My XP
0
Login

The recent development of the AI industry is regarded by some as the fourth industrial revolution. The emergence of large models has significantly improved the efficiency of various industries. Boston Consulting Group believes that GPT has improved the work efficiency of the United States by about 20%. At the same time, the generalization ability brought by large models is regarded as a new software design paradigm. In the past, software design was precise code, but now software design is a more generalized large model framework embedded in the software. These software can have better performance and support a wider range of modal input and output. Deep learning technology has indeed brought the fourth prosperity to the AI industry, and this trend has also spread to the Crypto industry.

Ranking of GPT adoption rates in various industries, Source: Bain AI Survey
In this report, we will discuss in detail the development history of the AI industry, technology classification, and the impact of the invention of deep learning technology on the industry. Then we will deeply analyze the upstream and downstream of the industry chain such as GPU, cloud computing, data sources, edge devices, and their development status and trends in deep learning. After that, we will discuss in detail the relationship between Crypto and the AI industry from the essence, and sort out the pattern of the AI industry chain related to Crypto.
The AI industry started in the 1950s. In order to realize the vision of artificial intelligence, academia and industry have developed many schools of thought on implementing artificial intelligence in different eras and disciplines.
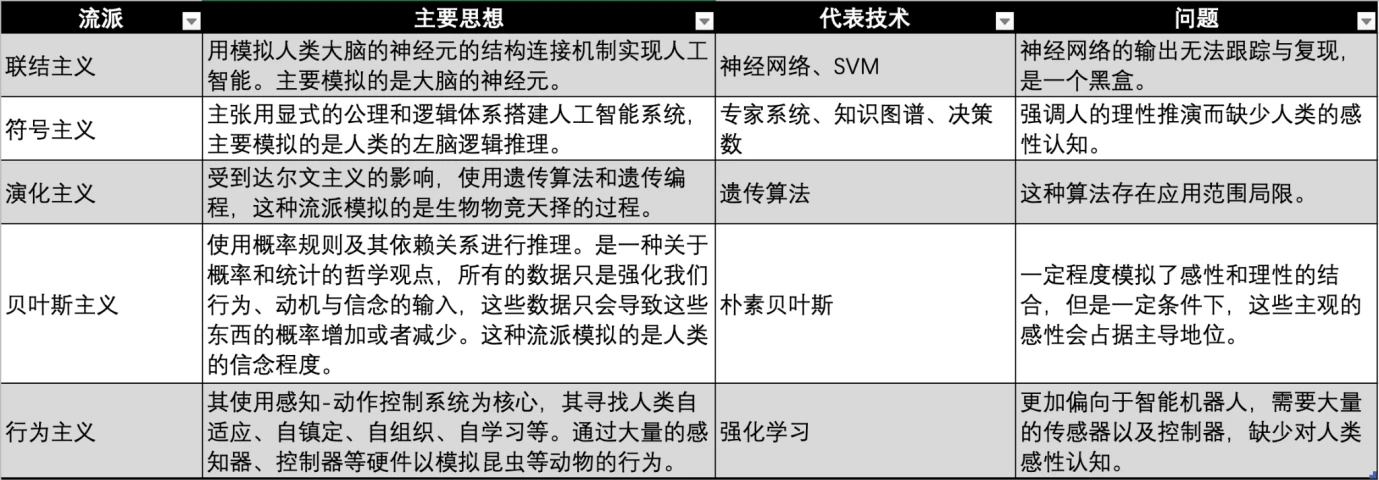
Comparison of AI schools, source: Gate Ventures

AI/ML/DL relationship, source: Microsoft
Modern artificial intelligence technology mainly uses the term machine learning. The concept of this technology is to let the machine rely on data to repeatedly iterate in the task to improve the performance of the system. The main steps are to send data to the algorithm, use this data to train the model, test and deploy the model, and use the model to complete automated prediction tasks.
There are currently three major schools of machine learning: connectionism, symbolism, and behaviorism, which imitate the human nervous system, thinking, and behavior respectively.
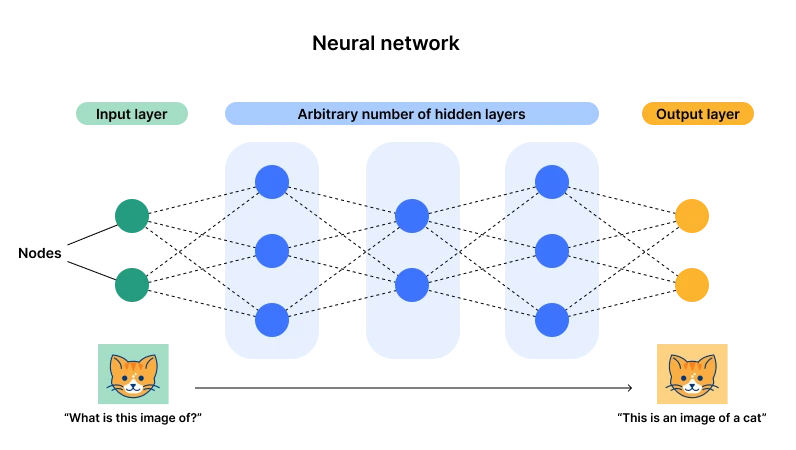
Illustration of neural network architecture. Source: Cloudflare
At present, connectionism represented by neural networks has the upper hand (also known as deep learning). The main reason is that this architecture has one input layer and one output layer, but multiple hidden layers. Once the number of layers and neurons (parameters) becomes large enough, there will be enough opportunities to fit complex general-purpose tasks. Through data input, the parameters of neurons can be adjusted all the time, and finally after many data, the neuron will reach an optimal state (parameters). This is what we call miracles with great effort, and this is also the origin of the word depth – enough layers and neurons.
