Task
Ranking
已登录
Bee登录
Twitter 授权
TG 授权
Discord 授权
去签到
下一页
关闭
获取登录状态
My XP
0
原作者: ジェーン・ドゥ、チェン・リー
出典: ユービキャピタル
5月23日、半導体大手のNvidiaは2025年度第1四半期の財務報告を発表した。財務報告によると、第1四半期のNvidiaの収益は1兆1000億2600万米ドルだった。そのうち、データセンターの収益は前年比4271兆9000億米ドル増の1兆1000億2260万米ドルと驚異的な数字となった。 米国の株式市場を単独で救うことができるNVIDIAの業績の背景には、AIトラックで競争するために世界のテクノロジー企業の間で爆発的に高まったコンピューティングパワーの需要がある。トップテクノロジー企業がAIトラックのレイアウトに意欲的になればなるほど、コンピューティングパワーの需要は飛躍的に増加している。TrendForcesの予測によると、2024年には、 米国の4大クラウドサービスプロバイダーであるMicrosoft、Google、AWS、MetaのハイエンドAIサーバーの世界需要は、それぞれ20.2%、16.6%、16%、10.8%を占め、合計で60%以上になると予想されています。
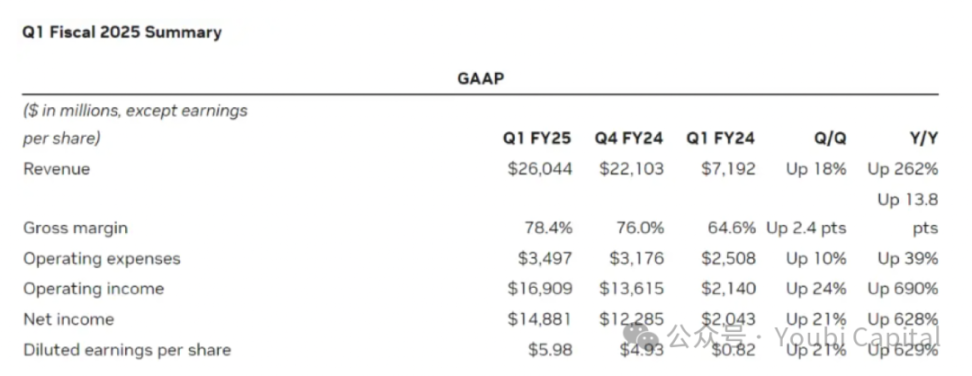
画像出典: https://investor.nvidia.com/financial-info/financial-reports/default.aspx
チップ不足はここ数年、毎年の流行語となっています。一方では、大規模言語モデル (LLM) のトレーニングと推論には大量のコンピューティング パワーのサポートが必要であり、モデルの反復により、コンピューティング パワーのコストと需要は指数関数的に増加します。他方では、Meta のような大企業が膨大な数のチップを購入し、世界のコンピューティング パワー リソースがこれらのテクノロジー大手に偏っているため、中小企業が必要なコンピューティング パワー リソースを入手することがますます困難になっています。 中小企業が直面している困難は、需要の急増によるチップの供給不足だけでなく、供給の構造的な矛盾からも生じています。 現在、供給側には依然として大量のアイドル状態のGPUが存在します。たとえば、一部のデータセンターには大量のアイドル状態のコンピューティングパワー(使用率はわずか12%〜18%)があり、暗号通貨マイニングでも利益の減少により大量のコンピューティングパワーリソースがアイドル状態になっています。 これらのコンピューティング能力は、AI トレーニングなどの専門的なアプリケーション シナリオにすべて適しているわけではありませんが、コンシューマー グレードのハードウェアは、AI 推論、クラウド ゲーム レンダリング、クラウド フォンなどの他の分野で依然として大きな役割を果たすことができます。コンピューティング能力リソースのこの部分を統合して活用する機会は非常に大きいです。
AIから暗号通貨に目を向けると、暗号通貨市場は3年間沈黙していましたが、ついに新たな強気相場が到来しました。ビットコインの価格は新たな高値を記録し、さまざまなミームコインが次々と登場しました。 AIと暗号はここ数年流行語として人気を博していますが、2つの重要な技術としての人工知能とブロックチェーンは2本の平行線のようなものであり、まだ交差点を見つけていません。 今年初め、ヴィタリックは「暗号+AIアプリケーションの将来性と課題」と題する記事を発表し、AIと暗号の組み合わせの将来シナリオについて議論しました。ヴィタリックは記事の中で、ブロックチェーンやMPCなどの暗号化技術を使用してAIのトレーニングと推論を分散化し、機械学習のブラックボックスを開き、AIモデルをより信頼できないものにするなど、多くのビジョンについて言及しました。これらのビジョンを実現するにはまだ長い道のりがあります。 しかし、ヴィタリック氏が挙げたユースケースの 1 つ、つまり暗号通貨の経済的インセンティブを利用して AI を強化するという方法も、短期間で実現できる重要な方向性です。分散型コンピューティング パワー ネットワークは、現段階で AI + 暗号通貨に最も適したシナリオの 1 つです。
