Análisis en profundidad de Based Booster Rollup: antecedentes, práctica y perspectivas
Autor original: jolestar (X: @jolestar )
Vi a varios amigos hablando sobre Based Rollup, la mayoría de ellos lo hacían desde la perspectiva de la seguridad. Me gustaría hablar sobre mis puntos de vista sobre Based Booster Rollup desde la perspectiva de la relación entre L1 y L2, y la construcción de aplicaciones.
La idea de Based Rollup es en realidad muy simple, es decir, los usuarios envían directamente las transacciones L2 a L1, que son ordenadas y empaquetadas por L1. Sin embargo, L1 no verifica la validez de las transacciones, sino que solo garantiza el orden y la disponibilidad de las transacciones. L2 es un ejecutor puro que ejecuta las transacciones L2 empaquetadas en L1. ¿Esto te resulta familiar? ¿No es este el modo Inscripción? Sí, el indexador de la inscripción puede entenderse como L2 aquí. Lo he dicho en el artículo ¿La inscripción es un error o una característica?
Booster Rollup comienza desde otra perspectiva. ¿Cómo leer directamente el estado de L1 a través del contrato en L2? La idea no es complicada. Dado que Based Rollup ya está ejecutando transacciones L2 en L1, ¿por qué no ejecutar también transacciones L1? De esta manera, los estados de L1 y L2 están en un gran árbol de estados y el contrato L2 puede leer directamente el estado de L1.
También existen proyectos que combinan Based Rollup y Booster Rollup, llamados Based Booster Rollup (BBR), como taiko.
Antecedentes de BBR
Desde el momento en que se propuso BBR hasta el momento en que atrajo la atención del mercado, el trasfondo principal es el problema de división provocado por la actual solución L2 dominante de Ethereum, la división entre L1 y L2, y la división entre L2. Las funciones proporcionadas por la actual solución L2, ya sea desde la perspectiva de los desarrolladores o de los usuarios, no son muy diferentes de una Alt-L1. La lectura de datos L1 todavía depende de Oracle, los activos todavía necesitan un puente y las billeteras tienen que cambiar de red. Esta división también trae otro problema. El vínculo entre L1 y L2 no es tan estrecho. L2 puede agregar un conjunto de mecanismos de consenso en cualquier momento para convertirse en una Alt-L1, valerse por sí misma y hacer que los desarrolladores y los usuarios básicamente no lo sepan. La principal relación de enlace actual proviene de las restricciones de EF sobre la ortodoxia: L2 debe usar L1 como DA, pero obviamente esta restricción no es confiable.
Entonces, si reemplazamos todas las soluciones L2 actuales con soluciones Based Rollup, ¿se resolverá el problema? Supongo que Optimism y Arbitrum se darán cuenta y dirán: ¿no es fácil cambiar a Based Rollup? Las principales soluciones L2 ahora tienen mecanismos de inclusión forzada. L2 elimina directamente el secuenciador y permite a los usuarios enviar transacciones a L1 a través de la inclusión forzada. ¿No está implementado Based Rollup?
Pero ¿puede esto resolver el problema de la fragmentación? No. Aunque Arb y Op envían transacciones a L1 en tiempo real, y L1 las empaqueta y clasifica, aún están fragmentadas porque cada una solo reconoce sus propias transacciones. En este punto, todos deberían entender que la clave para resolver el problema de la fragmentación para Based Rollup es tener transacciones o datos que se puedan compartir entre L2, y este formato de datos requiere:
-
Debe ser un formato definiciónSe basa en L1, que es independiente de la plataforma y la implementación. Las distintas cuentas y máquinas virtuales de L2 son diferentes y sus transacciones no se pueden compartir directamente.
-
Requiere consenso entre L2 y apoyo de múltiples L2.
Por lo tanto, primero debe ser un protocolo, primero diseñar un protocolo público y un formato de datos, solo almacenar los datos requeridos por el protocolo en la cadena, ejecutar y verificar fuera de la cadena e implementar soluciones de soporte para diferentes L2. Pero en realidad es bastante difícil lograr estos dos puntos. En primer lugar, los desarrolladores en el ecosistema Ethereum generalmente diseñan protocolos a través de contratos inteligentes y no tienen el hábito de diseñar protocolos directamente basados en formatos de datos. El principal intento en esta dirección fue Ethscriptions cuando las inscripciones fueron populares la última vez. El segundo punto es aún más difícil y requiere práctica y tiempo para verificar.
