Gate Ventures: KI x Krypto vom Anfänger zum Meister (Teil 1)

Einführung
Die jüngste Entwicklung der KI-Branche wird von manchen als die vierte industrielle Revolution angesehen. Das Aufkommen großer Modelle hat die Effizienz verschiedener Branchen erheblich verbessert. Die Boston Consulting Group ist der Ansicht, dass GPT die Arbeitseffizienz der Vereinigten Staaten um etwa 20% verbessert hat. Gleichzeitig wird die Generalisierungsfähigkeit großer Modelle als neues Paradigma des Softwaredesigns angesehen. In der Vergangenheit bestand das Softwaredesign aus präzisem Code, aber jetzt besteht das Softwaredesign aus einem allgemeineren Rahmen großer Modelle, der in die Software eingebettet ist. Diese Software kann eine bessere Leistung aufweisen und ein breiteres Spektrum modaler Eingaben und Ausgaben unterstützen. Die Deep-Learning-Technologie hat der KI-Branche tatsächlich den vierten Wohlstand beschert, und dieser Trend hat sich auch auf die Kryptoindustrie ausgeweitet.

Rangfolge der GPT-Einführungsraten in verschiedenen Branchen, Quelle: Bain AI-Umfrage
In diesem Bericht werden wir die Entwicklungsgeschichte der KI-Branche, die Technologieklassifizierung und die Auswirkungen der Erfindung der Deep-Learning-Technologie auf die Branche ausführlich erörtern. Dann werden wir die vor- und nachgelagerten Elemente der Industriekette wie GPU, Cloud-Computing, Datenquellen, Edge-Geräte sowie deren Entwicklungsstatus und Trends im Bereich Deep Learning eingehend analysieren. Danach werden wir die Beziehung zwischen Krypto und der KI-Branche von Grund auf ausführlich erörtern und das Muster der KI-Industriekette im Zusammenhang mit Krypto herausarbeiten.
Geschichte der KI-Industrie
Die KI-Industrie begann in den 1950er Jahren. Um die Vision der künstlichen Intelligenz zu verwirklichen, haben Wissenschaft und Industrie in verschiedenen Epochen und Disziplinen viele Denkschulen zur Implementierung künstlicher Intelligenz entwickelt.
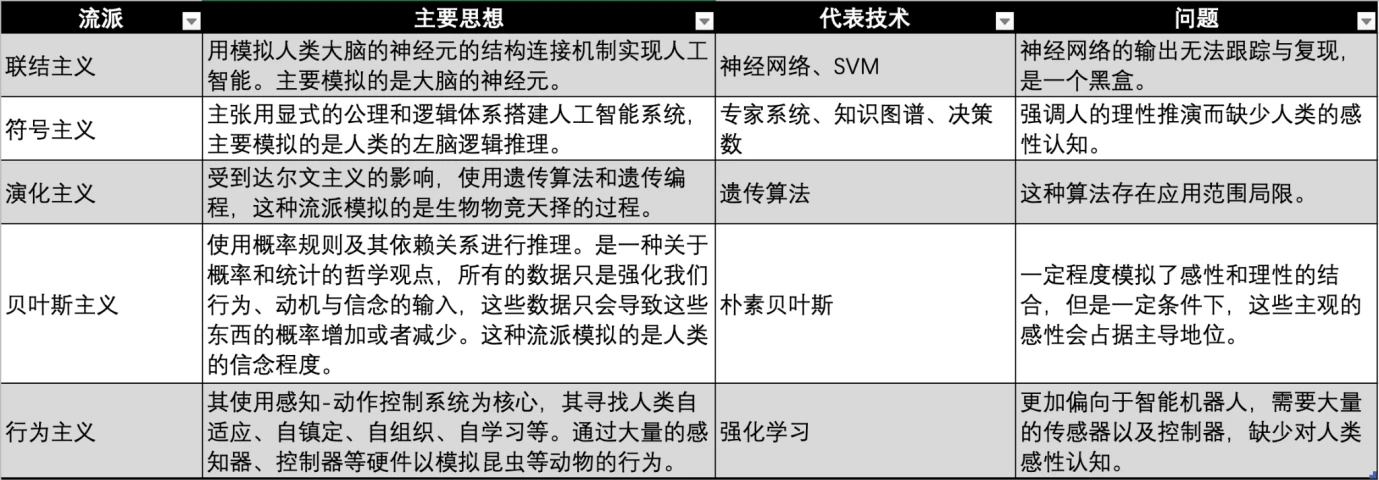
Vergleich von KI-Schulen, Quelle: Gate Ventures

KI/ML/DL-Beziehung, Quelle: Microsoft
In der modernen künstlichen Intelligenz wird hauptsächlich der Begriff „maschinelles Lernen“ verwendet. Das Konzept dieser Technologie besteht darin, dass die Maschine sich auf Daten stützt, um die Aufgabe wiederholt zu iterieren und so die Leistung des Systems zu verbessern. Die wichtigsten Schritte bestehen darin, Daten an den Algorithmus zu senden, diese Daten zum Trainieren des Modells zu verwenden, das Modell zu testen und bereitzustellen und das Modell zum Ausführen automatisierter Vorhersageaufgaben zu verwenden.
Derzeit gibt es drei große Schulen des maschinellen Lernens: Konnektionismus, Symbolismus und Behaviorismus, die das menschliche Nervensystem, Denken und Verhalten nachahmen.
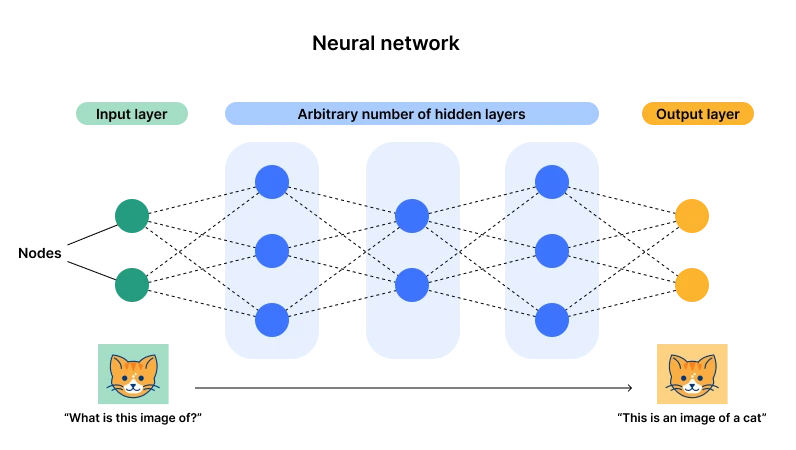
Illustration der Architektur eines neuronalen Netzwerks. Quelle: Cloudflare
Gegenwärtig hat der Konnektionismus, der durch neuronale Netzwerke repräsentiert wird, die Oberhand (auch als Deep Learning bekannt). Der Hauptgrund dafür ist, dass diese Architektur eine Eingabe- und eine Ausgabeschicht, aber mehrere versteckte Schichten hat. Sobald die Anzahl der Schichten und Neuronen (Parameter) groß genug ist, gibt es genügend Möglichkeiten, um komplexe Allzweckaufgaben zu erfüllen. Durch Dateneingabe können die Parameter der Neuronen ständig angepasst werden, und schließlich erreicht das Neuron nach vielen Daten einen optimalen Zustand (Parameter). Das ist das, was wir mit großem Aufwand Wunder nennen, und hieraus stammt auch das Wort Tiefe – genügend Schichten und Neuronen.
