My XP
0
Login
Original title: Possible futures of the Ethereum protocol, part 6: The Splurge
Original article by @VitalikButerin
मूल अनुवाद: झोउझोउ, ब्लॉकबीट्स
मूल सामग्री निम्नलिखित है (पढ़ने और समझने में आसानी के लिए मूल सामग्री को पुनर्गठित किया गया है):
Some things are hard to put into a single category, and in Ethereum protocol design, there are many details that are very important to Ethereums success. In fact, about half of the content involves different types of EVM improvements, and the rest is made up of various niche topics. This is what flourish means.

Roadmap 2023: Prosperity
Prosperity: A key goal
Bringing the EVM to a high-performance and stable final state
Introducing account abstraction into the protocol, allowing all users to enjoy more secure and convenient accounts
Optimizing transaction fee economics, increasing scalability while reducing risk
Exploring advanced क्रिप्टोgraphy to significantly improve Ethereum in the long term
In this chapter
VDF (Verifiable Delay Function)
Obfuscation and one-time signatures: the future of cryptography
The current EVM is difficult to statically analyze, which makes it difficult to create efficient implementations, formally verify code, and make further extensions. In addition, the EVM is inefficient and difficult to implement many forms of advanced cryptography unless explicitly supported by precompilation.
The first step in the current EVM improvement roadmap is the EVM Object Format (EOF), scheduled for inclusion in the next hard fork. EOF is a series of EIPs that specifies a new EVM code version with a number of unique features, most notably:
Separation between code (which can be executed but cannot be read from the EVM) and data (which can be read but cannot be executed)
Dynamic jumps are prohibited, only static jumps are allowed
EVM code can no longer observe fuel related information
Added a new explicit subroutine mechanism

Structure of EOF code
Old-style contracts will continue to exist and can be created, though they will likely eventually be phased out (perhaps even forced to convert to EOF code). New-style contracts will benefit from the efficiency gains brought by EOF – first in slightly smaller bytecode via the subroutine feature, and later in the form of new EOF-specific functionality or reduced gas costs.
After the introduction of EOF, further upgrades became easier, and the most developed one at present is the EVM Modular Arithmetic Extension (EVM-MAX) . EVM-MAX creates a new set of operations specifically for modular operations and places them in a new memory space that cannot be accessed by other opcodes, which makes it possible to use optimizations such as Montgomery multiplication .
A newer idea is to combine EVM-MAX with the Single Instruction Multiple Data (SIMD) feature. SIMD has been around for a long time as an Ethereum concept, first proposed by Greg Colvins EIP-616 . SIMD can be used to accelerate many forms of cryptography, including hash functions, 32-bit STARKs, and lattice-based cryptography. The combination of EVM-MAX and SIMD makes these two performance-oriented extensions a natural pairing.
A rough design for a combined EIP would start with EIP-6690, then:
Allows (i) any odd number or (ii) any power of 2 up to 2768 as a modulus
For each EVM-MAX opcode (addition, subtraction, multiplication), add a version that uses 7 immediates instead of 3 x, y, z: x_start, x_skip, y_start, y_skip, z_start, z_skip, count. In Python code, these opcodes work like this:
for i in range(count):
mem[z_start + z_skip * count] = op(
mem[x_start + x_skip * count],
mem[y_start + y_skip * count]
)
In actual implementation, this will be handled in parallel.
Possibly adding XOR, AND, OR, NOT, and SHIFT (both looping and non-looping), at least for modulos of powers of 2. Also adding ISZERO (pushing output to the EVM main stack), which will be powerful enough to implement elliptic curve cryptography, small domain cryptography (like Poseidon, Circle STARKs), traditional hash functions (like SHA 256, KECCAK, BLAKE), and lattice-based cryptography. Other EVM upgrades are also possible, but have received less attention so far.
EOF: https://evmobjectformat.org/
EVM-MAX: https://eips.ethereum.org/EIPS/eip-6690
SIMD: https://eips.ethereum.org/EIPS/eip-616
Currently, EOF is scheduled to be included in the next hard fork. While it is always possible to remove it at the last minute – features have been temporarily removed in previous hard forks, doing so would be very challenging. Removing EOF means that any future upgrades to the EVM will need to be done without EOF, which is possible but may be more difficult.
The main trade-off of the EVM is L1 complexity vs. infrastructure complexity. EOF is a large amount of code that needs to be added to the EVM implementation, and static code checking is relatively complex. However, in exchange, we can simplify the high-level language, simplify the EVM implementation, and other benefits. It can be said that the roadmap that prioritizes the continued improvement of Ethereum L1 should include and build on EOF.