De BBR a BBSR, L2 apilable
Después de hablar sobre el tema del intercambio de datos, hablemos de la experiencia del usuario. Obviamente, si todas las transacciones se envían directamente a L1 por parte de los usuarios, la experiencia es casi la misma que si se utiliza L1, ya sea en el momento del gas o de la confirmación. Por eso, algunas personas comenzaron a diseñar un protocolo de preconfirmación para el Based Rollup, pero si el protocolo de preconfirmación realmente puede funcionar, todas las transacciones deben pasar primero por el protocolo de preconfirmación, ¿no es entonces un secuenciador? ¿Es una pérdida de tiempo hablar de esto?
Esta contradicción surge porque la gente confunde varios tipos de transacciones:
-
Las transacciones enviadas directamente por los usuarios a L1 y ejecutadas y verificadas por L1 son transacciones L1.
-
El usuario envía directamente a L1, pero L1 no verifica ni ejecuta directamente. La transacción de datos del protocolo compartido entre L2 se puede llamar transacción L1.5.
-
El usuario envía directamente la transacción al secuenciador L2, que es preconfirmada y ejecutada por el secuenciador, una transacción dedicada de un determinado L2.
El método de acumulación basado solo está relacionado con 1 y 2. El método de funcionamiento actual del método de acumulación de secuenciadores es 3. Ambos métodos se pueden combinar.
Supongamos que existe una solución Rollup como esta:
-
El secuenciador sincroniza automáticamente todas las transacciones L1 (incluida L1.5) y las ejecuta en el orden indicado por L1.
-
El secuenciador recibe transacciones L2 al mismo tiempo, las clasifica junto con las transacciones L1 y las ejecuta.
A través de 1, implementa Based y Booster, y a través de 2, realiza una confirmación rápida de transacciones L2 sin sacrificar la experiencia del usuario. De acuerdo con el esquema de nombres anterior, esto debería llamarse BBSR (Based Booster Sequencer Rollup), pero es un poco largo y no es fácil de entender, por lo que lo llamo Stackable L2. Como sugiere el nombre, L2 se apila en L1 y L2 contiene todas las transacciones y estados de L1. Esto es La solución de @RoochNetwork .
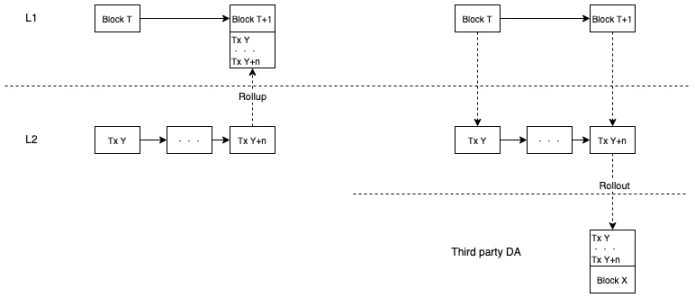
¿Cómo garantizar la DA de las transacciones L2? ¿Acumulación o Rollout?
Si se adopta la solución anterior, será un poco extraño que L2 empaquete sus propias transacciones y las envíe nuevamente a L1, porque L2 leerá las transacciones L1 que empaquetan sus propias transacciones y las volverá a ejecutar, lo que es un poco como si su propia salida también se convirtiera en su propia entrada. Por lo tanto, la solución de Rooch es Rollout en lugar de Rollup. Porque a largo plazo, el espacio de bloque de L1 es muy valioso y múltiples transacciones L2 que ocupan el espacio de L1 es un modo de rotación. El espacio de L1 debe dejarse para las transacciones L1 y L1.5. Las transacciones a nivel de aplicación L2 deben buscar espacio de bloque más barato y expandir nuevo espacio de bloque a través del despliegue, lo que también es propicio para el desarrollo de todo el ecosistema de la industria.
Práctica de BBSR/Stackable L2 en el ecosistema de Bitcoin
Las descripciones anteriores se han realizado desde la perspectiva de Ethereum. Como Rooch es la primera plataforma BBSR o Stackable L2 de Bitcoin, hablemos de las diferencias en el ecosistema de Bitcoin.