Beispielsweise können wir einfach verstehen, dass wir eine Funktion konstruiert haben. Wenn wir X = 2 eingeben, ist Y = 3; wenn X = 3 ist, ist Y = 5. Wenn diese Funktion alle X verarbeiten soll, müssen wir den Grad dieser Funktion und ihre Parameter hinzufügen. Beispielsweise kann ich eine Funktion konstruieren, die diese Bedingung als Y = 2 X -1 erfüllt. Wenn jedoch die Daten X = 2, Y = 11 vorliegen, müssen wir eine Funktion rekonstruieren, die für diese drei Datenpunkte geeignet ist. Wenn wir die GPU zum Knacken mit roher Gewalt verwenden, stellen wir fest, dass Y = X 2 -3 X + 5 besser geeignet ist, aber es muss sich nicht vollständig mit den Daten überschneiden. Es muss nur das Gleichgewicht und eine ungefähr ähnliche Ausgabe einhalten. Hier stellen X 2 und X, X 0 alle unterschiedliche Neuronen dar und 1, -3, 5 sind ihre Parameter.
Wenn wir an diesem Punkt eine große Datenmenge in das neuronale Netzwerk eingeben, können wir Neuronen hinzufügen und Parameter iterieren, um sie an die neuen Daten anzupassen. Auf diese Weise können wir alle Daten anpassen.
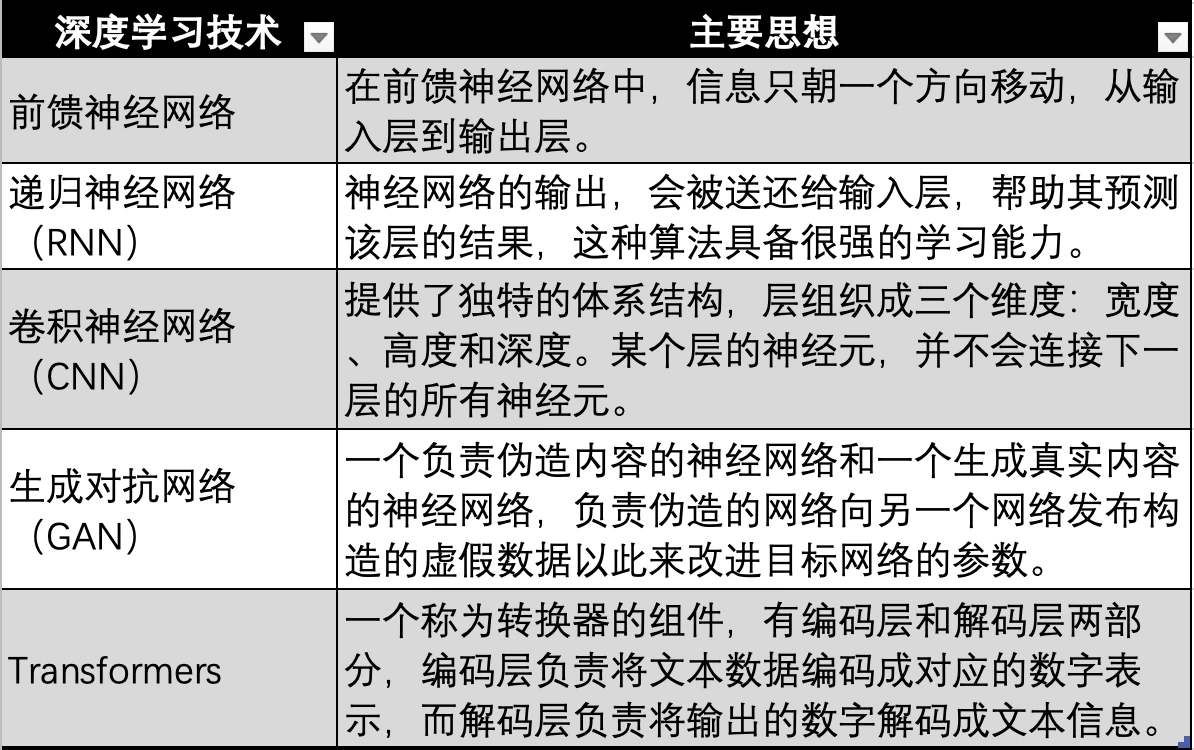
Entwicklung der Deep-Learning-Technologie, Quelle: Gate Ventures
Auch die auf neuronalen Netzwerken basierende Deep-Learning-Technologie hat mehrere technische Iterationen und Entwicklungen durchlaufen, wie beispielsweise die frühesten neuronalen Netzwerke, die in der obigen Abbildung dargestellt sind, Feedforward-neuronale Netzwerke, RNNs, CNNs, GANs und schließlich die Transformer-Technologie, die in modernen großen Modellen wie GPT verwendet wird. Die Transformer-Technologie ist nur eine Entwicklungsrichtung neuronaler Netzwerke, wobei ein zusätzlicher Transformer (Transformer) verwendet wird, um Daten aller Modalitäten (wie Audio, Video, Bilder usw.) zur Darstellung in entsprechende numerische Werte zu kodieren. Dann werden die Daten in das neuronale Netzwerk eingegeben, sodass das neuronale Netzwerk jede Art von Daten verarbeiten kann, d. h. Multimodalität erreicht wird.
Die Entwicklung der KI hat drei technologische Wellen durchlaufen. Die erste Welle fand in den 1960er Jahren statt, zehn Jahre nach der Einführung der KI-Technologie. Diese Welle wurde durch die Entwicklung der symbolischen Technologie ausgelöst, die die Probleme der allgemeinen Verarbeitung natürlicher Sprache und des Mensch-Computer-Dialogs löste. Gleichzeitig wurde das Expertensystem geboren. Dabei handelt es sich um das DENRAL-Expertensystem, das von der Stanford University unter Aufsicht der NASA fertiggestellt wurde. Das System verfügt über sehr fundierte chemische Kenntnisse und kann aus Fragen Schlussfolgerungen ziehen, um dieselben Antworten zu generieren wie Chemieexperten. Dieses chemische Expertensystem kann als Kombination aus einer chemischen Wissensbasis und einem Inferenzsystem betrachtet werden.
Nach dem Expertensystem schlug der israelisch-amerikanische Wissenschaftler und Philosoph Judea Pearl in den 1990er Jahren das Bayes-Netzwerk vor, das auch als Glaubensnetzwerk bekannt ist. Zur gleichen Zeit schlug Brooks die verhaltensbasierte Robotik vor und markierte damit die Geburt des Behaviorismus.
1997 besiegte IBMs Deep Blue den Schachmeister Kasparow mit 3,5:2,5. Dieser Sieg galt als Meilenstein der künstlichen Intelligenz und läutete damit den zweiten Höhepunkt der Entwicklung der KI-Technologie ein.