現在、分散コンピューティング パワー ネットワークの分野では、すでに多くのプロジェクトが開発されています。これらのプロジェクトの基本的なロジックは似ており、次のように要約できます。 トークンを使用して、コンピューティングパワー保有者にネットワークに参加してコンピューティングパワーサービスを提供するようにインセンティブを与え、これらの分散したコンピューティングパワーリソースを一定規模の分散型コンピューティングパワーネットワークに集約することができます。これにより、アイドル状態のコンピューティングパワーの利用率が向上するだけでなく、より低コストで顧客のコンピューティングパワーのニーズを満たすことができ、買い手と売り手の双方にメリットをもたらします。
読者が短期間でこのトラックの全体像を理解できるように、この記事では、特定のプロジェクトとトラック全体をミクロとマクロの2つの視点から分解し、各プロジェクトの中核となる競争優位性と分散コンピューティングパワートラックの全体的な発展を理解するための分析的視点を読者に提供することを目的としています。著者は、次の5つのプロジェクトを紹介し、分析します。 Aethir、io.net、レンダー ネットワーク、Akash ネットワーク、Gensyn プロジェクトの状況を要約・評価し、進捗状況を追跡します。
分析フレームワークの観点から、特定の分散コンピューティング ネットワークに焦点を当てると、それを 4 つのコア コンポーネントに分解できます。
ハードウェアネットワーク : 分散型コンピューティングネットワークの基本層であり、世界中に分散したノードを通じて分散されたコンピューティングリソースを統合し、コンピューティングリソースの共有と負荷分散を実現します。
両面市場 : 合理的な価格設定と検出メカニズムを通じてコンピューティング パワー プロバイダーと需要者をマッチングし、安全な取引プラットフォームを提供し、供給側と需要側の間の取引が透明で公正かつ信頼できるものであることを保証します。
合意メカニズム : ネットワーク内のノードが正しく動作し、作業を完了することを保証するために使用されます。コンセンサス メカニズムは、主に 2 つのレベルを監視するために使用されます。1) ノードがオンラインで、いつでもタスクを受け入れることができるアクティブな状態にあるかどうかを監視します。2) ノード作業証明: ノードはタスクを受信した後、タスクを効果的かつ正しく完了し、計算能力が他の目的に使用され、プロセスとスレッドを占有しません。
トークンインセンティブ : トークン モデルは、より多くの参加者にサービスを提供/使用するようインセンティブを与えるために使用され、トークンを使用してこのネットワーク効果を獲得し、コミュニティの利益共有を実現します。
分散コンピューティングパワートラック全体を俯瞰すると、Blockworks Research の調査レポートは優れた分析フレームワークを提供します。このトラックのプロジェクトの位置付けは、3 つの異なるレイヤーに分けることができます。
ベアメタル層 : 分散コンピューティング スタックの基本レイヤー。主なタスクは、生のコンピューティング リソースを収集し、API 呼び出しに使用できるようにすることです。
オーケストレーション層 : 分散コンピューティング スタックの中間層。主なタスクは調整と抽象化です。コンピューティング能力のスケジュール、拡張、操作、負荷分散、フォールト トレランスを担当します。主な機能は、基盤となるハードウェア管理の複雑さを抽象化し、エンド ユーザーが特定の顧客グループに対応できるように、より高度なユーザー インターフェイスを提供することです。