No existe un contrato inteligente Turing-completo en Bitcoin L2, lo que se convierte en una ventaja en el modo Based Rollup. Debido a que Based Rollup no necesita L1 para ejecutar y verificar transacciones, solo necesita garantizar Permission Less y DA. Esto también obligó a los proyectos en el ecosistema de Bitcoin a diseñar protocolos basados en estructuras de datos de hace mucho tiempo. Ya sean monedas coloreadas, o más tarde RGB, Taproot Assets, Ordinals Inscription, Atomicals, Runs, etc., todos son intentos en esta categoría y pueden incluirse en el concepto amplio de protocolo CSV (Validación del lado del cliente). Sus transacciones son transacciones L1.5 típicas. Si los proyectos en el ecosistema Ethereum quieren practicar Based L2 y diseñar un protocolo compartido entre múltiples L2, será aproximadamente el mismo que el protocolo anterior.
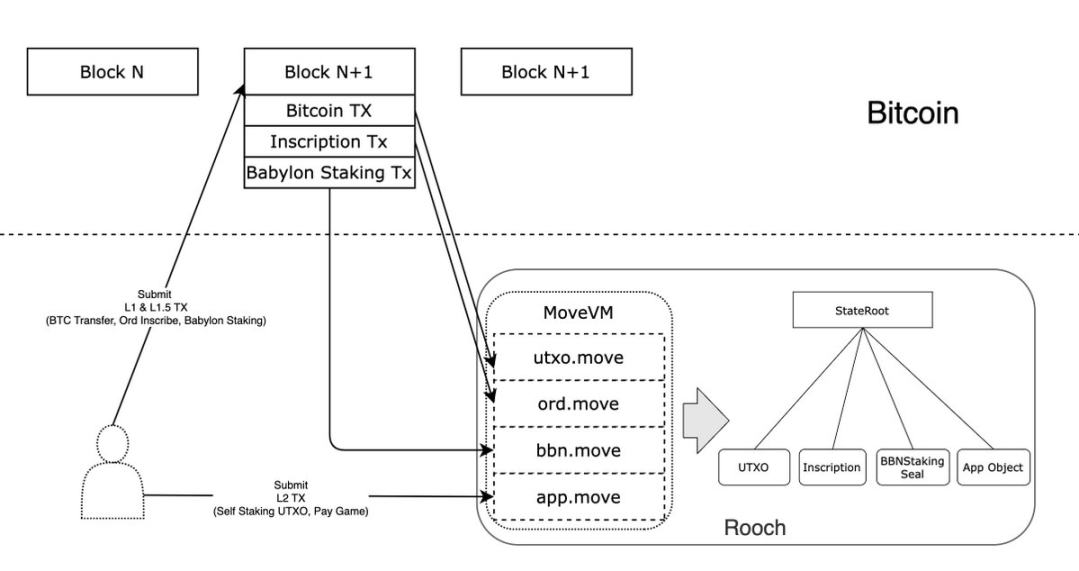
Tomemos a Rooch como ejemplo para explicar el modo de funcionamiento de BBSR en Bitcoin:
-
Los usuarios enviarán directamente transacciones L1 y L1.5 a Bitcoin. Como el protocolo es público, el punto de entrada puede ser cualquier aplicación.
-
Rooch sincronizará todas las transacciones L1, procesará los UTXO que contengan y averiguará si hay información adicional sobre el protocolo, para luego utilizar el módulo Move correspondiente para procesarla. Por ejemplo, las transacciones identificadas como Inscripción serán procesadas por el módulo ord, mientras que las transacciones de Babylon Staking serán procesadas por el módulo bbn.
-
Los usuarios envían directamente las transacciones L2 al nodo Roochs Sequencer para su procesamiento. Los resultados de la ejecución de las tres transacciones anteriores generarán un árbol de estados completo y el contrato de aplicación puede hacer uso completo de los estados generados por las transacciones L1 y L1.5.
Las aplicaciones en este modo pueden diseñar dos tipos de transacciones: una es la transacción de protocolo público (parte basada en L1) y la otra es la transacción de aplicación (secuenciada por Sequencer). Las dos pueden cooperar entre sí a través del modo Booster para garantizar la ausencia de permisos y, al mismo tiempo, garantizar la experiencia del usuario.
Como se mencionó anteriormente, el diseño de protocolos públicos requiere tiempo y práctica para verificar y llegar a un consenso, y Rooch puede proporcionar un entorno experimental tan conveniente: si desea diseñar una nueva aplicación o protocolo de activos en Bitcoin, solo necesita definir el formato del protocolo y luego implementar un módulo de contrato Move correspondiente para procesarlo, y luego puede experimentar construyendo escenarios de aplicación.