Die dritte Welle der KI-Technologie fand 2006 statt. Yann LeCun, Geoffrey Hinton und Yoshua Bengio, drei Giganten des Deep Learning, schlugen das Konzept des Deep Learning vor, einen Algorithmus, der künstliche neuronale Netzwerke als Rahmen verwendet, um Daten darzustellen und zu lernen. Danach entwickelten sich die Deep-Learning-Algorithmen allmählich weiter, von RNN, GAN zu Transformer und Stable Diffusion. Diese beiden Algorithmen prägten gemeinsam diese dritte Technologiewelle, und dies war auch die Blütezeit des Konnektionismus.
Im Zuge der Erforschung und Weiterentwicklung der Deep-Learning-Technologie sind zahlreiche bahnbrechende Ereignisse eingetreten, darunter:
● 2011 besiegte IBMs Watson die Menschen und gewann die Meisterschaft in der Quizshow „Jeopardy“.
● 2014 schlug Goodfellow ein GAN (Generative Adversarial Network) vor, das realistische Fotos erzeugen kann, indem zwei neuronale Netzwerke miteinander konkurrieren. Gleichzeitig schrieb Goodfellow auch ein Buch mit dem Titel „Deep Learning“, eines der wichtigsten Einführungsbücher auf dem Gebiet des Deep Learning.
● 2015 schlugen Hinton et al. in der Zeitschrift Nature einen Deep-Learning-Algorithmus vor. Die Einführung dieser Deep-Learning-Methode löste in Wissenschaft und Industrie sofort eine enorme Resonanz aus.
● Im Jahr 2015 wurde OpenAI gegründet und Musk, YC-Präsident Altman, der Angel-Investor Peter Thiel und andere kündigten eine gemeinsame Investition von $1 Milliarden US-Dollar an.
● Im Jahr 2016 trat AlphaGo, das auf Deep-Learning-Technologie basiert, in einem Mensch-Maschine-Go-Kampf gegen den Go-Weltmeister und professionellen 9.-Dan-Spieler Lee Sedol an und gewann mit einem Gesamtergebnis von 4 zu 1.
● 2017 wurde Sophia, ein humanoider Roboter, der von Hanson Robotics in Hongkong, China, entwickelt wurde, als erster Roboter in der Geschichte bezeichnet, dem die Staatsbürgerschaft erster Klasse verliehen wurde. Er verfügt über ausdrucksstarke Gesichtsausdrücke und die Fähigkeit, die menschliche Sprache zu verstehen.
● Im Jahr 2017 veröffentlichte Google, das über reichlich Talent und technische Reserven im Feld der künstlichen Intelligenz verfügt, das Papier „Attention is all you need“ und schlug den Transformer-Algorithmus vor, und groß angelegte Sprachmodelle begannen aufzutauchen.
● Im Jahr 2018 veröffentlichte OpenAI GPT (Generative Pre-trained Transformer), das auf dem Transformer-Algorithmus basierte und damals eines der größten Sprachmodelle war.
● Im Jahr 2018 veröffentlichte das Google-Team Deepmind das auf Deep Learning basierende AlphaGo, das in der Lage ist, Proteinstrukturen vorherzusagen und als Zeichen für große Fortschritte auf dem Gebiet der künstlichen Intelligenz gilt.
● 2019 veröffentlichte OpenAI GPT-2, ein Modell mit 1,5 Milliarden Parametern.
● Im Jahr 2020 entwickelte OpenAI GPT-3, das 175 Milliarden Parameter umfasst, 100-mal mehr als die vorherige Version GPT-2. Das Modell verwendete 570 GB Text für das Training und kann bei mehreren NLP-Aufgaben (Natural Language Processing) (Beantworten von Fragen, Übersetzen und Schreiben von Artikeln) eine hochmoderne Leistung erzielen.
● Im Jahr 2021 veröffentlichte OpenAI GPT-4, ein Modell mit 1,76 Billionen Parametern, zehnmal so viel wie GPT-3.
● Im Januar 2023 wurde die auf dem GPT-4-Modell basierende ChatGPT-Anwendung eingeführt. Im März erreichte ChatGPT 100 Millionen Benutzer und war damit die Anwendung, die am schnellsten 100 Millionen Benutzer in der Geschichte erreichte.
● Im Jahr 2024 führte OpenAI GPT-4 Omni ein.
Deep-Learning-Industriekette
Derzeit verwenden alle großen Modellsprachen Deep-Learning-Methoden, die auf neuronalen Netzwerken basieren. Große Modelle, angeführt von GPT, haben eine Welle des künstlichen Intelligenz-Hypes ausgelöst, und eine große Anzahl von Akteuren ist in dieses Feld eingestiegen. Wir haben auch festgestellt, dass die Marktnachfrage nach Daten und Rechenleistung explodiert ist. Daher untersuchen wir in diesem Teil des Berichts hauptsächlich die industrielle Kette der Deep-Learning-Algorithmen, wie sich die Upstream- und Downstream-Branche der von Deep-Learning-Algorithmen dominierten KI-Branche zusammensetzen, wie der aktuelle Status und das Verhältnis von Angebot und Nachfrage der Upstream- und Downstream-Branche aussehen und wie die zukünftige Entwicklung aussehen wird.

GPT-Trainingspipeline Quelle: WaytoAI
Zunächst müssen wir uns darüber im Klaren sein, dass das Training von LLMs (großen Modellen) unter der Leitung von GPT auf Basis der Transformer-Technologie in drei Schritte unterteilt ist.
Da der Konverter auf Transformer basiert, muss er vor dem Training die Texteingabe in numerische Werte umwandeln. Dieser Vorgang wird als Tokenisierung bezeichnet, und diese numerischen Werte werden dann als Token bezeichnet. Als Faustregel gilt, dass ein englisches Wort oder Zeichen ungefähr als ein Token und jedes chinesische Zeichen ungefähr als zwei Token angesehen werden kann. Dies ist auch die Grundeinheit für die GPT-Preisgestaltung.
Der erste Schritt ist das Vortraining. Indem wir der Eingabeebene genügend Datenpaare geben, ähnlich wie im Beispiel (X, Y) im ersten Teil des Berichts, können wir die besten Parameter für jedes Neuron im Modell finden. Dies erfordert viele Daten, und dieser Prozess ist auch der rechenintensivste Prozess, da die Neuronen wiederholt iteriert werden müssen, um verschiedene Parameter auszuprobieren. Nachdem ein Stapel Datenpaare trainiert wurde, wird im Allgemeinen derselbe Stapel Daten für das sekundäre Training verwendet, um die Parameter zu iterieren.
Der zweite Schritt ist die Feinabstimmung. Bei der Feinabstimmung wird eine kleine Menge qualitativ hochwertiger Daten für das Training bereitgestellt. Diese Änderung führt zu einer höheren Qualität der Modellausgabe, da für das Vortraining eine große Datenmenge erforderlich ist, viele Daten jedoch falsch oder von geringer Qualität sein können. Der Feinabstimmungsschritt kann die Qualität des Modells durch qualitativ hochwertige Daten verbessern.