集約レイヤー : 分散コンピューティング スタックの最上位層を構成します。主なタスクは統合です。AI トレーニング、レンダリング、zkML など、ユーザーが複数のコンピューティング タスクを 1 か所で実装できるように、統一されたインターフェイスを提供する役割を担います。複数の分散コンピューティング サービスのオーケストレーションおよび配布層に相当します。
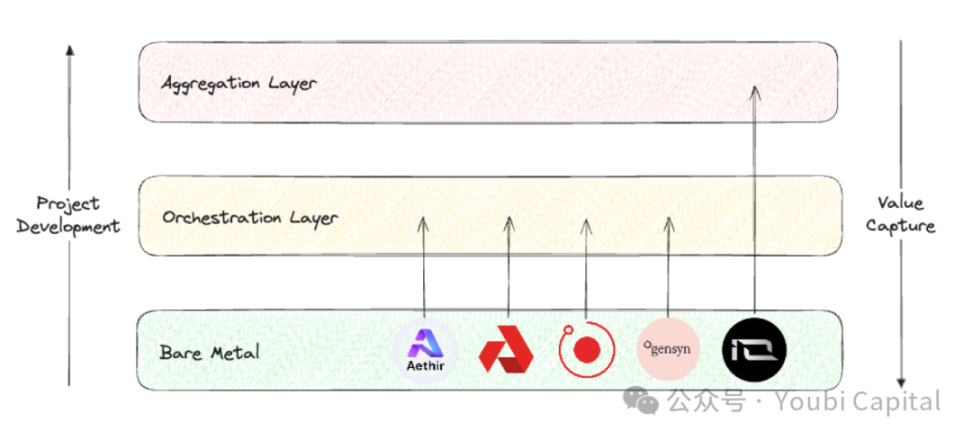
画像出典: Youbi Capital
上記 2 つの分析フレームワークに基づいて、選択した 5 つのプロジェクトを水平比較し、次の 4 つのレベルで評価します。 コアビジネス、市場ポジショニング、ハードウェア設備、財務実績 .
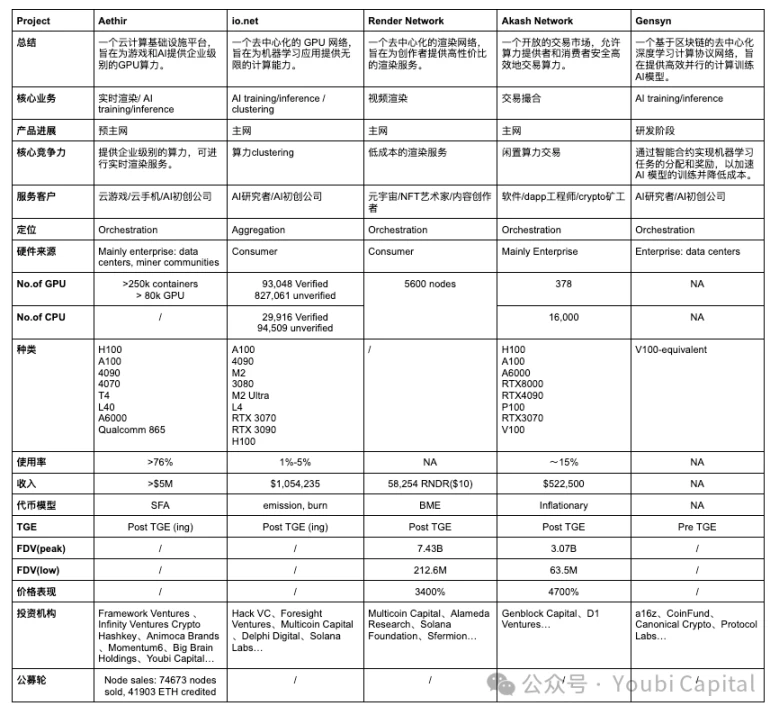
基礎となるロジックから、分散コンピューティング ネットワークは高度に均質化されており、つまり、トークンを使用して、アイドル状態のコンピューティング パワーの所有者にコンピューティング パワー サービスを提供するようインセンティブを与えます。この基礎となるロジックに基づいて、プロジェクトのコア ビジネスの違いを 3 つの側面から理解できます。
アイドル状態のコンピューティングパワーのソース:
市場における未使用のコンピューティング パワーの主な発生源は 2 つあります。1) データ センター、マイナー、その他の企業の手元にある未使用のコンピューティング パワー、2) 個人投資家の手元にある未使用のコンピューティング パワーです。データ センターのコンピューティング パワーは通常、プロ仕様のハードウェアですが、個人投資家は通常、消費者向けグレードのチップを購入します。
Aethir、Akash Network、Gensyn の計算能力は主に企業から収集されます。 企業からコンピューティングパワーを収集する利点は次のとおりです。1)企業とデータセンターは通常、高品質のハードウェアと専門的なメンテナンスチームを備えており、コンピューティングパワーリソースのパフォーマンスと信頼性が高くなります。2)企業とデータセンターのコンピューティングパワーリソースはより均質であることが多く、集中管理と監視により、リソースのスケジュールとメンテナンスがより効率的になります。ただし、それに応じて、この方法はプロジェクト当事者に対する要件が高く、プロジェクト当事者はコンピューティングパワーを管理する企業との商業的なつながりを持つ必要があります。同時に、スケーラビリティと分散化はある程度影響を受けます。
Render Network と io.net は主に、個人投資家に未使用のコンピューティング能力を提供することを奨励しています。 個人投資家からコンピューティングパワーを集めることの利点は、1) 個人投資家のアイドルコンピューティングパワーの明示的なコストが低いため、より経済的なコンピューティングパワーリソースを提供できることです。2) ネットワークはよりスケーラブルで分散化されているため、システムの弾力性と堅牢性が向上します。欠点は、小売リソースが広く分散されており、均一ではないため、管理とスケジュールが複雑になり、運用と保守の難易度が増すことです。また、小売コンピューティングパワーに頼ることで、初期のネットワーク効果を形成するのがより困難になります (キックスタートが困難)。最後に、小売デバイスはセキュリティリスクが高くなる可能性があり、データ漏洩やコンピューティングパワーの乱用のリスクをもたらします。
コンピューティングパワーの消費者
コンピューティングパワーの消費者の観点から見ると、Aethir、io.net、Gensyn のターゲット顧客は主に企業です。 B サイドの顧客にとって、AI やゲームのリアルタイム レンダリングには、高性能コンピューティングのニーズが必要です。このタイプのワークロードは、コンピューティング パワー リソースに対する要件が非常に高く、通常はハイエンド GPU またはプロ仕様のハードウェアが必要です。また、B サイドの顧客はコンピューティング パワー リソースの安定性と信頼性に対する要件が高いため、プロジェクトの正常な動作を確保し、タイムリーな技術サポートを提供するために、高品質のサービス レベル契約を提供する必要があります。同時に、B サイドの顧客の移行コストは非常に高くなります。分散型ネットワークに、プロジェクト側が迅速に展開できる成熟した SDK がない場合 (たとえば、Akash Network では、ユーザーがリモート ポートに基づいて自分で開発する必要があります)、顧客が移行するのは困難です。非常に大きな価格優位性がなければ、顧客の移行意欲は非常に低くなります。