For example, we can simply understand that we have constructed a function. When we input X= 2, Y= 3; when X= 3, Y= 5. If we want this function to deal with all X, we need to keep adding the degree of this function and its parameters. For example, I can construct a function that satisfies this condition as Y = 2 X -1. However, if there is a data of X= 2, Y= 11, we need to reconstruct a function suitable for these three data points. Using GPU for brute force cracking, we find that Y = X 2 -3 X + 5 is more suitable, but it does not need to completely overlap with the data. It only needs to comply with the balance and roughly similar output. Here, X 2 and X, X 0 all represent different neurons, and 1, -3, 5 are their parameters.
At this point, if we input a large amount of data into the neural network, we can add neurons and iterate parameters to fit the new data. In this way, we can fit all the data.
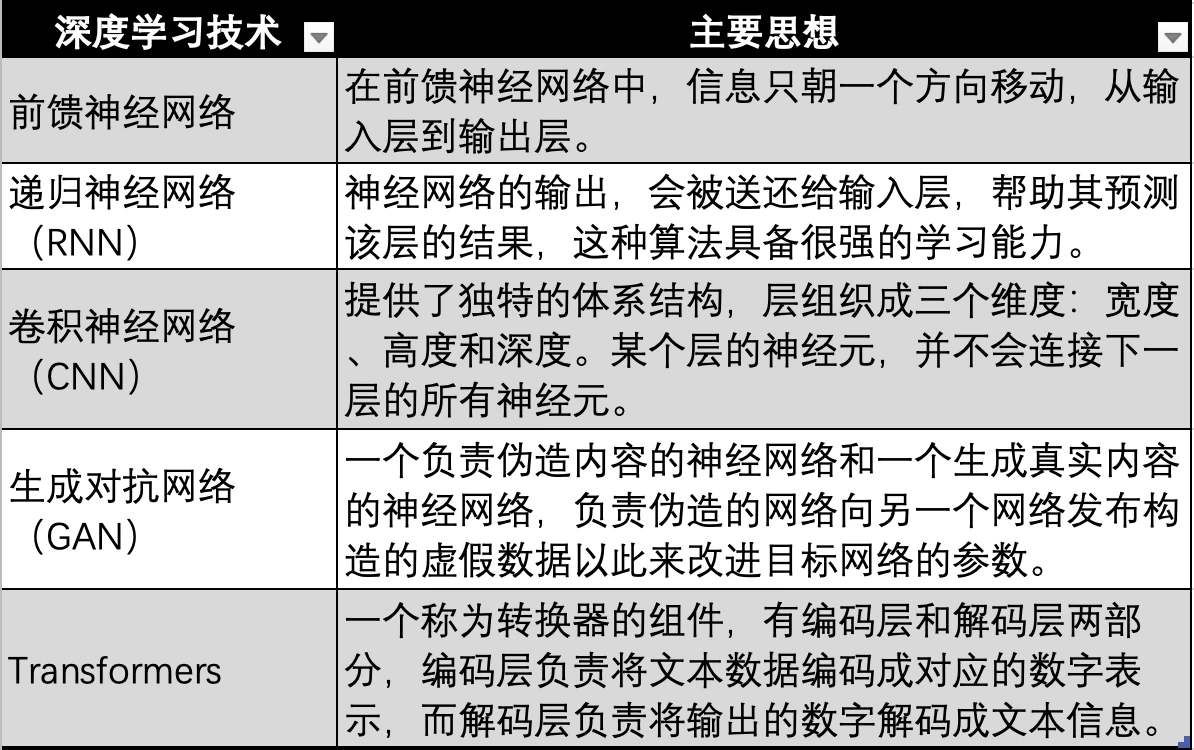
Evolution of deep learning technology, source: Gate Ventures
The deep learning technology based on neural networks has also undergone multiple technical iterations and evolutions, such as the earliest neural networks shown in the figure above, feedforward neural networks, RNNs, CNNs, GANs, and finally the Transformer technology used in modern large models such as GPT. Transformer technology is just one evolutionary direction of neural networks, with an additional transformer (Transformer) used to encode data of all modalities (such as audio, video, pictures, etc.) into corresponding numerical values for representation. Then, the data is input into the neural network, so that the neural network can fit any type of data, that is, to achieve multimodality.