An important work that needs to be done is to implement something like EVM-MAX plus SIMD functionality and benchmark the gas consumption of various crypto operations.
L1 adjusts its EVM so that L2 can adjust accordingly more easily. If the two are not adjusted synchronously, it may cause incompatibility and adverse effects. In addition, EVM-MAX and SIMD can reduce the gas cost of many proof systems, making L2 more efficient. It also makes it easier to replace more precompilations with EVM code that can perform the same tasks, possibly without greatly affecting efficiency.
Currently, transactions can only be verified in one way: ECDSA signatures. Initially, account abstraction aims to go beyond this, allowing the verification logic of an account to be arbitrary EVM code. This can enable a range of applications:
Switching to quantum-resistant cryptography
Rotate old keys (widely considered a recommended security practice )
Multi-signature wallets and social recovery wallets
Use one key for low-value operations and another key (or set of keys) for high-value operations
Allows privacy protocols to work without relays, significantly reducing their complexity and removing a key central point of dependency
Since account abstraction was proposed in 2015, its goals have also expanded to include a large number of convenience goals, such as an account that does not have ETH but has some ERC 20 being able to pay gas with ERC 20. Here is a summary chart of these goals:
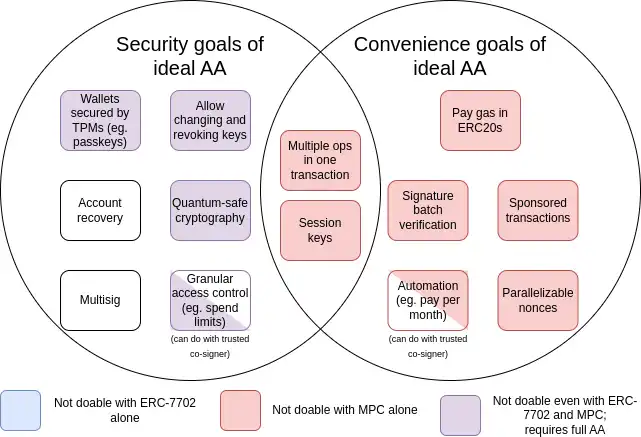
MPC (Multi-Party Computation) is a 40-year-old technology for splitting a key into multiple parts and storing them on multiple devices, using cryptographic techniques to generate signatures without directly combining those key parts.
ईआईपी-7702 is a proposal planned to be introduced in the next hard fork. EIP-7702 is the result of a growing awareness of the need to provide account abstraction convenience to benefit all users (including EOA users). It aims to improve the experience of all users in the short term and avoid splitting into two ecosystems.
The work started with EIP-3074 and eventually formed EIP-7702. EIP-7702 provides the convenience features of account abstraction to all users, including todays EOAs (externally owned accounts, i.e. accounts controlled by ECDSA signatures).
As you can see from the chart, while some challenges (especially the convenience challenge) can be solved through progressive techniques such as multi-party computation or EIP-7702, the main security goal of the original account abstraction proposal can only be achieved by backtracking and solving the original problem: allowing smart contract code to control transaction verification. The reason this has not been achieved so far is that it is challenging to implement securely.
The core of the account abstraction is simple: allow smart contracts to initiate transactions, not just EOAs. The entire complexity comes from implementing this in a way that is friendly to maintaining a decentralized network and protecting against denial of service attacks.
A typical key challenge is the multiple failure problem:
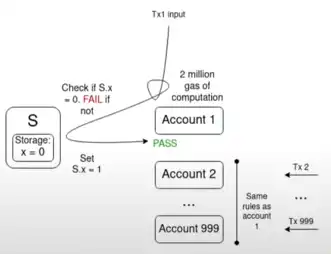
If there are 1,000 accounts whose validation functions all rely on a single value S, and the current value of S makes all transactions in the memory pool valid, then a single transaction that flips the value of S may invalidate all other transactions in the memory pool. This allows attackers to send junk transactions to the memory pool at a very low cost, thereby clogging up the resources of network nodes.
After years of hard work aimed at expanding functionality while limiting denial of service (DoS) risks, a solution to achieve ideal account abstraction was finally arrived at: ERC-4337.
