されていません。真に機能する分散ネットワークを実現するには、このレイヤーに別のフレームワークを開発する必要があります。懐疑論者の中には、Transformer モデルは学習中にグローバル関数の集中的な通信と最適化を必要とするため、分散トレーニング方法とは互換性がないと考える人もいます。一方、楽観論者は、グローバルに分散されたハードウェアでうまく機能する新しい分散コンピューティング フレームワークを考案しようとしています。Yotta は、この問題を解決しようとしているスタートアップの 1 つです。
NeuroMesh はさらに一歩進んで、機械学習プロセスを特に革新的な方法で再設計します。NeuroMesh は、グローバル損失関数の最適解を直接見つけるのではなく、予測コーディング ネットワーク (PCN) を使用してローカル エラー最小化への収束を見つけることで、分散 AI トレーニングの基本的なボトルネックを解決します。
このアプローチは、これまでにない並列化を可能にするだけでなく、コンシューマーグレードの GPU ハードウェア (RTX 4090 など) でモデルをトレーニングすることも可能になり、AI トレーニングの民主化が実現します。具体的には、4090 GPU は H100 と同等の計算能力を備えていますが、帯域幅が不十分なため、モデル トレーニング中に十分に活用されていません。PCN は帯域幅の重要性を軽減するため、これらのローエンド GPU を活用することが可能になり、大幅なコスト削減と効率性の向上が期待できます。
もう一つの野心的な暗号 AI スタートアップである GenSyn は、コンパイラーのセットを構築することを目指しています。Gensyn のコンパイラーにより、あらゆるタイプのコンピューティング ハードウェアを AI ワークロードにシームレスに使用できるようになります。たとえば、TVM が推論に使用しているのと同じように、GenSyn はモデル トレーニング用の同様のツールを構築しようとしています。
成功すれば、さまざまなハードウェアを効率的に活用することで、分散型 AI コンピューティング ネットワークの機能を大幅に拡張し、より複雑で多様な AI タスクを処理できるようになります。この野心的なビジョンは、多様なハードウェア アーキテクチャ全体にわたる最適化の複雑さと高い技術的リスクのために困難ではありますが、CUDA と NVIDIA がこのビジョンを実行し、異種システムのパフォーマンス維持などの障害を克服できれば、CUDA と NVIDIA の優位性を弱める可能性があります。
推論について: 検証可能な推論と異種コンピューティング リソースの分散ネットワークを組み合わせた Hyperbolics のアプローチは、比較的実用的な戦略を体現しています。TVM などのコンパイラ標準を活用することで、Hyperbolic はパフォーマンスと信頼性を維持しながら、幅広いハードウェア構成を活用できます。コンシューマー グレードのハードウェアや高性能ハードウェアを含む、複数のベンダー (NVIDIA から AMD、Intel など) のチップを集約できます。
暗号と AI の交差点におけるこれらの開発は、AI コンピューティングがより分散化され、効率的で、アクセスしやすくなる未来を予感させます。これらのプロジェクトの成功は、技術的なメリットだけでなく、既存の AI ワークフローとシームレスに統合し、AI 実践者や企業の実際的な懸念に対処する能力にも左右されます。
この記事はインターネットから引用したものです: IOSG Ventures: シリコンからインテリジェンスへ、AIトレーニングと推論技術スタックの詳細な説明
関連: SignalPlus ボラティリティ コラム (20240719): 冷水の盆地
破産したビットコイン取引所Mt.Goxは、過去24時間以内に債権者アカウントへの不正ログインの試みが複数回あったと報告し、債権者は残りの資産の安全性と通貨価格への売り圧力の可能性を懸念している。市場は、この事件が短期的な通貨価格に悪影響を及ぼすことを懸念している可能性がある。過去2日間のETF取引量の急激な減少と相まって、徐々に広がるリスク回避が資産の売りを引き起こし、BTC価格は$64,000を下回り、重要なサポートレベルを再びテストしている。出典:TradingView、Farside Investorsオプションに関しては、全体的なインプライドボラティリティレベルは昨日の急落以来比較的安定しているが、依然として最近の高値にある。注目すべき3つの変化がある。…