The development of AI has gone through three technological waves. The first wave was in the 1960s, ten years after the introduction of AI technology. This wave was caused by the development of symbolic technology, which solved the problems of general natural language processing and human-computer dialogue. At the same time, the expert system was born. This is the DENRAL expert system completed by Stanford University under the supervision of NASA. The system has very strong chemical knowledge and can infer from questions to generate the same answers as chemical experts. This chemical expert system can be regarded as a combination of a chemical knowledge base and an inference system.
After the expert system, in the 1990s, Israeli-American scientist and philosopher Judea Pearl proposed the Bayesian network, also known as the belief network. At the same time, Brooks proposed behavior-based robotics, marking the birth of behaviorism.
In 1997, IBMs Deep Blue Blue defeated chess champion Kasparov with a score of 3.5: 2.5. This victory was regarded as a milestone in artificial intelligence, and AI technology ushered in its second climax of development.
The third wave of AI technology occurred in 2006. Yann LeCun, Geoffrey Hinton, and Yoshua Bengio, three giants of deep learning, proposed the concept of deep learning, an algorithm that uses artificial neural networks as a framework to represent and learn data. After that, deep learning algorithms gradually evolved, from RNN, GAN to Transformer and Stable Diffusion. These two algorithms jointly shaped this third wave of technology, and this was also the heyday of connectionism.
Many landmark events have also emerged with the exploration and evolution of deep learning technology, including:
● In 2011, IBMs Watson defeated humans and won the championship in the quiz show Jeopardy.
● In 2014, Goodfellow proposed GAN (Generative Adversarial Network), which can generate realistic photos by letting two neural networks compete with each other. At the same time, Goodfellow also wrote a book called Deep Learning, which is one of the important introductory books in the field of deep learning.
● In 2015, Hinton et al. proposed a deep learning algorithm in the journal Nature. The introduction of this deep learning method immediately caused a huge response in academia and industry.
● In 2015, OpenAI was founded, and Musk, YC President Altman, angel investor Peter Thiel and others announced a joint investment of US$1 billion.
● In 2016, AlphaGo, based on deep learning technology, competed against the Go world champion and professional 9th-dan player Lee Sedol in a man-machine Go battle, and won with a total score of 4 to 1.
● In 2017, Sophia, a humanoid robot developed by Hanson Robotics in Hong Kong, China, was called the first robot in history to be granted first-class citizenship. It has rich facial expressions and the ability to understand human language.
● In 2017, Google, which has abundant talent and technical reserves in the field of artificial intelligence, published the paper Attention is all you need and proposed the Transformer algorithm, and large-scale language models began to appear.
● In 2018, OpenAI released GPT (Generative Pre-trained Transformer), which was built on the Transformer algorithm and was one of the largest language models at the time.
● In 2018, Google team Deepmind released AlphaGo based on deep learning, which is capable of predicting protein structure and is regarded as a sign of great progress in the field of artificial intelligence.
● In 2019, OpenAI released GPT-2, a model with 1.5 billion parameters.
● In 2020, OpenAI developed GPT-3, which has 175 billion parameters, 100 times more than the previous version GPT-2. The model used 570 GB of text for training and can achieve state-of-the-art performance on multiple NLP (natural language processing) tasks (answering questions, translating, and writing articles).
● In 2021, OpenAI released GPT-4, a model with 1.76 trillion parameters, 10 times that of GPT-3.
● In January 2023, the ChatGPT application based on the GPT-4 model was launched. In March, ChatGPT reached 100 million users, becoming the fastest application to reach 100 million users in history.
● In 2024, OpenAI launched GPT-4 omni.
At present, all large model languages use deep learning methods based on neural networks. Large models led by GPT have created a wave of artificial intelligence craze, and a large number of players have entered this field. We have also found that the market demand for data and computing power has exploded. Therefore, in this part of the report, we mainly explore the industrial chain of deep learning algorithms, how the upstream and downstream of the AI industry dominated by deep learning algorithms are composed, and what are the current status and supply and demand relationship of the upstream and downstream, and what is the future development.

GPT training pipeline Source: WaytoAI
First of all, we need to be clear that when training LLMs (large models) headed by GPT based on Transformer technology, it is divided into three steps.
Before training, because it is based on Transformer, the converter needs to convert text input into numerical values. This process is called Tokenization, and these numerical values are then called Tokens. Under the general rule of thumb, an English word or character can be roughly regarded as a token, and each Chinese character can be roughly regarded as two tokens. This is also the basic unit used for GPT pricing.
The first step is pre-training. By giving the input layer enough data pairs, similar to the example (X, Y) in the first part of the report, we can find the best parameters for each neuron under the model. This requires a lot of data, and this process is also the most computationally intensive process because it is necessary to repeatedly iterate the neurons to try various parameters. After a batch of data pairs are trained, the same batch of data is generally used for secondary training to iterate the parameters.