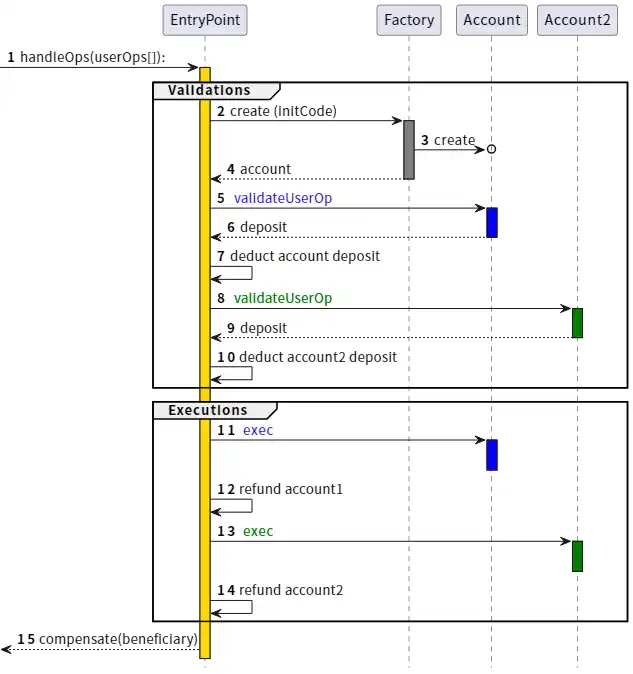
ERC-4337 works by dividing the processing of user actions into two phases: verification and execution. All verifications are processed first, and all executions are processed afterwards. In the memory pool, user actions are accepted only if the verification phase only involves their own account and does not read environment variables. This prevents multiple invalidation attacks. In addition, strict gas limits are also enforced on the verification step.
ERC-4337 was designed as an additional protocol standard (ERC) because at the time Ethereum client developers were focused on merging (Merge) and had no extra energy to handle other features. Thats why ERC-4337 uses objects called user actions instead of regular transactions. However, recently we realized that we need to write at least some of them into the protocol.
Two key reasons are as follows:
1. Inherent inefficiency of EntryPoint as a contract: there is a fixed overhead of about 100,000 gas per bundle, and thousands of additional gas per user operation.
2. Necessity to ensure Ethereum properties: The inclusion guarantees created by inclusion lists need to be transferred to the account abstraction users.
In addition, ERC-4337 also extends two functions:
Paymasters: A feature that allows one account to pay fees on behalf of another account. This violates the rule that only the senders account itself can be accessed during the verification phase, so special processing is introduced to ensure the security of the payment master mechanism.
Aggregators: Functions that support signature aggregation, such as BLS aggregation or SNARK-based aggregation. This is necessary to achieve the highest data efficiency on Rollup.
A talk on the history of account abstraction: https://www.youtube.com/watch?v=iLf8qpOmxQc
ERC-4337: https://eips.ethereum.org/EIPS/eip-4337
EIP-7702: https://eips.ethereum.org/EIPS/eip-7702
BLSWallet code (using aggregation function): https://github.com/getwax/bls-wallet
EIP-7562 (Account abstraction written into the protocol): https://eips.ethereum.org/EIPS/eip-7562
EIP-7701 (EOF-based write protocol account abstraction): https://eips.ethereum.org/EIPS/eip-7701
The main issue that needs to be addressed is how to fully introduce account abstraction into the protocol. The most popular EIP for writing protocol account abstraction is EIP-7701 , which implements account abstraction on top of EOF. An account can have a separate code section for verification. If the account sets this code section, the code will be executed in the verification step of transactions from the account.

The beauty of this approach is that it clearly shows two equivalent views of local account abstraction:
1. Make EIP-4337 part of the protocol
2. A new type of EOA where the signature algorithm is EVM code execution
If we start with strict bounds on the complexity of code that can be executed during verification—no access to external state allowed, and even the initial gas limit set to be low enough to be ineffective for quantum-resistant or privacy-preserving applications—then the security of this approach is clear: just replace ECDSA verification with EVM code execution that takes similar time.
However, over time we will need to relax these bounds, as allowing privacy-preserving applications to work without relays, as well as quantum resistance, is very important. To do this, we need to find ways to more flexibly address Denial of Service (DoS) risks without requiring the verification step to be extremely minimalistic.
The main trade-off seems to be write a solution quickly that pleases fewer people vs. wait longer for a potentially more ideal solution, with the ideal approach probably being some kind of hybrid. One hybrid approach would be to write some use cases faster and leave more time to explore other use cases. Another approach would be to deploy a more ambitious version of the account abstraction on L2 first. However, the challenge here is that L2 teams need to be confident that the adoption proposal will work before they are willing to implement it, especially to ensure that L1 and/or other L2s can adopt compatible solutions in the future.