Der dritte Schritt ist das bestärkende Lernen. Zuerst erstellen wir ein neues Modell, das wir Belohnungsmodell nennen. Der Zweck dieses Modells ist sehr einfach: Es dient zum Sortieren der Ausgabeergebnisse. Daher ist die Implementierung dieses Modells relativ einfach, da das Geschäftsszenario relativ vertikal ist. Verwenden Sie dann dieses Modell, um zu bestimmen, ob die Ausgabe unseres großen Modells von hoher Qualität ist, sodass ein Belohnungsmodell verwendet werden kann, um die Parameter des großen Modells automatisch zu iterieren. (Manchmal ist jedoch auch menschliches Eingreifen erforderlich, um die Ausgabequalität des Modells zu beurteilen.)
Kurz gesagt, im Trainingsprozess großer Modelle stellt das Vortraining sehr hohe Anforderungen an die Datenmenge und verbraucht die meiste GPU-Rechenleistung, während für die Feinabstimmung qualitativ hochwertigere Daten erforderlich sind, um die Parameter zu verbessern. Beim Reinforcement Learning können Parameter wiederholt durch ein Belohnungsmodell iteriert werden, um qualitativ hochwertigere Ergebnisse auszugeben.
Während des Trainings gilt: Je mehr Parameter vorhanden sind, desto höher ist die Obergrenze der Generalisierungsfähigkeit. Im Beispiel der Funktion Y = aX + b gibt es beispielsweise tatsächlich zwei Neuronen X und X 0. Daher sind die anpassbaren Daten, egal wie sich die Parameter ändern, äußerst begrenzt, da sie im Wesentlichen immer noch eine gerade Linie sind. Wenn mehr Neuronen vorhanden sind, können mehr Parameter iteriert und mehr Daten angepasst werden. Aus diesem Grund wirken große Modelle Wunder, und deshalb werden sie auch oft als große Modelle bezeichnet. Im Wesentlichen handelt es sich dabei um riesige Zahlen von Neuronen und Parametern, riesige Datenmengen und riesige Rechenleistung.
Daher, Die Leistung großer Modelle wird hauptsächlich von drei Aspekten bestimmt: Anzahl der Parameter, Menge und Qualität der Daten sowie Rechenleistung. Diese drei Faktoren wirken sich zusammen auf die Qualität der Ergebnisse und die Generalisierungsfähigkeit großer Modelle aus. Wir gehen davon aus, dass die Anzahl der Parameter p und die Datenmenge n ist (berechnet anhand der Anzahl der Token). Dann können wir die erforderliche Rechenleistung anhand allgemeiner Faustregeln berechnen, sodass wir abschätzen können, wie viel Rechenleistung wir kaufen müssen und wie viel Trainingszeit wir benötigen.
Die Rechenleistung wird im Allgemeinen in Flops gemessen, was eine Gleitkommaoperation darstellt. Gleitkommaoperationen sind ein allgemeiner Begriff für Addition, Subtraktion, Multiplikation und Division von nicht ganzzahligen Zahlen, wie z. B. 2,5 + 3,557. Gleitkomma stellt die Fähigkeit dar, Dezimalstellen zu übertragen, während FP 16 die Genauigkeit darstellt, die Dezimalstellen unterstützt, und FP 32 im Allgemeinen eine gängigere Genauigkeit ist. Gemäß der Faustregel in der Praxis erfordert das einmalige (normalerweise mehrere) Vortraining eines großen Modells etwa 6 np Flops, und 6 wird als Industriekonstante bezeichnet. Die Inferenz (der Vorgang der Eingabe von Daten und des Wartens auf die Ausgabe des großen Modells) ist in zwei Teile unterteilt, die Eingabe von n Token und die Ausgabe von n Token, sodass insgesamt etwa 2 np Flops erforderlich sind.
Anfangs wurden CPU-Chips verwendet, um Rechenleistung für das Training bereitzustellen, später wurden jedoch nach und nach GPUs verwendet, beispielsweise Nvidias A100- und H100-Chips. Denn CPUs existieren als Allzweckrechner, GPUs können jedoch für dedizierte Rechner verwendet werden und ihre Energieeffizienz übertrifft die von CPUs bei weitem. GPUs führen Gleitkommaoperationen hauptsächlich über ein Modul namens Tensor Core aus. Daher verfügen allgemeine Chips über Flops-Daten mit einer Genauigkeit von unter FP16/FP32, was ihre Hauptrechenleistung darstellt und auch einer der Hauptmessindikatoren für Chips ist.

Spezifikationen des Nvidia A100 Chips, Quelle: Nvidia
Daher sollten die Leser in der Lage sein, die Chipeinführungen dieser Unternehmen zu verstehen. Wie in der obigen Abbildung gezeigt, ist im Vergleich der Nvidia A100 80 GB PCIe- und SXM-Modelle ersichtlich, dass PCIe und SXM unter Tensor Core (einem Modul, das speziell zur Berechnung von KI verwendet wird) bei FP16-Präzision 312 TFLOPS bzw. 624 TFLOPS (Billionen Flops) betragen.
Angenommen, unsere großen Modellparameter nehmen GPT 3 als Beispiel, es gibt 175 Milliarden Parameter und 180 Milliarden Token an Daten (etwa 570 GB), dann erfordert ein Vortraining 6 np Flops, also etwa 3,15*1022 Flops. Wenn TFLOPS (Billionen FLOPs) als Einheit verwendet werden, sind es etwa 3,15*1010 TFLOPS, was bedeutet, dass ein SXM-Chip etwa 50480769 Sekunden, 841346 Minuten, 14022 Stunden und 584 Tage braucht, um GPT 3 einmal vorzutrainieren.
Wir können sehen, dass dies eine extrem große Rechenleistung ist. Es erfordert die Zusammenarbeit mehrerer hochmoderner Chips, um das Vortraining zu erreichen. Darüber hinaus ist die Anzahl der Parameter von GPT 4 zehnmal so hoch wie die von GPT 3 (1,76 Billionen), was bedeutet, dass selbst bei unveränderter Datenmenge die Anzahl der Chips zehnmal mehr gekauft werden muss. Darüber hinaus beträgt die Anzahl der Token von GPT-4 13 Billionen, was zehnmal so hoch ist wie die von GPT-3. Letztendlich kann GPT-4 mehr als die 100-fache Rechenleistung des Chips erfordern.