Render Network と Akash Network は主に個人投資家向けにコンピューティング パワー サービスを提供しています。 C エンド ユーザーにサービスを提供するには、プロジェクトはシンプルで使いやすいインターフェイスとツールを設計し、消費者に優れた消費者エクスペリエンスを提供する必要があります。消費者は価格にも非常に敏感なので、プロジェクトは競争力のある価格を提供する必要があります。
ハードウェアタイプ
一般的なコンピューティング ハードウェア リソースには、CPU、FPGA、GPU、ASIC、SoC などがあります。これらのハードウェアは、設計目標、パフォーマンス特性、アプリケーション領域に大きな違いがあります。まとめると、CPU は一般的なコンピューティング タスクに適しており、FPGA の利点は高度な並列処理とプログラミング性、GPU は並列コンピューティングで優れたパフォーマンスを発揮し、ASIC は特定のタスクで最も効率的であり、SoC は複数の機能を 1 つに統合し、高度に統合されたアプリケーションに適しています。どのハードウェアを選択するかは、特定のアプリケーションのニーズ、パフォーマンス要件、コストの考慮事項によって異なります。 私たちが議論した分散コンピューティングパワープロジェクトは、主にGPUコンピューティングパワーを収集するためのもので、プロジェクトのビジネスタイプとGPUの特性によって決まります。GPUは、AIトレーニング、並列コンピューティング、マルチメディアレンダリングなどの面で独自の利点を持っているためです。
これらのプロジェクトのほとんどには GPU 統合が含まれますが、アプリケーションによってハードウェア仕様の要件が異なるため、これらのハードウェアには異種の最適化コアとパラメーターがあります。 これらのパラメータには、並列/シリアル依存関係、メモリ、レイテンシなどが含まれます。たとえば、レンダリングワークロードは、実際にはより強力なデータセンターGPUよりもコンシューマーグレードのGPUの方が適しています。レンダリングにはレイトレーシングに対する高い要件があり、4090などのコンシューマーグレードのチップには強化されたRTコアがあり、レイトレーシングタスクに特化して最適化されているためです。AIのトレーニングと推論には、プロレベルのGPUが必要です。そのため、Render Networkは個人投資家からRTX 3090や4090などのコンシューマーグレードのGPUを集めることができますが、IO.NETはAIスタートアップのニーズを満たすために、H 100やA 100などのプロレベルのGPUをさらに必要としています。
プロジェクトの位置付けに関して言えば、ベアメタル層、オーケストレーション層、集約層には、解決すべき中核的な問題、最適化の焦点、価値獲得機能がそれぞれ異なります。
ベアメタル層は物理リソースの収集と利用に重点を置いていますが、オーケストレーション層はコンピューティング能力のスケジューリングと最適化に重点を置いており、顧客グループのニーズに応じて物理ハードウェアの設計を最適化しています。アグリゲーション層は汎用性が高く、さまざまなリソースの統合と抽象化に重点を置いています。バリューチェーンの観点から、各プロジェクトはベアメタル層から開始し、上に向かって進むように努めるべきです。