Another application we need to consider explicitly is key storage accounts that store account-related state on L1 or a dedicated L2, but can be used on L1 and any compatible L2. Doing this efficiently may require L2 to support opcodes such as L1S LOAD या REMOTESTATICCALL , but this will also require the account abstraction implementation on L2 to support these operations.
Inclusion lists need to support account abstraction transactions, and in practice, the requirements for inclusion lists are actually very similar to those for decentralized memory pools, although there is slightly more flexibility for inclusion lists. In addition, account abstraction implementations should be coordinated between L1 and L2 as much as possible. If in the future we expect most users to use key storage Rollups, account abstraction design should be based on this.
EIP-1559 was activated on Ethereum in 2021, significantly improving the average block inclusion time.
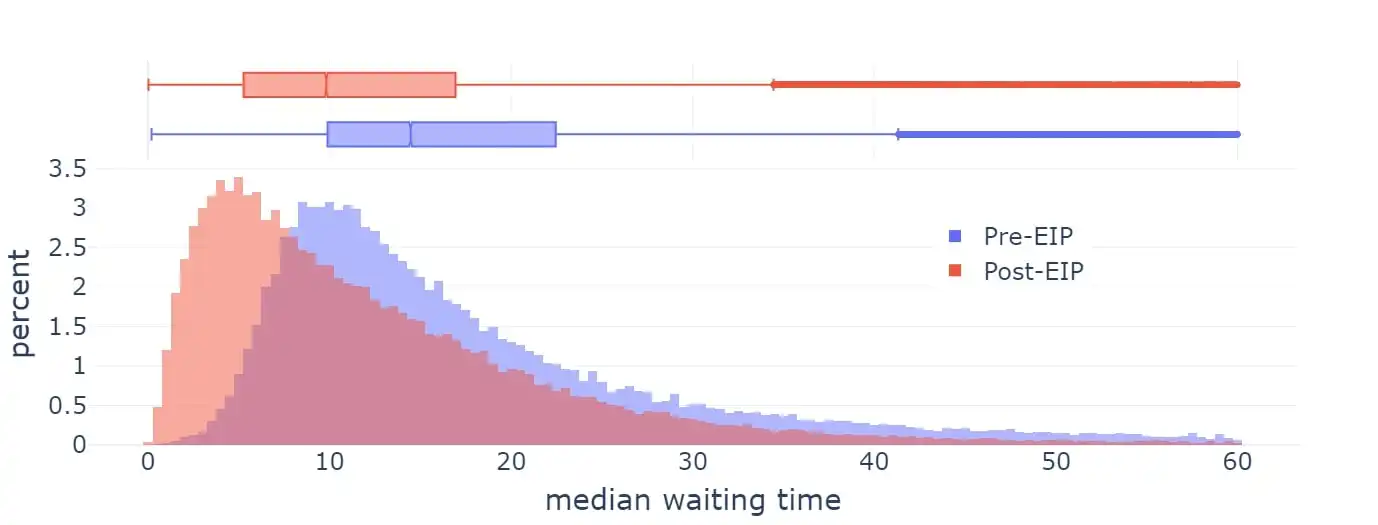
Waiting time
However, the current implementation of EIP-1559 is not perfect in several aspects:
1. The formula is slightly flawed: it doesn’t target 50% of blocks, but rather about 50-53% of full blocks, depending on the variance (this has to do with what mathematicians call the “arithmetic-geometric mean inequality”).
2. Not adjusting quickly enough in extreme situations.
The later formula for blobs (EIP-4844) is specifically designed to address the first problem, and is also cleaner overall. However, neither EIP-1559 itself nor EIP-4844 attempt to address the second problem. As a result, the status quo is a messy middle ground involving two different mechanisms, and there is an argument that both will need to be improved over time.
Additionally, there are other weaknesses in Ethereum resource pricing that are unrelated to EIP-1559, but can be addressed by tweaks to EIP-1559. One of the main issues is the difference between the average and worst case scenarios: resource prices in Ethereum must be set to handle the worst case scenario, where the full gas consumption of a block takes up a resource, but the actual average usage is much lower than this, leading to inefficiencies.