The second step is fine-tuning. Fine-tuning is to give a small batch of high-quality data for training. This change will make the model output have higher quality, because pre-training requires a large amount of data, but a lot of data may be wrong or low-quality. The fine-tuning step can improve the quality of the model through high-quality data.
The third step is reinforcement learning. First, we will build a new model, which we call the reward model. The purpose of this model is very simple, which is to sort the output results. Therefore, it is relatively simple to implement this model because the business scenario is relatively vertical. Then use this model to determine whether the output of our large model is of high quality, so that a reward model can be used to automatically iterate the parameters of the large model. (But sometimes human participation is also required to judge the output quality of the model)
In short, in the training process of large models, pre-training has very high requirements on the amount of data and consumes the most GPU computing power, while fine-tuning requires higher-quality data to improve parameters. Reinforcement learning can repeatedly iterate parameters through a reward model to output higher-quality results.
During the training process, the more parameters there are, the higher the ceiling of its generalization ability. For example, in the example of the function, Y = aX + b, there are actually two neurons X and X 0. Therefore, no matter how the parameters change, the data that can be fitted is extremely limited, because its essence is still a straight line. If there are more neurons, more parameters can be iterated, and more data can be fitted. This is why big models work wonders, and this is also why they are popularly named big models. In essence, they are huge numbers of neurons and parameters, huge amounts of data, and huge amounts of computing power.
इसलिए, the performance of large models is mainly determined by three aspects: the number of parameters, the amount and quality of data, and computing power. These three factors together affect the quality of the results and generalization ability of large models. We assume that the number of parameters is p and the amount of data is n (calculated in terms of the number of tokens). Then we can calculate the required computing power through general rules of thumb, so that we can estimate the computing power we need to purchase and the training time.
The computing power is generally measured in Flops, which represents a floating-point operation. Floating-point operations are a general term for addition, subtraction, multiplication and division of non-integer numbers, such as 2.5+ 3.557. Floating points represent the ability to carry decimal points, while FP 16 represents the precision that supports decimals, and FP 32 is generally a more common precision. According to the rule of thumb in practice, pre-training a large model once (usually multiple times) requires about 6 np Flops, and 6 is called an industry constant. Inference (the process of inputting a data and waiting for the output of the large model) is divided into two parts, inputting n tokens and outputting n tokens, so about 2 np Flops are required in total.
In the early days, CPU chips were used to provide computing power for training, but later GPUs were gradually used instead, such as Nvidias A100 and H100 chips. Because CPUs exist as general-purpose computing, but GPUs can be used for dedicated computing, and their energy efficiency far exceeds that of CPUs. GPUs run floating-point operations mainly through a module called Tensor Core. Therefore, general chips have Flops data under FP16/FP32 precision, which represents its main computing power and is also one of the main measurement indicators of chips.

Specifications of the Nvidia A100 chip, Source: NVIDIA
Therefore, readers should be able to understand the chip introductions of these companies. As shown in the figure above, in the comparison of Nvidias A100 80GB PCIe and SXM models, it can be seen that PCIe and SXM are 312 TFLOPS and 624 TFLOPS (Trillion Flops) respectively under Tensor Core (a module specifically used to calculate AI) at FP16 precision.
Assuming that our large model parameters take GPT 3 as an example, there are 175 billion parameters and 180 billion tokens of data (about 570 GB), then a pre-training will require 6 np of Flops, which is about 3.15* 1022 Flops. If TFLOPS (Trillion FLOPs) is used as the unit, it is about 3.15* 1010 TFLOPS, which means that a SXM chip takes about 50480769 seconds, 841346 minutes, 14022 hours, and 584 days to pre-train GPT 3 once.
We can see that this is an extremely large amount of computing. It requires multiple state-of-the-art chips to work together to achieve pre-training. In addition, the number of parameters of GPT 4 is ten times that of GPT 3 (1.76 trillion), which means that even if the amount of data remains unchanged, the number of chips must be purchased ten times more. In addition, the number of tokens of GPT-4 is 13 trillion, which is ten times that of GPT-3. Ultimately, GPT-4 may require more than 100 times the chip computing power.
In the training of large models, our data storage is also problematic, because our data, such as the number of GPT 3 tokens, is 180 billion, which occupies about 570 GB in the storage space, and the neural network with 175 billion parameters of the large model occupies about 700 GB of storage space. The memory space of GPU is generally small (such as 80 GB for A 100 introduced in the figure above), so when the memory space cannot accommodate these data, it is necessary to examine the bandwidth of the chip, that is, the speed of data transmission from the hard disk to the memory. At the same time, since we will not use only one chip, we need to use the joint learning method to jointly train a large model on multiple GPU chips, which involves the transmission rate of GPU between chips. Therefore, in many cases, the factors or costs that restrict the final model training practice are not necessarily the computing power of the chip, but more often the bandwidth of the chip. Because data transmission is slow, it will lead to a longer running model time and higher electricity costs.