Beim Training großer Modelle ist auch unsere Datenspeicherung problematisch, da unsere Daten, wie z. B. die Anzahl der GPT 3-Token, 180 Milliarden betragen, was etwa 570 GB Speicherplatz belegt, und das neuronale Netzwerk mit 175 Milliarden Parametern des großen Modells etwa 700 GB Speicherplatz belegt. Der Speicherplatz der GPU ist im Allgemeinen klein (z. B. 80 GB für A 100, wie in der obigen Abbildung dargestellt). Wenn der Speicherplatz diese Daten nicht aufnehmen kann, muss die Bandbreite des Chips untersucht werden, d. h. die Geschwindigkeit der Datenübertragung von der Festplatte zum Speicher. Da wir nicht nur einen Chip verwenden, müssen wir gleichzeitig die gemeinsame Lernmethode verwenden, um ein großes Modell gemeinsam auf mehreren GPU-Chips zu trainieren, was die Übertragungsrate der GPU zwischen den Chips betrifft. Daher sind in vielen Fällen die Faktoren oder Kosten, die die endgültige Modelltrainingspraxis einschränken, nicht unbedingt die Rechenleistung des Chips, sondern häufiger die Bandbreite des Chips. Da die Datenübertragung langsam ist, führt dies zu einer längeren Ausführungszeit des Modells und höheren Stromkosten.

H100 SXM Chip Spezifikation, Quelle: Nvidia
An dieser Stelle können die Leser die Chipspezifikationen grob verstehen. FP 16 steht für Präzision. Da das Training von KI-LLMs hauptsächlich die Tensor Core-Komponente verwendet, müssen wir uns nur die Rechenleistung dieser Komponente ansehen. FP 64 Tensor Core bedeutet, dass der H 100 SXM 67 TFLOPS pro Sekunde bei 64 Präzision verarbeiten kann. GPU-Speicher bedeutet, dass der Chip nur 64 GB Speicher hat, was den Datenspeicheranforderungen großer Modelle überhaupt nicht gerecht wird. Daher bedeutet GPU-Speicherbandbreite die Datenübertragungsgeschwindigkeit, die beim H 100 SXM 3,35 TB/s beträgt.
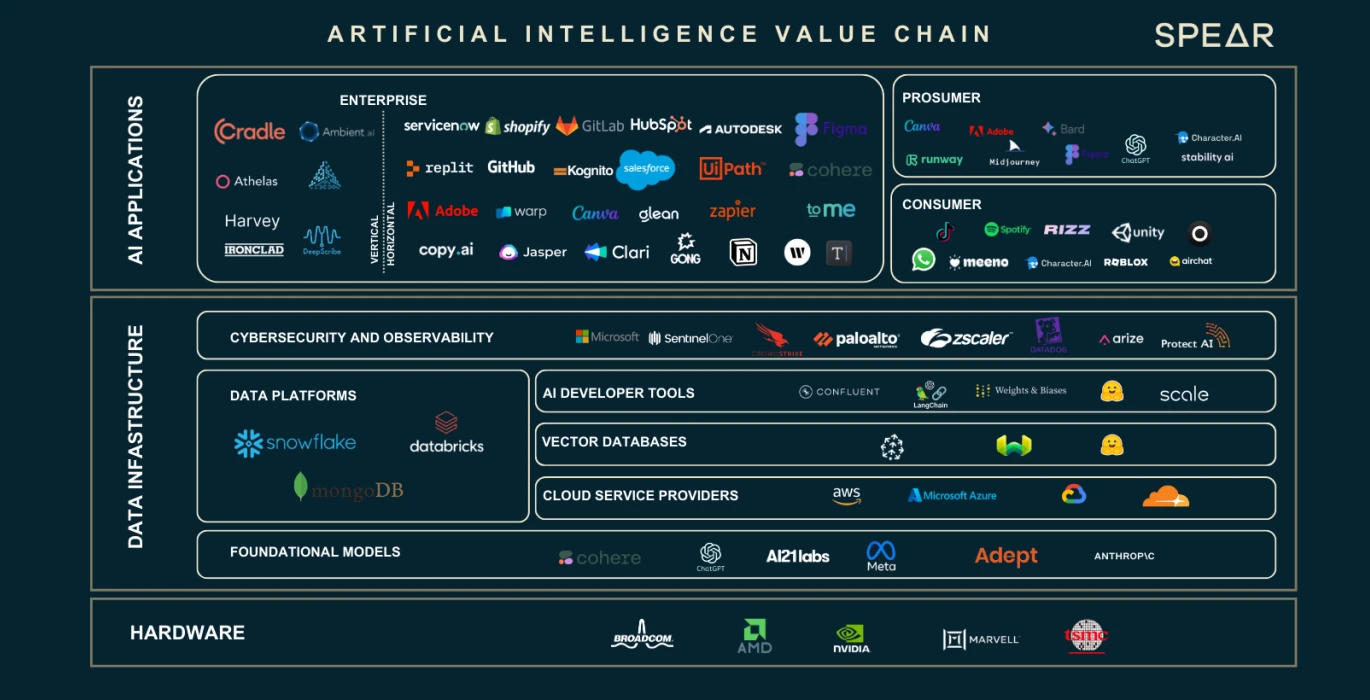
AI Value Chain, Quelle: Nasdaq
Wir haben gesehen, dass die Datenausweitung und die Anzahl der Neuronenparameter zu einer großen Lücke bei den Rechenleistungs- und Speicheranforderungen geführt haben. Diese drei Hauptfaktoren haben eine ganze Industriekette hervorgebracht. Wir werden die Rolle und Funktion jedes Teils der Industriekette anhand der obigen Abbildung vorstellen.
Anbieter von Hardware-GPUs
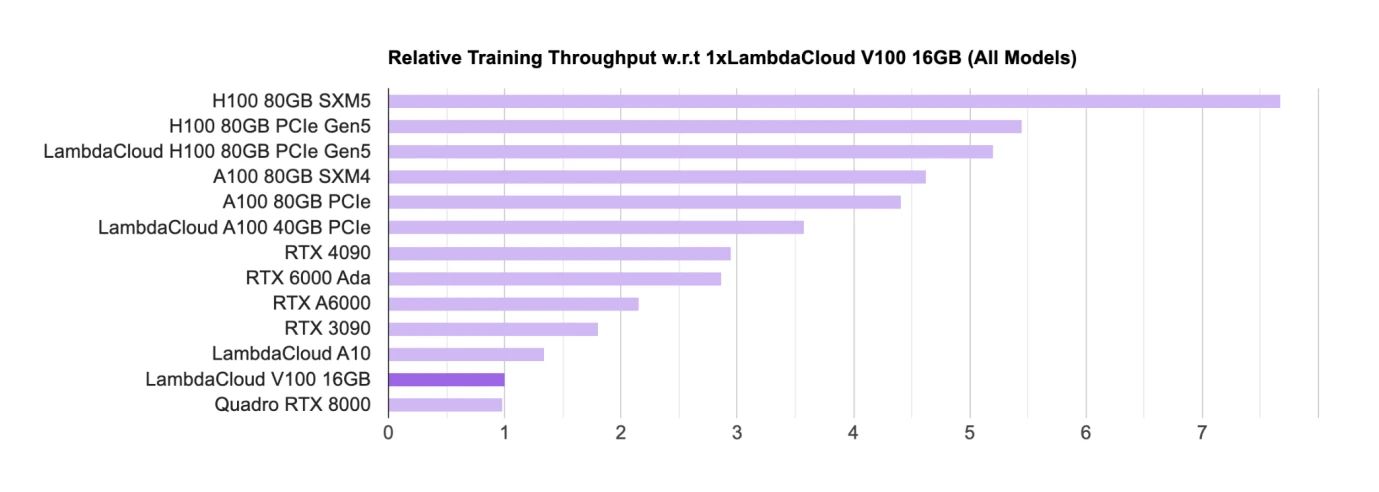
KI-GPU-Chip-Rankings, Quelle: Lambda
Hardware wie GPU ist der Hauptchip für Training und Argumentation. Nvidia nimmt derzeit eine absolute Spitzenposition unter den wichtigsten GPU-Chip-Designern ein. Die akademische Gemeinschaft (hauptsächlich Universitäten und Forschungseinrichtungen) verwendet hauptsächlich GPUs für Verbraucher (RTX, die wichtigste Gaming-GPU); die industrielle Gemeinschaft verwendet hauptsächlich H100, A100 usw. für die Kommerzialisierung großer Modelle.