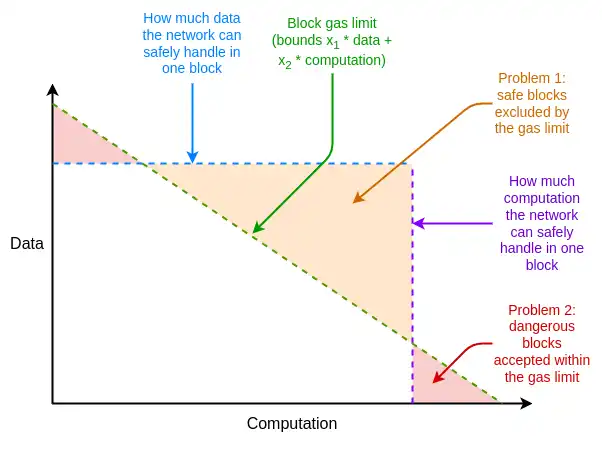
What is Multidimensional Gas and how does it work?
The solution to these inefficiencies is multi-dimensional Gas : different prices and limits for different resources. This concept is technically independent of EIP-1559, but the existence of EIP-1559 makes it easier to implement. Without EIP-1559, optimally packaging a block with multiple resource constraints is a complex multi-dimensional knapsack problem . With EIP-1559, most blocks will not reach full capacity on any resource, so a simple algorithm like accept any transaction that pays enough fees is sufficient.
Currently we have multi-dimensional gas for execution and data blocks; in principle, we can extend this to more dimensions: such as calldata (transaction data), state read/write, and state size expansion.
EIP-7706 introduces a new gas dimension specifically for calldata. It also simplifies the multi-dimensional gas mechanism by unifying the three types of gas into a single (EIP-4844-style) framework, thus also solving the mathematical flaws of EIP-1559. EIP-7623 is a more precise solution to the average-case and worst-case resource problem, with a tighter limit on the maximum calldata without introducing a whole new dimension.
A further research direction is to solve the update rate problem and find a faster basic fee calculation algorithm while preserving the key invariants introduced by the EIP-4844 mechanism (ie: in the long run, the average usage is just close to the target value).
EIP-1559 FAQ: EIP-1559 FAQ
Empirical analysis of EIP-1559
Proposed improvements to allow for quick adjustments:
EIP-4844 FAQ about the basic fee mechanism: EIP-4844 FAQ
EIP-7706: EIP-7706
EIP-7623: EIP-7623
Multidimensional Gas: Multidimensional gas
There are two main trade-offs for multi-dimensional Gas:
1. Increase protocol complexity: Introducing multi-dimensional Gas will make the protocol more complex.
2. Increased complexity of the optimal algorithm required to fill blocks: The optimal algorithm to fill blocks to capacity will also become more complex.
Protocol complexity is relatively small for calldata, but for those gas dimensions that are internal to the EVM (such as storage reads and writes), the complexity increases. The problem is that not only do users set gas limits, but contracts also set limits when calling other contracts. And currently, the only way they can set limits is in a single dimension.
A simple solution is to make multi-dimensional Gas only available inside EOF, because EOF does not allow contracts to set gas limits when calling other contracts. Non-EOF contracts need to pay for all types of Gas when performing storage operations (for example, if SLOAD takes up 0.03% of the block storage access gas limit, then non-EOF users will also be charged 0.03% of the execution gas limit fee).
More research on multi-dimensional Gas will help understand these trade-offs and find the ideal balance.
Successful implementation of multi-dimensional Gas can significantly reduce some of the worst case resource usage, thereby reducing the pressure to optimize performance to support requirements such as binary trees based on STARKed hashes. Setting a clear target for state size growth will make it easier for client developers to plan and estimate requirements in the future.
As mentioned earlier, the existence of EOF makes it easier to implement more extreme versions of multi-dimensional Gas because of its unobservable nature.
Currently, Ethereum uses RANDAO-based randomness to select proposers. RANDAOs randomness works by requiring each proposer to reveal a secret they committed to ahead of time, and mixing each revealed secret into the randomness.
Each proposer thus has 1 bit of power: they can change the randomness by not showing up (at a cost). This makes sense for finding proposers, since its very rare that you give up one opportunity to get two new ones. But its not ideal for on-chain applications that need randomness. Ideally, we should find a more robust source of randomness.
A verifiable delay function is a function that can only be computed sequentially and cannot be accelerated by parallelization. A simple example is repeated hashing: for i in range(10**9): x = hash(x). The output is proved correct using SNARK and can be used as a random value.
The idea is that the inputs are chosen based on information available at time T, while the outputs are not yet known at time T: the outputs are only available sometime after T, once someone has fully run the computation. Because anyone can run the computation, there is no possibility of concealing the results, and therefore no ability to manipulate them.
The main risk with verifiable delay functions is accidental optimization: someone finds a way to run the function faster than expected, thereby manipulating the information they reveal at time T.