価値獲得の観点から見ると、ベアメタル層、オーケストレーション層から集約層まで、価値獲得能力は層ごとに高まります。 集約層は、最大のネットワーク効果を獲得し、分散型ネットワークのトラフィックの入り口に相当する最も多くのユーザーに直接到達できるため、最大の価値を獲得でき、コンピューティング リソース管理スタック全体で最も高い価値獲得の位置を占めます。
それに応じて、集約プラットフォームの構築は最も困難です。プロジェクトでは、技術的な複雑さ、異種リソースの管理、システムの信頼性と拡張性、ネットワーク効果の実現、セキュリティとプライバシーの保護、複雑な運用と保守管理など、多くの問題を総合的に解決する必要があります。これらの課題は、プロジェクトのコールドスタートには役立たず、トラックの開発とタイミングに依存します。 オーケストレーション層が成熟し、一定の市場シェアを占める前に集約層を構築するのは現実的ではありません。
現在、 Aethir、Render Network、Akash Network、Gensyn はすべてオーケストレーション層に属し、特定のターゲットと顧客グループにサービスを提供するように設計されています。 Aethirの現在の主な業務はクラウドゲームのリアルタイムレンダリングであり、Bサイドの顧客に特定の開発および展開環境とツールを提供しています。Render Networksの主な業務はビデオレンダリングであり、Akash Networksの使命はTaobaoに似た取引プラットフォームを提供することであり、GensynはAIトレーニングの分野に深く関わっています。io.netはアグリゲーションレイヤーとして位置付けられていますが、ioが現在実装している機能は、アグリゲーションレイヤーの完全な機能からはまだ遠いです。Render NetworkとFilecoinのハードウェアは収集されていますが、ハードウェアリソースの抽象化と統合はまだ完了していません。
現在、すべてのプロジェクトが詳細なネットワークデータを公開しているわけではありません。相対的に言えば、io.netエクスプローラーのUIは最も優れており、GPU / CPUの数、タイプ、価格、分布、ネットワーク使用量、ノード収入などのパラメータを確認できます。しかし、4月末にio.netのフロントエンドが攻撃を受けました。ioはPUT / POSTインターフェースでAuthを実行しなかったため、ハッカーがフロントエンドデータを改ざんしました。これにより、他のプロジェクトのプライバシーとネットワークデータの信頼性にも警鐘が鳴らされました。
GPUの数とモデルから見ると、集約層としてのio.netが最も多くのハードウェアを収集しているはずです。Aethirがすぐ後に続き、他のプロジェクトのハードウェア状況はそれほど透明ではありません。GPUモデルから、ioにはA 100などのプログレードのGPUと4090などのコンシューマーグレードのGPUの両方があり、種類が豊富で、io.net集約の位置付けと一致していることがわかります。ioは、特定のタスク要件に応じて最も適切なGPUを選択できます。ただし、モデルやブランドが異なるGPUでは、必要なドライバーや構成が異なる場合があります。また、ソフトウェアも複雑に最適化する必要があり、管理とメンテナンスの複雑さが増します。現在、ioでのさまざまなタスクの割り当ては、主にユーザーの選択に基づいています。
Aethirは自社のマイニングマシンをリリースしました。5月には、Qualcommの支援を受けて開発されたAethir Edgeが正式に発売されました。これは、ユーザーから遠く離れた単一の集中型GPUクラスター展開モードを打ち破り、エッジにコンピューティングパワーを展開します。Aethir Edgeは、H100のクラスターコンピューティングパワーを組み合わせてAIシナリオに対応します。トレーニング済みモデルを展開し、ユーザーに最良のコストで推論コンピューティングサービスを提供できます。このソリューションは、ユーザーに近く、より高速なサービスを提供し、よりコスト効率に優れています。