H100 SXM chip Specification, Source: NVIDIA
At this point, readers can roughly understand the chip specifications. FP 16 represents precision. Since the training of AI LLMs mainly uses the Tensor Core component, we only need to look at the computing power of this component. FP 64 Tensor Core means that the H 100 SXM can process 67 TFLOPS per second at 64 precision. GPU memory means that the chip has only 64 GB of memory, which is completely unable to meet the data storage requirements of large models. Therefore, GPU memory bandwith means the speed of data transmission, which is 3.35 TB/s for H 100 SXM.
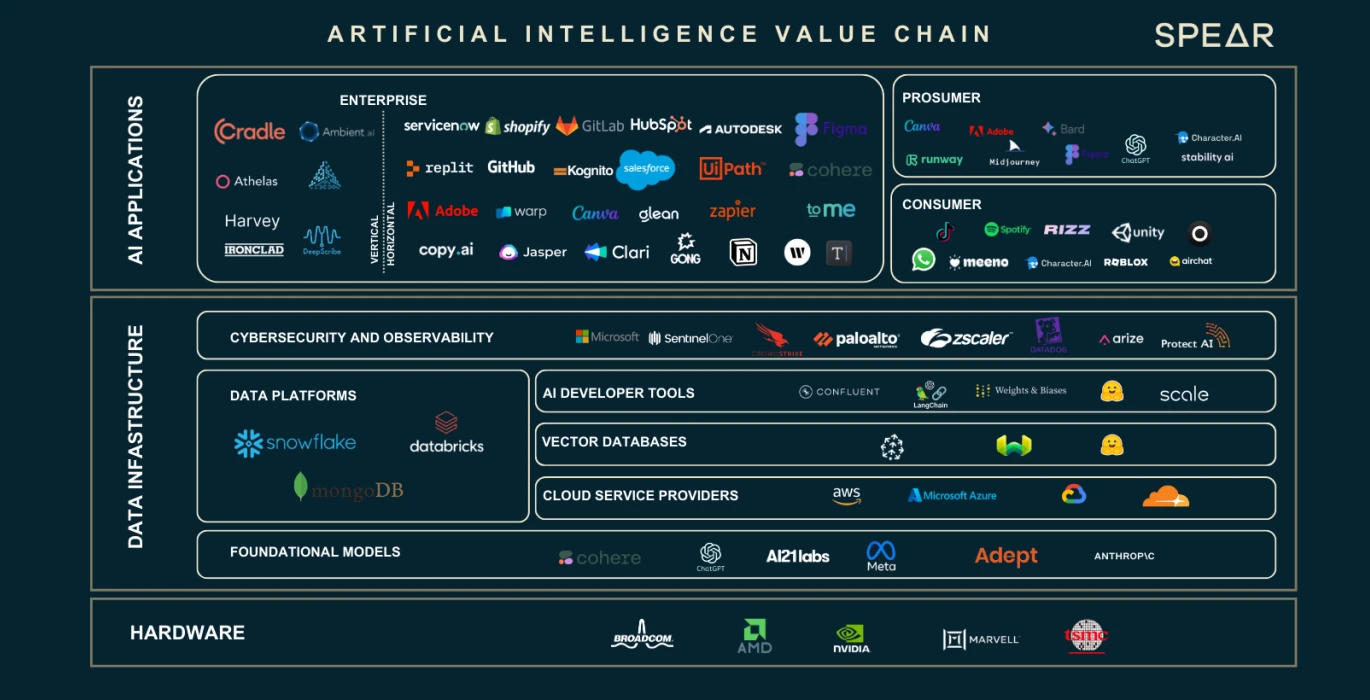
AI Value Chain, source: Nasdaq
We have seen that the expansion of data and the number of neuron parameters has led to a large gap in computing power and storage requirements. These three main factors have incubated an entire industrial chain. We will introduce the role and function of each part of the industrial chain based on the above figure.