1. Hardware acceleration: Someone creates an ASIC that runs computational cycles faster than existing hardware.
2. Accidental Parallelization: Someone finds a way to run a function faster by parallelizing it, even if doing so requires 100 times more resources.
The task of creating a successful VDF is to avoid both of these problems while keeping efficiency practical (e.g., one problem with hash-based approaches is that SNARKing hashes in real time requires heavy hardware). Hardware acceleration is usually addressed by a public interest actor self-creating and distributing a near-optimal VDF ASIC.
VDF research website: vdfresearch.org
Thinking on attacks on VDF in Ethereum, 2018:
Currently, there is no single VDF construction that fully satisfies all of the requirements of Ethereum researchers. More work is needed to find such a function. If found, the main trade-off is whether to include it: a simple trade-off between functionality and protocol complexity and security risks.
If we believe a VDF is secure, but it turns out to be insecure, then depending on how it is implemented, the security will degenerate to the RANDAO assumption (1 bit of control per attacker) or slightly worse. Therefore, even if the VDF fails, it will not break the protocol, but it will break applications or any new protocol features that strongly rely on it.
VDFs are a relatively self-contained component of the Ethereum protocol that, in addition to increasing the security of proposer selection, have applications in (i) on-chain applications that rely on randomness and (ii) cryptographic mempools, although making cryptographic mempools based on VDFs still relies on additional cryptographic discoveries that have not yet happened.
An important point to remember is that given the uncertainty in the hardware, there will be some headroom between when the VDF output is produced and when it is needed. This means that the information will be available several blocks earlier. This can be an acceptable cost, but should be considered in single-slot finalization or committee selection designs.
इससे कौन सी समस्या हल होती है?
One of Nick Szabo’s most famous articles is his 1997 paper on the “God Protocol.” In this paper, he noted that many multi-party applications rely on a “trusted third party” to manage interactions. In his view, the role of cryptography is to create a simulated trusted third party that does the same job without actually requiring trust in any particular participant.
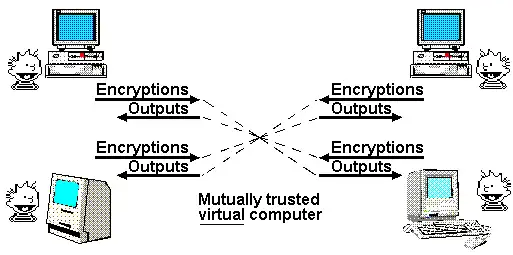
So far, we have only partially achieved this ideal. If all we want is a transparent virtual computer whose data and computations cannot be shut down, censored, or tampered with, and privacy is not a goal, then blockchain can achieve this goal, albeit with limited scalability.
If privacy is the goal, then until recently we have only been able to develop a few specific protocols for specific applications: digital signatures for basic authentication, ring signatures and linkable ring signatures for raw anonymity, identity-based encryption for more convenient encryption under certain assumptions about trusted issuers, blind signatures for Charm-style electronic cash, etc. This approach requires a lot of work for each new application.
In the 2010s, we got our first glimpse of a different and more powerful approach, one based on programmable cryptography. Rather than creating a new protocol for every new application, we can use powerful new protocols — specifically, ZK-SNARKs — to add cryptographic guarantees to arbitrary programs.
ZK-SNARKs allow users to prove arbitrary statements about data they hold, and the proofs are (i) easily verifiable, and (ii) do not reveal any data other than the statement itself. This is a huge step forward in both privacy and scalability, and I liken it to the impact of transformers in AI. Thousands of man-years of application-specific work were suddenly replaced by this general solution that can handle an unexpectedly wide range of problems.
However, ZK-SNARKs are only the first of three similar extremely powerful general primitives. These protocols are so powerful that when I think about them, they remind me of a set of extremely powerful cards in Yu-Gi-Oh! — the card game and TV show I played as a kid: the Egyptian Gods Cards.
The Egyptian God Cards are three extremely powerful cards, legend has it that the process of creating these cards can be fatal, and their power makes their use forbidden in duels. Similarly, in cryptography, we also have this set of three Egyptian God protocols:

ZK-SNARKs is one of the three protocols we already have, with a high level of maturity. Over the past five years, the dramatic improvements in prover speed and developer friendliness have made ZK-SNARKs a cornerstone of Ethereums scalability and privacy strategy. But ZK-SNARKs have an important limitation: you need to know the data to prove it. Each state in a ZK-SNARK application must have a unique owner who must be present to approve the read or write of that state.