需要と供給の観点から、Akash Network を例にとると、その統計によると、CPU の総数は約 16k、GPU の数は 378 です。ネットワークのレンタル需要によると、CPU と GPU の使用率はそれぞれ 11.1% と 19.3% です。 その中で、プログレードのGPU H 100だけが比較的レンタル率が高く、他のモデルはほとんどがアイドル状態です。他のネットワークが直面している状況は、Akashとほぼ同じです。ネットワーク全体の需要は高くありません。A 100やH 100などの人気チップを除いて、他のコンピューティングパワーはほとんどアイドル状態です。
価格優位性の観点から見ると、クラウド コンピューティング市場の大手企業を除いて、他の従来のサービス プロバイダーと比較してコスト優位性は顕著ではありません。

トークン モデルの設計方法に関係なく、健全なトークノミクスは次の基本条件を満たす必要があります。1) ネットワークに対するユーザーの需要がコイン価格に反映される必要があります。つまり、トークンが価値を獲得できるということです。2) 開発者、ノード、ユーザーなど、すべての参加者が長期的かつ公正なインセンティブを受け取る必要があります。3) インサイダーによる過剰な保有を避けるために、分散型ガバナンスを確保する必要があります。4) ネットワークの堅牢性と持続可能性に影響を与えるコイン価格の大きな変動を避けるために、合理的なインフレとデフレのメカニズムとトークンのリリース サイクルが必要です。
トークンモデルを一般的にBME(バーンアンドミント均衡)とSFA(アクセスのためのステーク)に分けると、これら2つのモデルのトークンに対するデフレ圧力の源は異なります。BMEモデルは、ユーザーがサービスを購入した後にトークンをバーンするため、システムのデフレ圧力は需要によって決まります。SFAでは、サービスプロバイダー/ノードがサービスを提供する資格を得るためにトークンをステークする必要があるため、デフレ圧力は供給によってもたらされます。BMEの利点は、非標準化された商品に適していることです。ただし、ネットワークの需要が不十分な場合は、継続的なインフレの圧力に直面する可能性があります。さまざまなプロジェクトのトークンモデルは詳細が異なりますが、一般的には、 Aethir は SFA を好みますが、io.net、Render Network、Akash Network は BME を好み、Gensyn はまだ不明です。
収益の観点から見ると、ネットワークの需要はネットワーク全体の収益に直接反映されます(マイナーの収益についてはここでは説明しません。マイナーはタスク完了の報酬に加えてプロジェクトから補助金を受け取るためです)。公開データによると、io.net の収益が最も高いです。Aethir の収益はまだ発表されていませんが、公開情報によると、多くの B サイド顧客との注文を締結したことを発表しています。
コイン価格に関しては、Render NetworkとAkash NetworkのみがICOを実施しています。Aethirとio.netも最近コインを発行しており、その価格パフォーマンスを観察する必要があるため、ここでは詳細には触れません。Gensynsの計画はまだ不明です。コインを発行した2つのプロジェクトと、同じトラックでコインを発行したがこの記事の範囲には含まれていないプロジェクトから、 一般的に、分散型コンピューティング パワー ネットワークの価格パフォーマンスは非常に優れており、これはある程度、巨大な市場の可能性とコミュニティの高い期待を反映しています。
分散コンピューティングネットワークトラックは全体的に急速に発展しており、多くのプロジェクトはすでに製品に依存して顧客にサービスを提供し、一定の収入を生み出しています。このトラックは純粋な物語から脱却し、予備的なサービスを提供できる開発段階に入りました。
需要の弱さは分散型コンピューティング ネットワークが直面する一般的な問題であり、長期的な顧客需要は十分に検証および調査されていません。ただし、需要側はコインの価格にそれほど影響を与えておらず、すでにコインを発行しているいくつかのプロジェクトは好調に推移しています。