Die Chips von Nvidia dominieren die Liste, und alle Chips stammen von Nvidia. Google hat auch einen eigenen KI-Chip namens TPU, aber TPU wird hauptsächlich von Google Cloud verwendet, um B-Side-Unternehmen Rechenleistungsunterstützung zu bieten. Selbst gekaufte Unternehmen bevorzugen im Allgemeinen immer noch den Kauf von Nvidias GPU.

H 100 GPU Kaufstatistik nach Unternehmen, Quelle: Omdia
Zahlreiche Unternehmen arbeiten an der Entwicklung von LLMs, darunter auch China, das über mehr als 100 große Modelle verfügt, und weltweit wurden mehr als 200 große Sprachmodelle veröffentlicht. Viele Internetgiganten nehmen an diesem KI-Boom teil. Diese Unternehmen kaufen entweder große Modelle selbst oder mieten sie über Cloud-Unternehmen. Im Jahr 2023 wurde Nvidias fortschrittlichster Chip H100 gleich nach seiner Veröffentlichung von vielen Unternehmen abonniert. Die weltweite Nachfrage nach H100-Chips übersteigt das Angebot bei weitem, da derzeit nur Nvidia die hochwertigsten Chips liefert und sein Lieferzyklus erstaunliche 52 Wochen erreicht hat.
Angesichts der Monopolstellung von Nvidia übernahm Google als einer der absoluten Marktführer im Bereich künstliche Intelligenz die Führung bei der Gründung der CUDA Alliance mit Intel, Qualcomm, Microsoft und Amazon, in der Hoffnung, durch die gemeinsame Entwicklung von GPUs Nvidia‘s absoluten Einfluss auf die Deep-Learning-Industriekette loszuwerden.
Supergroße Technologieunternehmen/Cloud-Service-Provider/nationale Laboratorien kaufen oft Tausende oder Zehntausende H100-Chips, um HPC (High-Performance Computing Centers) aufzubauen. Beispielsweise kaufte Teslas CoreWeave-Cluster 10.000 H100 80 GB-Chips mit einem durchschnittlichen Kaufpreis von $44.000 US-Dollar (Nvidias Kosten betragen etwa 1/10) und Gesamtkosten von $440 Millionen US-Dollar; Tencent kaufte 50.000 Chips; Meta kaufte 150.000 Chips. Bis Ende 2023 hat Nvidia als einziger Verkäufer von Hochleistungs-GPUs mehr als 500.000 H100-Chips bestellt.

Nvidia GPU-Produkt-Roadmap, Quelle: Techwire
In Bezug auf die Chipversorgung von Nvidia ist das Obige die Roadmap für die Produktiteration. Zum Zeitpunkt dieses Berichts wurden die Neuigkeiten zum H200 veröffentlicht. Es wird erwartet, dass die Leistung des H200 doppelt so hoch sein wird wie die des H100, und der B100 wird Ende 2024 oder Anfang 2025 auf den Markt kommen. Derzeit entspricht die Entwicklung der GPU noch dem Mooreschen Gesetz, wobei sich die Leistung alle zwei Jahre verdoppelt und der Preis um die Hälfte sinkt.
Cloud-Dienstanbieter

Arten von GPU-Cloud, Quelle: Salesforce Ventures
Nach dem Kauf einer ausreichenden Anzahl von GPUs zum Aufbau von HPC können Cloud-Service-Provider flexible Rechenleistung und verwaltete Trainingslösungen für KI-Unternehmen mit begrenzten Mitteln bereitstellen. Wie in der obigen Abbildung dargestellt, ist der aktuelle Markt hauptsächlich in drei Kategorien von Cloud-Computing-Anbietern unterteilt. Die erste Kategorie sind die ultragroßen Cloud-Computing-Plattformen, die von traditionellen Cloud-Anbietern (AWS, Google, Azure) vertreten werden. Die zweite Kategorie sind vertikale Cloud-Computing-Plattformen, die hauptsächlich für KI oder Hochleistungsrechnen eingesetzt werden. Sie bieten professionellere Dienste, sodass im Wettbewerb mit den Giganten immer noch ein gewisser Marktraum besteht. Zu diesen aufstrebenden vertikalen Cloud-Service-Unternehmen der Branche gehören CoreWeave (Finanzierung in Höhe von 100 Billionen US-Dollar in der C-Runde mit einer Bewertung von 19 Billionen US-Dollar), Crusoe, Lambda (Finanzierung in Höhe von 100 Billionen US-Dollar in der C-Runde mit einer Bewertung von mehr als 100 Billionen US-Dollar) usw. Die dritte Art von Cloud-Service-Providern sind neu entstandene Marktteilnehmer, hauptsächlich Inference-as-a-Service-Anbieter. Diese Serviceanbieter mieten GPUs von Cloud-Service-Providern. Diese Art von Dienstleistern stellt hauptsächlich vorab trainierte Modelle für Kunden bereit und führt Feinabstimmungen oder Inferenzen an ihnen durch. Repräsentative Unternehmen in diesem Markt sind Together.ai (aktuelle Bewertung: $1,25 Milliarden US-Dollar), Fireworks.ai (angeführt von Benchmark, $25 Millionen US-Dollar in der Serie-A-Finanzierung) usw.
Trainingsdatenquelle Anbieter
Wie im vorherigen Teil unseres zweiten Abschnitts erwähnt, durchläuft das Training großer Modelle hauptsächlich drei Schritte, nämlich Vortraining, Feinabstimmung und bestärkendes Lernen. Das Vortraining erfordert eine große Datenmenge und die Feinabstimmung erfordert qualitativ hochwertige Daten. Daher haben Suchmaschinen wie Google (mit einer großen Datenmenge) und Datenunternehmen wie Reddit (hochwertige Dialogdaten) große Aufmerksamkeit vom Markt erhalten.
Um die Konkurrenz durch allgemeine Großmodelle wie GPT zu vermeiden, entscheiden sich manche Entwickler für die Entwicklung in Nischenbereichen, sodass die Datenanforderungen branchenspezifisch werden, wie etwa in den Bereichen Finanzen, Medizin, Chemie, Physik, Biologie, Bilderkennung usw. Dies sind Modelle für bestimmte Bereiche und erfordern Daten in bestimmten Bereichen. Daher gibt es Unternehmen, die Daten für diese Großmodelle bereitstellen. Wir können sie auch als Datenlabeling-Unternehmen bezeichnen, was bedeutet, dass sie die Daten nach der Erfassung labeln und bessere Qualität und spezifische Datentypen bereitstellen.