The second protocol that does not have this limitation is fully homomorphic encryption (FHE), which allows you to perform any computation on encrypted data without ever looking at the data. This allows you to perform computations on the users data for the users benefit while keeping the data and the algorithm private.
It also enables you to scale voting systems like MACI to get almost perfect security and privacy guarantees. FHE was long considered too inefficient for practical use, but now it’s finally becoming efficient enough to start seeing real-world applications.
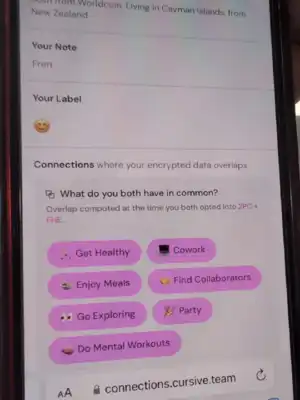
Cursive is an application that leverages two-party computation and fully homomorphic encryption (FHE) for privacy-preserving common interest discovery.
However, FHE also has its limitations: any technology based on FHE still requires someone to hold the decryption key. This can be an M-of-N distributed setup, and you can even use Trusted Execution Environments (TEEs) to add a second layer of protection, but it is still a limitation.
Next comes the third protocol, which is even more powerful than the first two combined: indistinguishability obfuscation. While this technology is still far from mature, as of 2020 we have theoretically valid protocols based on standard security assumptions, and we have recently begun to implement them.
Indistinguishable obfuscation allows you to create a cryptographic program that performs arbitrary computations while hiding all the internal details of the program. As a simple example, you can put your private key into an obfuscated program that only allows you to use it to sign prime numbers, and distribute this program to others. They can use this program to sign any prime number, but they will not be able to extract the key. However, its capabilities go far beyond this: combined with hashing, it can be used to implement any other cryptographic primitives, and more.
The only thing an indistinguishably obfuscated program can’t do is prevent itself from being copied. But for that, there’s a more powerful technology waiting on the horizon, though it relies on everyone having a quantum computer: quantum one-shot signatures.
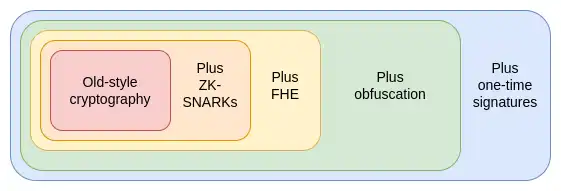
By combining obfuscation and one-time signatures, we can build an almost perfect trustless third party. The only goal that cannot be achieved by cryptography alone and still needs to be guaranteed by the blockchain is censorship resistance. These technologies can not only make Ethereum itself more secure, but also build more powerful applications on it.
To better understand how these primitives add additional capabilities, lets use voting as a key example. Voting is an interesting problem because it needs to satisfy many complex security properties, including very strong verifiability and privacy. While voting protocols with strong security properties have existed for decades, we can make it harder for ourselves by requiring designs that can handle arbitrary voting protocols: quadratic voting, pairwise restricted quadratic funding, cluster matching quadratic funding, and so on. In other words, we want the counting votes step to be an arbitrary program.
First, let’s assume that we put the voting results publicly on the blockchain. This gives us public verifiability (anyone can verify that the final result is correct, including the rules for counting and eligibility) and censorship resistance (people can’t be stopped from voting). But we don’t have privacy.
Then we added ZK-SNARKs, and now we have privacy: every vote is anonymous, while ensuring that only authorized voters can vote, and each voter can only vote once.
Next, we introduced the MACI mechanism, where votes are encrypted to a central servers decryption key. The central server is responsible for the vote counting process, including removing duplicate votes, and publishing a ZK-SNARK proof of the result. This retains the previous guarantees (even if the server cheats!), but if the server is honest, it also adds a guarantee of resistance to coercion: users cannot prove how they voted, even if they wanted to. This is because while users can prove their vote, they cannot prove that they did not vote to offset that vote. This prevents bribery and other attacks.
We run the vote counting in FHE and then perform the N/2-of-N threshold decryption computation. This improves the anti-coercion guarantee to N/2-of-N instead of 1-of-1.
We obfuscate the counting program and design it so that it can only output results when authorized, which can be proof of blockchain consensus, some kind of proof of work, or a combination of the two. This makes the anti-coercion guarantee almost perfect: in the case of blockchain consensus, 51% of validators must collude to break it; in the case of proof of work, even if everyone colludes, it will be extremely expensive to recount the votes with a different subset of voters to try to extract the behavior of a single voter. We can even have the program make small random adjustments to the final count to further increase the difficulty of extracting the behavior of a single voter.