AI は分散コンピューティング ネットワークの主な話題ですが、唯一のビジネスではありません。AI のトレーニングや推論に使用されるだけでなく、コンピューティング パワーはクラウド ゲーム、クラウド モバイル フォン サービスなどのリアルタイム レンダリングにも使用できます。
コンピューティング パワー ネットワークのハードウェアの異種性は比較的高く、コンピューティング パワー ネットワークの品質と規模をさらに向上させる必要があります。
Cエンドユーザーにとって、コストの優位性はあまり明らかではありません。Bエンドユーザーの場合、コスト削減に加えて、サービスの安定性、信頼性、技術サポート、コンプライアンス、法的サポートなども考慮する必要があり、Web3プロジェクトは一般的にこれらの面でうまく機能していません。
AIの爆発的な成長により、コンピューティングパワーに対する需要が急増しています。2012年以降、AIトレーニングタスクで使用されるコンピューティングパワーは飛躍的に成長しており、現在は3.5か月ごとに2倍になっています(ムーアの法則では18か月ごとに2倍になります)。2012年以降、コンピューティングパワーの需要は30万倍以上増加し、ムーアの法則の12倍の成長をはるかに上回っています。予測によると、GPU市場は今後5年間で年間32%の複合成長率で成長し、$2000億を超えると予想されています。AMDの見積もりはさらに高く、同社はGPUチップ市場が2027年までに$4000億に達すると予想しています。

画像出典: https://www.stateof.ai/
人工知能やその他の計算集約型ワークロード(AR / VRレンダリングなど)の爆発的な成長により、従来のクラウドコンピューティングと主要なコンピューティング市場の構造的な非効率性が明らかになったためです。理論的には、分散型コンピューティングネットワークは、分散されたアイドルコンピューティングリソースを利用することで、より柔軟で低コストで効率的なソリューションを提供でき、それによって市場のコンピューティングリソースに対する膨大な需要を満たすことができます。したがって、暗号とAIの組み合わせは大きな市場の可能性を秘めていますが、従来の企業との激しい競争、高い参入障壁、複雑な市場環境にも直面しています。 一般的に、すべての暗号通貨の分野を見ると、分散型コンピューティング ネットワークは、実際のニーズを満たすことができる暗号通貨分野で最も有望な分野の 1 つです。
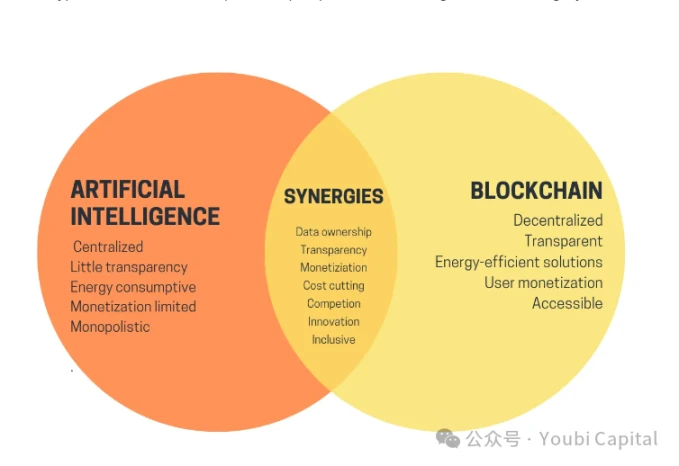
画像ソース : https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
未来は明るいですが、道のりは険しいです。上記のビジョンを実現するには、まだ多くの問題と課題を解決する必要があります。要約すると、 現段階では、従来のクラウドサービスのみを提供する場合、プロジェクトの利益率は非常に小さいです。需要側から見ると、大企業は一般的に独自のコンピューティングパワーを構築し、純粋なCエンド開発者は主にクラウドサービスを選択します。分散コンピューティングパワーネットワークリソースを真に使用する中小企業が安定した需要を持つかどうかは、さらに調査と検証が必要です。一方、AIは上限と想像力のスペースが非常に高い広大な市場です。より広い市場のために、分散コンピューティングパワーサービスプロバイダーも、将来的にモデル/ AIサービスに転換し、より多くの暗号+ AIの使用シナリオを模索し、プロジェクトが生み出す価値を拡大する必要があります。しかし、現時点では、AI分野へのさらなる発展にはまだ多くの問題と課題があります。
価格優位性は目立たない : これまでのデータ比較から、分散型コンピューティングネットワークのコスト優位性が反映されていないことがわかります。考えられる理由は、需要の高いH100やA100などの専門チップの場合、市場メカニズムにより、この部分のハードウェアの価格は安くならないと判断されるためです。また、分散型ネットワークはアイドル状態のコンピューティングリソースを収集できますが、分散化によってもたらされる規模の経済性の欠如、高いネットワークおよび帯域幅コスト、および非常に複雑な管理と運用とメンテナンスにより、コンピューティングコストがさらに増加します。