Por supuesto, el ecosistema de Bitcoin también enfrenta algunos desafíos a lo largo de esta ruta:
-
Cuando se diseñó Bitcoin por primera vez, no dejó suficiente espacio para la expansión de este escenario de DA. Por lo tanto, la forma de escribir datos en Bitcoin fue una de las direcciones que varios protocolos intentaron explorar, como la incrustación de datos en OP_RETURN, a través de Witness e incluso a través de firmas. Actualmente, todavía faltan soluciones estandarizadas.
-
El ecosistema de Bitcoin no ha alcanzado un consenso amplio sobre el valor de los datos integrados en la cadena. Esto es lo que he estado pidiendo desde la última locura de las inscripciones. El ecosistema de Bitcoin debería otorgar importancia al valor de Bitcoin como un bus de datos público global.
El valor de L1 como bus de datos común global
Desde el verano de DeFi, todo el campo de las criptomonedas ha estado explorando nuevas aplicaciones más allá de DeFi. Ya sea la locura de la inscripción de Bitcoin o la reciente discusión candente sobre Based Rollup, se puede entender como un redescubrimiento del valor de L1 como bus de datos. Desde la perspectiva de los sistemas distribuidos, el desacoplamiento entre sistemas se puede lograr a través del bus de datos, y el desacoplamiento entre sistemas es uno de los requisitos previos clave para lograr menos permisos. Por ejemplo, el intercambio descentralizado en el ecosistema de criptomonedas ha hecho un uso completo de la cadena de bloques como bus de datos para lograr un acoplamiento descentralizado, lo que es difícil de lograr directamente en el sistema financiero tradicional. Si desea admitir aplicaciones más complejas, solo necesita actualizar las transacciones de transferencia simples a transacciones de protocolo de aplicación para lograr menos permisos a nivel de aplicación, y este método es el menos invasivo para las aplicaciones existentes.
Este artículo analiza principalmente el BBR desde la perspectiva de la ecología y la aplicación. La seguridad del modo BBR y la interoperabilidad de los estados L1, L1.5 y L2 en el modo BBR se analizarán en detalle en artículos posteriores. Al final se adjuntan algunos enlaces relacionados, incluidos mis artículos históricos y las explicaciones de Based Rollup desde diferentes perspectivas por parte de amigos de Twitter.
Enlaces relacionados:
1. Stackable L2: una nueva solución de expansión de blockchain https://rooch.network/zh-CN/blog/stackable-l2
2. ¿Cómo debería realizarse la Capa 2 de Bitcoins? https://x.com/jolestar/status/1717358817992995120 Diseñé el plan inicial basándome en cómo L2 utiliza el estado y los datos en Bitcoin L1. Un amigo mencionó la solución Booster en los comentarios y finalmente la adopté en la práctica.
3. ¿La inscripción es un error o una característica? https://x.com/jolestar/status/1732711942563959185 Este artículo explica el valor de las inscripciones desde la perspectiva de cómo se construye la L2, incluido el problema de compatibilidad de incentivos entre L1 y L2.
4. Discusión sobre el Rollup Basado desde la perspectiva de la teoría de la sustracción @kerne l1 983 https://web3caff.com/zh/archives/108241
5. Artículo de @jason_chen 998 sobre el Rollup basado en https://x.com/jason_chen998/status/1799692331635048697
6. Informe de investigación de seguimiento basado en rollup https://research.web3caff.com/zh/archives/22719
Este artículo procede de Internet: Análisis en profundidad de Based Booster Rollup: antecedentes, práctica y perspectivas
Este artículo Hash (SHA 1): 8656ff83d95af1de9dab2b925597cf72c6f63c66 N.º: Lianyuan Security Knowledge N.º 032 Con el continuo desarrollo de la tecnología blockchain, la industria financiera está experimentando una transformación sin precedentes. En este contexto, ha surgido gradualmente un concepto emergente: PayFi (Payment Finance). Este término fue propuesto por primera vez por Lily Liu, presidenta de la Fundación Solana, en la conferencia EthCC 2024 para explorar un modelo financiero y de pago innovador. La visión de PayFi no es solo un sistema de pago basado en criptoMoneda, pero también espera proporcionar a los usuarios servicios financieros más seguros, rápidos y de menor costo a través de tecnología descentralizada combinada con el valor temporal de la moneda. 1. El concepto central de PayFi: el valor temporal del dinero y las finanzas descentralizadas ¿Qué es PayFi? Lily Liu mencionó que la motivación principal de PayFi es hacer realidad la visión original de Bitcoin…