Für Unternehmen, die sich mit der Modellentwicklung beschäftigen, sind große Datenmengen, qualitativ hochwertige Daten und spezifische Daten die drei wichtigsten Datenanforderungen.

Große Datenkennzeichnungsunternehmen, Quelle: Risikoradar
Eine Studie von Microsoft kommt zu dem Schluss, dass die Leistung von SLMs (Small Language Models) nicht unbedingt schlechter sein muss als die von LLMs, wenn ihre Datenqualität deutlich besser ist als die von Large Language Models. Tatsächlich hat GPT keinen klaren Vorteil in Bezug auf Originalität und Daten. Sein Erfolg ist hauptsächlich auf seinen Mut zurückzuführen, in diese Richtung zu setzen. Sequoia Capital räumte auch ein, dass GPT seinen Wettbewerbsvorteil in Zukunft möglicherweise nicht aufrechterhalten kann, da es derzeit in dieser Hinsicht keinen tiefen Schutzgraben hat und die Hauptbeschränkung darin liegt, dass es nur begrenzt Rechenleistung erwerben kann.
Was die Datenmenge betrifft, werden laut EpochAIs Vorhersage alle Daten von niedriger und hoher Qualität im Jahr 2030 erschöpft sein, basierend auf dem aktuellen Wachstum des Modellmaßstabs. Daher erforscht die Branche derzeit synthetische Daten künstlicher Intelligenz, sodass unbegrenzte Daten generiert werden können. Der Engpass ist dann nur noch die Rechenleistung. Diese Richtung befindet sich noch in der Erkundungsphase und verdient die Aufmerksamkeit der Entwickler.
Datenbankanbieter
Wir haben Daten, aber die Daten müssen auch gespeichert werden, normalerweise in einer Datenbank, die das Hinzufügen, Löschen, Ändern und Abfragen von Daten erleichtert. Im traditionellen Internetgeschäft haben wir vielleicht von MySQL gehört, und im Ethereum-Client Reth haben wir von Redis gehört. Dies sind lokale Datenbanken, in denen wir Geschäftsdaten oder Blockchain-Daten speichern. Verschiedene Datenbanken sind für verschiedene Datentypen oder Unternehmen angepasst.
Für KI-Daten und Deep-Learning-Trainings- und Argumentationsaufgaben wird in der Branche derzeit eine sogenannte Vektordatenbank verwendet. Vektordatenbanken sind darauf ausgelegt, große Mengen hochdimensionaler Vektordaten effizient zu speichern, zu verwalten und zu indizieren. Da unsere Daten nicht einfach nur numerisch oder textlich sind, sondern große Mengen unstrukturierter Daten wie Bilder und Töne, können Vektordatenbanken diese unstrukturierten Daten in einer einheitlichen Form von Vektoren speichern und eignen sich für die Speicherung und Verarbeitung dieser Vektoren.

Vektordatenbank-Klassifizierung, Quelle: Yingjun Wu
Zu den Hauptakteuren zählen derzeit Chroma (erhielt $18 Millionen an Finanzierung), Zilliz (erhielt $60 Millionen in der letzten Finanzierungsrunde), Pinecone, Weaviate usw. Wir erwarten, dass mit der steigenden Nachfrage nach Datenvolumen und der Entstehung großer Modelle und Anwendungen in verschiedenen Segmenten die Nachfrage nach Vektordatenbanken deutlich steigen wird. Und da dieser Bereich starke technische Barrieren aufweist, ziehen wir bei Investitionen eher reife Unternehmen mit Kunden in Betracht.
Edge-Geräte
Beim Einrichten eines GPU-HPC (High-Performance Computing Cluster) wird normalerweise viel Energie verbraucht, wodurch viel Wärmeenergie erzeugt wird. In einer Umgebung mit hohen Temperaturen begrenzt der Chip seine Laufgeschwindigkeit, um die Temperatur zu senken. Dies wird allgemein als Drosselung bezeichnet. Dies erfordert einige Kühlrandgeräte, um den kontinuierlichen Betrieb des HPC sicherzustellen.
Es sind also zwei Richtungen der industriellen Kette beteiligt, nämlich die Energieversorgung (im Allgemeinen mittels Strom) und die Kühlanlage.
Derzeit wird hauptsächlich Strom für die Energieversorgung verwendet, und Rechenzentren und unterstützende Netzwerke machen derzeit 21 bis 31 Milliarden Tonnen des weltweiten Stromverbrauchs aus. BCG prognostiziert, dass sich der zum Trainieren großer Modelle benötigte Strom mit der Zunahme der Parameter großer Deep-Learning-Modelle und der Iteration von Chips bis 2030 verdreifachen wird. Derzeit investieren in- und ausländische Technologieunternehmen aktiv in Energieunternehmen, und die wichtigsten Energieinvestitionsrichtungen umfassen Geothermie, Wasserstoffenergie, Batteriespeicherung und Kernenergie.
In Bezug auf die Wärmeableitung von HPC-Clustern ist Luftkühlung derzeit die Hauptmethode, aber viele VCs investieren stark in Flüssigkeitskühlsysteme, um den reibungslosen Betrieb von HPC aufrechtzuerhalten. Jetcool behauptet beispielsweise, dass sein Flüssigkeitskühlsystem den Gesamtstromverbrauch des H100-Clusters um 151 TP9T senken kann. Derzeit wird die Flüssigkeitskühlung hauptsächlich in drei Forschungsrichtungen unterteilt: Kaltplatten-Flüssigkeitskühlung, Immersions-Flüssigkeitskühlung und Sprüh-Flüssigkeitskühlung. Zu den Unternehmen in diesem Bereich gehören: Huawei, Green Revolution Cooling, SGI usw.
Anwendung
Die aktuelle Entwicklung von KI-Anwendungen ähnelt der Entwicklung der Blockchain-Branche. Als innovative Branche wurde Transformer 2017 vorgeschlagen und OpenAI bestätigte 2023 die Wirksamkeit großer Modelle. Daher drängen sich viele Fomo-Unternehmen derzeit in der Forschung und Entwicklung großer Modelle, d. h. die Infrastruktur ist sehr überfüllt, aber die Anwendungsentwicklung hat nicht Schritt gehalten.

Top 50 der monatlich aktiven Benutzer, Quelle: A16Z
Derzeit waren die meisten der in den ersten zehn Monaten aktiven KI-Anwendungen Suchanwendungen. Die Anzahl der tatsächlich erschienenen KI-Anwendungen ist noch sehr begrenzt und die Anwendungstypen sind relativ einheitlich. Es gibt keine sozialen und anderen Arten von Anwendungen, die es erfolgreich geschafft haben.