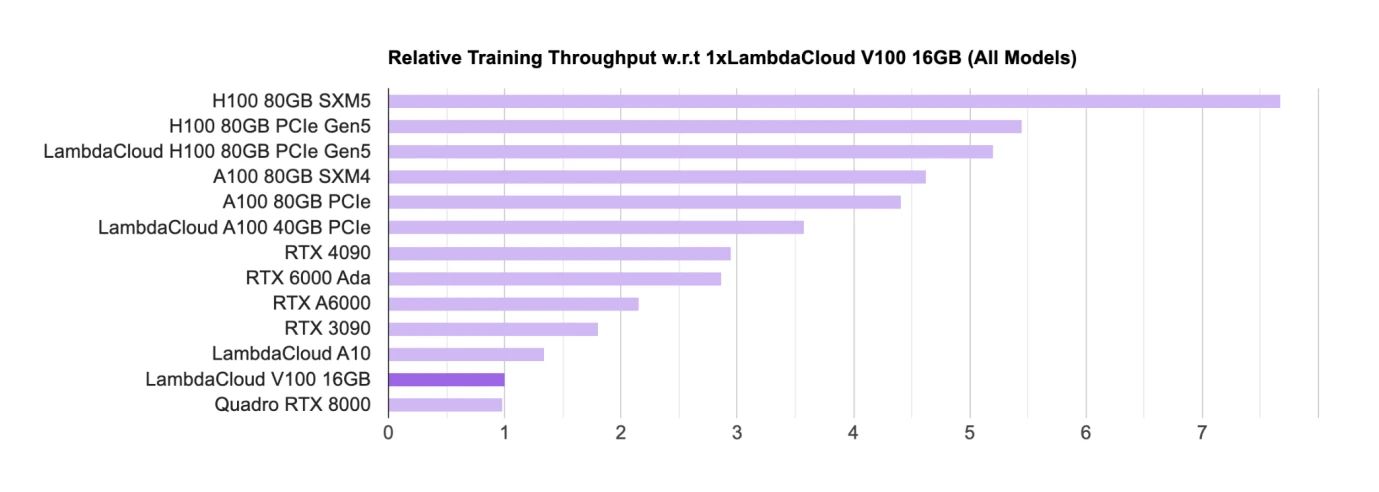
AI GPU Chip Rankings, Source: Lambda
Hardware such as GPU is the main chip for training and reasoning. Nvidia is currently in an absolute leading position among the major GPU chip designers. The academic community (mainly universities and research institutions) mainly uses consumer-grade GPUs (RTX, the main gaming GPU); the industrial community mainly uses H100, A100, etc. for the commercialization of large models.
Nvidia’s chips dominate the list, and all chips come from Nvidia. Google also has its own AI chip called TPU, but TPU is mainly used by Google Cloud to provide computing power support for B-side enterprises. Self-purchased enterprises generally still prefer to buy Nvidia’s GPU.

H 100 GPU Purchase Statistics by Company, Source: Omdia
A large number of companies are working on the development of LLMs, including China, which has more than 100 large models, and more than 200 large language models have been released worldwide. Many Internet giants are participating in this AI boom. These companies either purchase large models themselves or rent them through cloud companies. In 2023, Nvidias most advanced chip H100 was subscribed by many companies as soon as it was released. The global demand for H100 chips far exceeds the supply, because currently only Nvidia is supplying the highest-end chips, and its delivery cycle has reached an astonishing 52 weeks.
In view of Nvidias monopoly, Google, as one of the absolute leaders in artificial intelligence, took the lead in establishing the CUDA Alliance with Intel, Qualcomm, Microsoft, and Amazon, hoping to jointly develop GPUs to get rid of Nvidias absolute influence on the deep learning industry chain.
For super large technology companies/cloud service providers/national laboratories, they often purchase thousands or tens of thousands of H100 chips to build HPC (high-performance computing centers). For example, Teslas CoreWeave cluster purchased 10,000 H100 80 GB chips, with an average purchase price of US$44,000 (Nvidias cost is about 1/10), and a total cost of US$440 million; Tencent purchased 50,000 chips; Meta bought 150,000 chips. As of the end of 2023, Nvidia, as the only seller of high-performance GPUs, has ordered more than 500,000 H100 chips.

Nvidia GPU product roadmap, Source: Techwire
In terms of Nvidias chip supply, the above is its product iteration roadmap. As of this report, the news of H200 has been released. It is expected that the performance of H200 will be twice that of H100, and B100 will be launched in late 2024 or early 2025. At present, the development of GPU still meets Moores Law, with performance doubling every 2 years and price falling by half.

Types of GPU Cloud, Source: Salesforce Ventures
After purchasing enough GPUs to build HPC, cloud service providers can provide flexible computing power and managed training solutions for AI companies with limited funds. As shown in the figure above, the current market is mainly divided into three categories of cloud computing providers. The first category is the ultra-large-scale cloud computing platforms represented by traditional cloud vendors (AWS, Google, Azure). The second category is vertical cloud computing platforms, which are mainly deployed for AI or high-performance computing. They provide more professional services, so there is still a certain market space in the competition with giants. Such emerging vertical industry cloud service companies include CoreWeave (US$1.1 billion in financing in the C round, with a valuation of US$19 billion), Crusoe, Lambda (US$260 million in financing in the C round, with a valuation of more than US$1.5 billion), etc. The third type of cloud service provider is a newly emerged market player, mainly inference-as-a-service providers. These service providers rent GPUs from cloud service providers. This type of service provider mainly deploys pre-trained models for customers and performs fine-tuning or inference on them. Representative companies in this market include Together.ai (latest valuation of US$1.25 billion), Fireworks.ai (led by Benchmark, US$25 million in Series A financing), etc.
As mentioned in the previous part of our second section, large model training mainly goes through three steps, namely pre-training, fine-tuning, and reinforcement learning. Pre-training requires a large amount of data, and fine-tuning requires high-quality data. Therefore, search engines such as Google (with a large amount of data) and data companies such as Reddit (high-quality dialogue data) have received widespread attention from the market.