We added one-time signatures, a primitive that relies on quantum computing and allows a signature to be used only once for a certain type of information. This makes the anti-coercion guarantee truly perfect.
Indistinguishable obfuscation also supports other powerful applications. For example:
1. Decentralized Autonomous Organizations (DAOs), on-chain auctions, and other applications with arbitrary internal secret states.
2. A truly universal trusted setup: Someone can create an obfuscated program that contains a key, and run any program and provide the output, putting hash(key, program) as input into the program. Given such a program, anyone can put program 3 into themselves, combining the programs pre-key and their own key, thus extending the setup. This can be used to generate a 1-of-N trusted setup for any protocol.
3. Verification of ZK-SNARKs requires only one signature: Implementing this is very simple: set up a trusted environment and have someone create an obfuscator that will only sign messages with the key if there is a valid ZK-SNARK.
4. Encrypted memory pool: It is very simple to encrypt transactions so that they can only be decrypted if some on-chain event occurs in the future. This can even include a successfully executed Verifiable Delay Function (VDF).
With one-time signatures, we can make blockchains immune to 51% attacks with finality reversal, although censorship attacks are still possible. Primitives like one-time signatures make quantum money possible, solving the double-spending problem without a blockchain, although many more complex applications still require a chain.
If these primitives can be made efficient enough, then most of the worlds applications can be decentralized. The main bottleneck will be verifying the correctness of the implementation.
1. Indistinguishability Obfuscation (2021):
2. How Obfuscation Can Help Ethereum
3. First Known Construction of One-Shot Signatures
4. Attempted Implementation of Obfuscation (1)
5. Attempted Implementation of Obfuscation (2)
There is still a lot of work to be done, and indistinguishable obfuscation is still very immature, with candidate constructions running as slow as (if not more) than expected to be unusable in applications. Indistinguishable obfuscation is famous for being theoretically polynomial time, but in practice its runtime can be longer than the lifetime of the universe. Recent protocols have alleviated this runtime somewhat, but the overhead is still too high for routine use: one implementer estimates a runtime of a year.
Quantum computers dont even exist yet: all the constructions you see on the internet are either prototypes that cant do more than 4-bit operations, or theyre not substantial quantum computers at all, and while they may have quantum parts, they cant run meaningful calculations like Shors or Grovers algorithms. There have been recent signs that real quantum computers are not far away. However, even if real quantum computers appear soon, it may take decades for ordinary people to use quantum computers on their laptops or phones, until the day when powerful institutions can crack elliptic curve cryptography.
For indistinguishable obfuscation, a key trade-off lies in security assumptions, and there are more aggressive designs that use special assumptions. These designs often have more realistic running times, but the special assumptions can sometimes end up being broken. Over time, we may understand lattices better and come up with assumptions that are less prone to breaking. However, this path is more risky. A more conservative approach would be to stick with protocols whose security provably reduces to standard assumptions, but this may mean it takes longer to get a protocol that runs fast enough.
Extremely strong cryptography could revolutionize the game, for example:
1. If we get ZK-SNARKs to be as easy to verify as signing, then we may not need any aggregation protocol anymore; we can just do verification directly on-chain.
2. One-time signatures could mean more secure proof-of-stake protocols.
3. Many complex privacy protocols may only require a privacy-preserving Ethereum Virtual Machine (EVM) to replace them.
4. Encrypted memory pool becomes easier to implement.
Initially, the benefits will emerge at the application layer, as Ethereum’s L1 inherently needs to be conservative in its security assumptions. However, usage at the application layer alone could be disruptive, as was the case with the advent of ZK-SNARKs.
This article is sourced from the internet: Vitaliks new article: The possible future of Ethereum, The Splurge
Original | Odaily Planet Daily ( @OdailyChina ) Author | Fu Howe ( @vincent 31515173 ) As one of the bridges connecting Web3 and mainstream finance, Grayscales initiatives in the crypto industry have attracted much attention. From the initial trust products of Bitcoin, Ethereum, and many well-known tokens to the launch of Bitcoin spot ETF and Ethereum spot ETF this year, Grayscales contribution to the crypto industry is obvious to all. Recently, Grayscale listed 35 crypto assets that it is considering adding to its products in the future. To this end, Odaily Planet Daily first classified the 35 currencies by track, and then sorted them by the market value of each currency, and shared the price trends of the past two years with readers through diagrams. There are a total…