AIトレーニングの特殊性 : 分散型AIトレーニングの現段階では、大きな技術的ボトルネックがあります。このボトルネックは、GPUワークフローに直感的に反映されています。大規模言語モデルのトレーニングでは、GPUはまず前処理済みのデータバッチを受け取り、順方向伝播と逆方向伝播の計算を行って勾配を生成します。次に、各GPUは勾配を集約し、モデルパラメータを更新して、すべてのGPUが同期されるようにします。このプロセスは、すべてのトレーニングバッチが完了するか、所定のラウンド数に達するまで繰り返されます。このプロセスには、大量のデータ転送と同期が伴います。どのような並列および同期戦略を使用するか、ネットワーク帯域幅とレイテンシをどのように最適化し、通信コストを削減するかなど、まだ十分な答えが得られていません。現段階では、分散型コンピューティングパワーネットワークを使用してAIをトレーニングすることはあまり現実的ではありません。
データのセキュリティとプライバシー : 大規模言語モデルのトレーニング中、データ配布、モデルトレーニング、パラメータと勾配の集約など、データ処理と転送のあらゆる側面がデータのセキュリティとプライバシーに影響を与える可能性があります。また、データのプライバシーはモデルのプライバシーよりも重要です。データプライバシーの問題を解決できない場合、需要側で真のスケールアップを行うことはできません。
最も現実的な観点から、分散型コンピューティングネットワークは、現在の需要の発見と将来の市場スペースの両方を考慮する必要があります。まずは非AIまたはWeb3ネイティブプロジェクトをターゲットにし、比較的限界的なニーズから始めて、早期のユーザーベースを構築するなど、適切な製品の位置付けとターゲット顧客グループを見つけます。同時に、AIと暗号を組み合わせたさまざまなシナリオを模索し続け、テクノロジーの最前線を探求し、サービスの変革とアップグレードを実現します。
参考文献
https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
https://foresightnews.pro/article/detail/34368
https://research.web3 caff.com/zh/archives/17351?ref=1554
この記事はインターネットから引用したものです: エッジで生まれる: 分散型コンピューティング パワー ネットワークは、どのように暗号通貨と AI を強化するのでしょうか?
関連: 4月に数十億の柴犬(SHIB)トークンが誤って焼却された
概要 4 月に 16 億 9000 万枚の Shiba Inu (SHIB) トークンがバーンされました。バーンは偶発的なもので、価格に影響を及ぼす可能性があります。市場は強気トレンドの可能性を示唆するさまざまなシグナルを示しています。 Shiba Inu (SHIB) コミュニティは、4 月中に約 16 億 9000 万枚の SHIB トークンがバーンされたことを確認しました。これは 204 件のトランザクションに分散されています。利用可能な Shiba Inu トークンのこの大幅な減少は、戦略的な市場操作の結果ではなく、やや偶発的な転送の結果であり、Shiba Inu の価格に重大な影響を与える可能性があります。 16 億 9000 万枚の SHIB バーンに対する市場の反応 ShibBurn によると、トークン バーンの急増は、主にユーザーが誤って SHIB をコントラクト アドレスに送信したためです。「これは、多くの人が報告したような大きなニュースや何かによるものではありません。人々がミスを犯し、トークンを CA に送信し、投資を失っただけです。注意して…