In order to avoid competing with general-purpose large models such as GPT, some developers choose to develop in niche areas, so the data requirements become industry-specific, such as finance, medicine, chemistry, physics, biology, image recognition, etc. These are models for specific fields and require data in specific fields, so there are companies that provide data for these large models. We can also call them data labling companies, which means labeling the data after collecting it and providing better quality and specific data types.
For companies engaged in model development, large amounts of data, high-quality data, and specific data are the three main data demands.

Major Data Labeling Companies, Source: Venture Radar
A study by Microsoft believes that for SLMs (small language models), if their data quality is significantly better than that of large language models, their performance will not necessarily be worse than that of LLMs. In fact, GPT does not have a clear advantage in originality and data. Its success is mainly due to its courage to bet on this direction. Sequoia Capital also admitted that GPT may not maintain its competitive advantage in the future because it does not have a deep moat in this regard at present, and the main limitation comes from the limitation of computing power acquisition.
As for the amount of data, according to EpochAIs prediction, all low-quality and high-quality data will be exhausted in 2030 based on the current growth of model scale. Therefore, the industry is currently exploring artificial intelligence synthetic data, so that unlimited data can be generated. Then the bottleneck is only computing power. This direction is still in the exploratory stage and deserves the attention of developers.
We have data, but the data also needs to be stored, usually in a database, which makes it easy to add, delete, modify and query data. In traditional Internet business, we may have heard of MySQL, and in the Ethereum client Reth, we have heard of Redis. These are local databases where we store business data or blockchain data. Different databases are adapted for different data types or businesses.
For AI data and deep learning training and reasoning tasks, the database currently used in the industry is called a vector database. Vector databases are designed to efficiently store, manage, and index massive amounts of high-dimensional vector data. Because our data is not simply numerical or textual, but massive amounts of unstructured data such as pictures and sounds, vector databases can store these unstructured data in a unified form of vectors, and vector databases are suitable for the storage and processing of these vectors.

Vector Database Classification, Source: Yingjun Wu
The main players at present include Chroma (received $18 million in financing), Zilliz (received $60 million in the latest round of financing), Pinecone, Weaviate, etc. We expect that with the increase in the demand for data volume and the emergence of large models and applications in various segments, the demand for Vector Database will increase significantly. And because this field has strong technical barriers, when investing, we tend to consider mature companies with customers.
When setting up a GPU HPC (high-performance computing cluster), a lot of energy is usually consumed, which will generate a lot of heat energy. In a high-temperature environment, the chip will limit its running speed to reduce the temperature. This is what we commonly call throttling. This requires some cooling edge devices to ensure the continuous operation of HPC.
So there are two directions of the industrial chain involved here, namely energy supply (generally using electricity) and cooling system.
At present, the energy supply side mainly uses electricity, and data centers and supporting networks currently account for 2%-3% of global electricity consumption. BCG predicts that with the increase in parameters of large deep learning models and the iteration of chips, the electricity required to train large models will increase threefold by 2030. At present, domestic and foreign technology companies are actively investing in energy companies, and the main energy directions of investment include geothermal energy, hydrogen energy, battery storage and nuclear energy.
In terms of heat dissipation of HPC clusters, air cooling is currently the main method, but many VCs are investing heavily in liquid cooling systems to maintain the smooth operation of HPC. For example, Jetcool claims that its liquid cooling system can reduce the total power consumption of the H100 cluster by 15%. Currently, liquid cooling is mainly divided into three exploration directions: cold plate liquid cooling, immersion liquid cooling, and spray liquid cooling. Companies in this field include: Huawei, Green Revolution Cooling, SGI, etc.
The current development of AI applications is similar to the development of the blockchain industry. As an innovative industry, Transformer was proposed in 2017, and OpenAI confirmed the effectiveness of large models in 2023. Therefore, many Fomo companies are now crowded in the research and development track of large models, that is, the infrastructure is very crowded, but application development has not kept up.

Top 50 monthly active users, Source: A16Z
Currently, most of the AI applications that were active in the first ten months were search-type applications. The number of AI applications that have actually come out is still very limited, and the application types are relatively single. There are no social and other types of applications that have successfully made it.