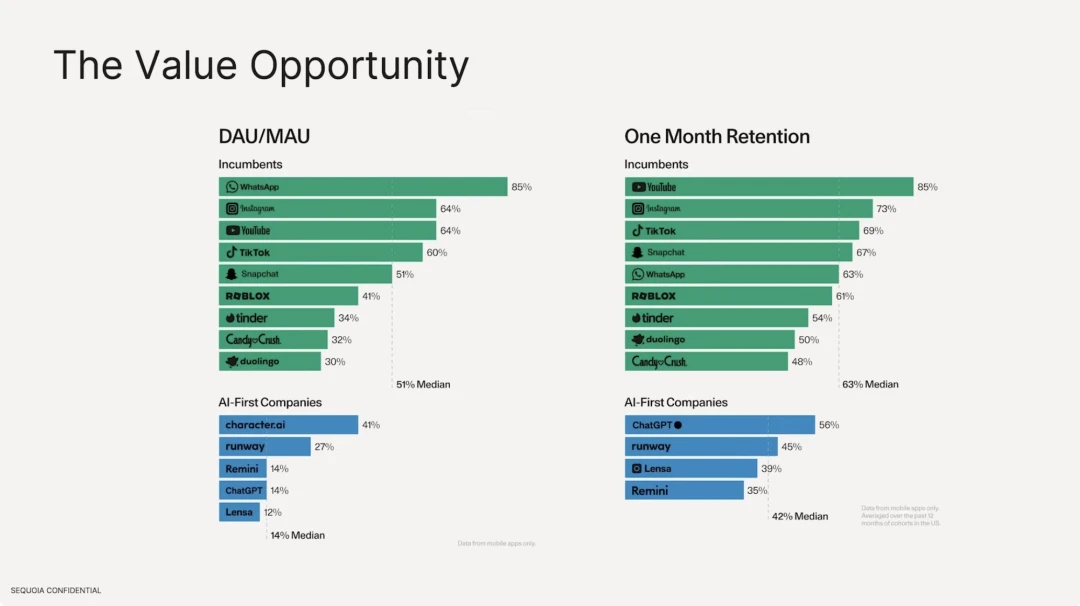
Wir haben auch festgestellt, dass die Bindungsrate von KI-Anwendungen, die auf großen Modellen basieren, viel niedriger ist als die von bestehenden traditionellen Internetanwendungen. In Bezug auf die Anzahl aktiver Benutzer beträgt der Medianwert traditioneller Internetsoftware 511 TP9T, wobei WhatsApp mit seiner starken Benutzerbindung am höchsten ist. Auf der KI-Anwendungsseite hat character.ai jedoch mit nur 411 TP9T die höchste DAU/MAU, und die DAU macht 141 TP9T der mittleren Anzahl der Gesamtbenutzer aus. In Bezug auf die Benutzerbindungsrate sind YouTube, Instagram und Tiktok die besten traditionellen Internetsoftwares, wobei die mittlere Bindungsrate der Top Ten 631 TP9T beträgt. Im Vergleich dazu beträgt die Bindungsrate von ChatGPT nur 561 TP9T.

KI-Anwendungslandschaft, Quelle: Mammutbaum
Laut einem Bericht von Sequoia Capital USA werden die Anwendungen je nach Zielgruppe in drei Kategorien unterteilt: professionelle Verbraucher, Unternehmen und normale Verbraucher.
1. Verbraucherorientiert: Wird im Allgemeinen zur Verbesserung der Produktivität verwendet, z. B. Textarbeiter, die GPT für Fragen und Antworten verwenden, automatisierte 3D-Rendering-Modellierung, Softwarebearbeitung, automatisierte Agenten und die Verwendung von Sprachanwendungen für Sprachkonversationen, Kameradschaft, Sprachübungen usw.
2. Unternehmensorientiert: in der Regel Branchen wie Marketing, Recht und medizinisches Design.
Obwohl viele Leute jetzt kritisieren, dass Infrastruktur weitaus wichtiger ist als Anwendungen, glauben wir tatsächlich, dass die moderne Welt durch künstliche Intelligenz-Technologie weitgehend umgestaltet wurde. Allerdings werden Empfehlungssysteme verwendet, darunter ByteDances Tiktok, Toutiao, Soda Music usw. sowie Xiaohongshu und WeChat Video Account, Werbeempfehlungstechnologie usw., die maßgeschneiderte Empfehlungen für Einzelpersonen sind, die alle zu Algorithmen des maschinellen Lernens gehören. Daher repräsentiert das derzeit boomende Deep Learning nicht vollständig die KI-Branche. Es gibt viele potenzielle Technologien, die die Möglichkeit haben, allgemeine künstliche Intelligenz zu erreichen, die parallel entwickelt werden, und einige dieser Technologien werden in verschiedenen Branchen weithin eingesetzt.
Welche Art von Beziehung hat sich also zwischen Krypto und KI entwickelt? Welche Projekte in der Wertschöpfungskette der Kryptoindustrie verdienen Aufmerksamkeit? Wir werden sie in Gate Ventures: KI x Krypto vom Anfänger zum Meister (Teil 2) nacheinander erläutern.
Haftungsausschluss:
Der obige Inhalt dient nur als Referenz und sollte nicht als Beratung angesehen werden. Bitte holen Sie immer professionellen Rat ein, bevor Sie eine Investition tätigen.
Über Gate Ventures
Gate Ventures ist der Risikokapitalzweig von Gate.io und konzentriert sich auf Investitionen in dezentrale Infrastrukturen, Ökosysteme und Anwendungen, die die Welt im Zeitalter des Web 3.0 neu gestalten werden. Gate Ventures arbeitet mit globalen Branchenführern zusammen, um Teams und Startups mit innovativem Denken und Fähigkeiten auszustatten, um soziale und finanzielle Interaktionsmodelle neu zu definieren.
Offizielle Website: https://ventures.gate.io/
Twitter: https://x.com/gate_ventures
Mittel: https://medium.com/gate_ventures
Dieser Artikel stammt aus dem Internet: Gate Ventures: KI x Krypto vom Anfänger zum Meister (Teil 1)
Verbunden: Eine andere Architektur von Dex von ArtexSwap
ArtexSwap ist eine dezentrale Börse, die Artela EVM++ und Aspect-Technologie verwendet, um MEV-Risiken und Rug Pull-Probleme zu lösen, die Transaktionssicherheit und -effizienz zu verbessern und sich für dezentrale Handelsszenarien eignet, die hohe Sicherheit und Flexibilität erfordern. Seit der Geburt von Ethereum ist es die technologische Heimat digitaler Währungen, globaler Zahlungen und Anwendungen. DEX ist der Eckpfeiler der dezentralen Finanzen (DeFi). Schließlich kann man sagen, dass DeFi ohne DEX nur leeres Gerede ist. Als Plattform, die auf der Blockchain läuft, führt sie direkte Transaktionen zwischen Benutzern durch und wird nicht von Drittinstitutionen reguliert, was es ihr ermöglicht, fortschrittlichere Finanzprodukte zu erstellen. 1. Dex-Mainstream-Architektur Derzeit floriert DEX im Ethereum-Ökosystem. Es gibt viele verschiedene Designmuster für DEX, jedes davon…