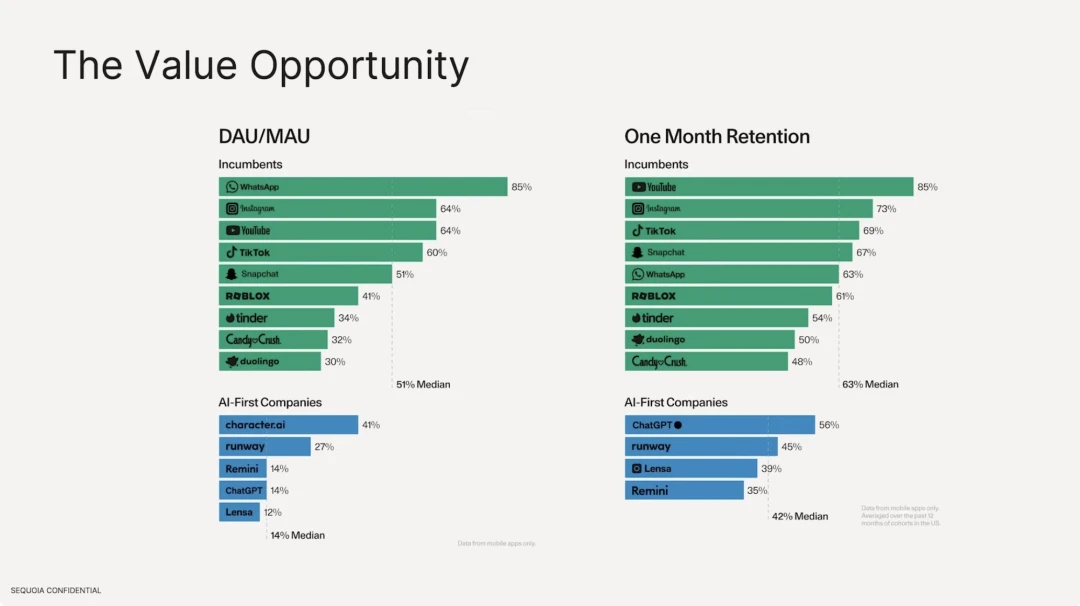
We also found that the retention rate of AI applications based on large models is much lower than that of existing traditional Internet applications. In terms of the number of active users, the median of traditional Internet software is 51%, with Whatsapp being the highest, which has strong user stickiness. However, on the AI application side, character.ai has the highest DAU/MAU at only 41%, and DAU accounts for 14% of the median number of total users. In terms of user retention rate, the best traditional Internet software are Youtube, Instagram, and Tiktok, with the median retention rate of the top ten being 63%. In comparison, ChatGPTs retention rate is only 56%.

AI Application Landscape, Source: Sequoia
According to a report by Sequoia Capital USA, applications are divided into three categories based on the roles they target: professional consumers, enterprises, and ordinary consumers.
1. Consumer-oriented: Generally used to improve productivity, such as text workers using GPT for question and answer, automated 3D rendering modeling, software editing, automated agents, and using Voice-type applications for voice conversations, companionship, language practice, etc.
2. Enterprise-oriented: usually industries such as marketing, law, and medical design.
Although many people now criticize that infrastructure is far greater than applications, we actually believe that the modern world has been widely reshaped by artificial intelligence technology, but the recommendation system is used, including ByteDances Tiktok, Toutiao, Soda Music, etc., as well as Xiaohongshu and WeChat Video Account, advertising recommendation technology, etc., which are customized recommendations for individuals, all of which belong to machine learning algorithms. Therefore, the current booming deep learning does not completely represent the AI industry. There are many potential technologies that have the opportunity to achieve general artificial intelligence are also developing in parallel, and some of these technologies have been widely used in various industries.
So, what kind of relationship has developed between Crypto and AI? What are the projects worth paying attention to in the Crypto industry’s Value Chain? We will explain them one by one in Gate Ventures: AI x Crypto from Beginner to Master (Part 2).
अस्वीकरण:
The above content is for reference only and should not be regarded as any advice. Please always seek professional advice before making any investment.
गेट वेंचर्स Gate.io की उद्यम पूंजी शाखा है, जो विकेन्द्रीकृत बुनियादी ढांचे, पारिस्थितिकी तंत्र और अनुप्रयोगों में निवेश पर ध्यान केंद्रित करती है, जो वेब 3.0 युग में दुनिया को नया आकार देगी। गेट वेंचर्स works with global industry leaders to empower teams and startups with innovative thinking and capabilities to redefine social and financial interaction models.
आधिकारिक वेबसाइट: https://ventures.gate.io/
ट्विटर: https://x.com/gate_ventures
मध्यम: https://medium.com/gate_ventures
This article is sourced from the internet: Gate Ventures: AI x Crypto from Beginner to Master (Part 1)
Related: Another architecture of Dex from ArtexSwap
ArtexSwap is a decentralized exchange that uses Artela EVM++ and Aspect technology to solve MEV risks and Rug Pull problems, improve transaction security and efficiency, and is suitable for decentralized trading scenarios that require high security and flexibility. Since the birth of Ethereum, it has been the technological home of digital currency, global payments and applications. DEX is the cornerstone of decentralized finance (DeFi). After all, without DEX, DeFi can be said to be just empty talk. As a platform running on the blockchain, it runs direct transactions between users and is not regulated by any third-party institutions, which allows it to create more advanced financial products. 1. Dex mainstream architecture At present, DEX is flourishing in the Ethereum ecosystem. There are many different design patterns for DEX, each of…













